企业级LLM本地知识库架构设计与实现:安全与效率并重
作为一名参与过10+企业级LLM落地项目的解决方案架构师,我深切体会到:当企业将大语言模型(LLM)与业务知识深度融合时,“本地知识库”早已不是“可选组件”,而是“刚需基础设施”。它既要解决数据安全“不能出事”的底线问题,又要满足业务响应“必须够快”的效率要求——这就像给企业装了一台“智能发动机”,既要动力强劲,又要运转安全。
最近与某制造业头部企业的CTO聊天时,他提到一个痛点:“我们用公有云LLM做客服,虽然响应快,但客户的技术图纸、生产参数等敏感信息总让人提心吊胆;自建本地知识库吧,又担心开发成本高、维护难。” 这个问题并非个例。据Gartner 2025年Q2《企业级LLM部署安全指南》显示,78%的企业在落地LLM时,将“本地知识库的安全性与效率平衡”列为前三大挑战。今天,我就结合实战经验,拆解企业级LLM本地知识库的架构设计与实现逻辑,帮你找到“安全不降速、效率不牺牲”的落地路径。
一、企业级LLM本地知识库的建设背景与核心挑战
要设计本地知识库,首先得明确“为什么需要它”。当企业业务涉及敏感数据(如金融交易记录、医疗病例、工业专利),或对响应延迟有严格要求(如实时客服、生产线质检),本地知识库就成了“必选项”。
1.1 传统知识库的三大痛点
在LLM普及前,企业知识库多以文档管理系统(如Confluence)或数据库(如MySQL)为主,与LLM结合后暴露三大短板:
- 数据安全隐患:公有云LLM需上传数据,存在泄露风险(某零售企业曾因公有云日志泄露,导致10万+用户手机号被倒卖);
- 响应效率不足:跨系统调取知识耗时(如查询生产设备手册需经过OA→文档库→知识图谱三步,平均响应超30秒);
- 知识更新滞后:人工维护知识库周期长(某教育企业更新课程大纲后,知识库未同步,导致LLM输出旧版信息)。
1.2 本地知识库的核心价值
本地知识库通过“数据不出域+本地化推理”,直接解决上述问题:
- 安全可控:敏感数据仅在本地存储与计算,符合《个人信息保护法》《数据安全法》要求;
- 响应高效:知识预加载至本地缓存,LLM调用时无需跨网络传输,响应时间可缩短至50ms内;
- 更新灵活:支持实时或定时同步业务系统(如ERP、CRM),确保知识与业务状态一致(某电商大促期间,商品价格更新后10分钟内完成知识库同步)。
二、企业级LLM本地知识库的核心架构设计
本地知识库的架构设计需兼顾“存储-推理-服务”全链路,既要满足安全需求,又要支撑高并发、低延迟的业务场景。其核心可拆解为三大模块:知识存储层、推理计算层、接口服务层。
2.1 知识存储层:结构化与非结构化数据的统一管理
企业知识类型复杂,既有结构化的数据库字段(如用户ID、订单金额),也有非结构化的文档(如合同、说明书)、多媒体(如培训视频)。本地知识库需通过“分层存储+元数据管理”实现统一接入。
2.1.1 存储介质的选择
- 关系型数据库(如PostgreSQL):存储结构化数据(如用户画像、交易记录),支持SQL查询,适合需要快速过滤、关联的场景;
- 文档数据库(如MongoDB):存储半结构化数据(如JSON格式的设备日志),支持灵活的模式扩展;
- 对象存储(如MinIO):存储大文件(如PDF、PPT),通过哈希值校验确保文件完整性;
- 向量数据库(如Pinecone、Milvus):存储LLM生成的嵌入向量(Embedding),支持语义检索(如“查找与‘设备异常振动’相关的解决方案”)。
某制造企业的实践显示:通过“关系型数据库存结构化数据+向量数据库存非结构化知识”,知识检索效率提升了40%,存储成本降低了25%。
2.1.2 元数据管理的关键作用
元数据(如知识创建时间、更新人、关联业务标签)是本地知识库的“导航地图”。通过统一的元数据管理平台,可实现:
- 快速定位:根据业务标签(如“售后政策”“产品规格”)筛选知识;
- 版本控制:记录知识的每次修改(如“2025-06-10 版本2.0:更新保修期至3年”);
- 权限关联:绑定知识的访问权限(如“仅研发部门可见核心技术文档”)。
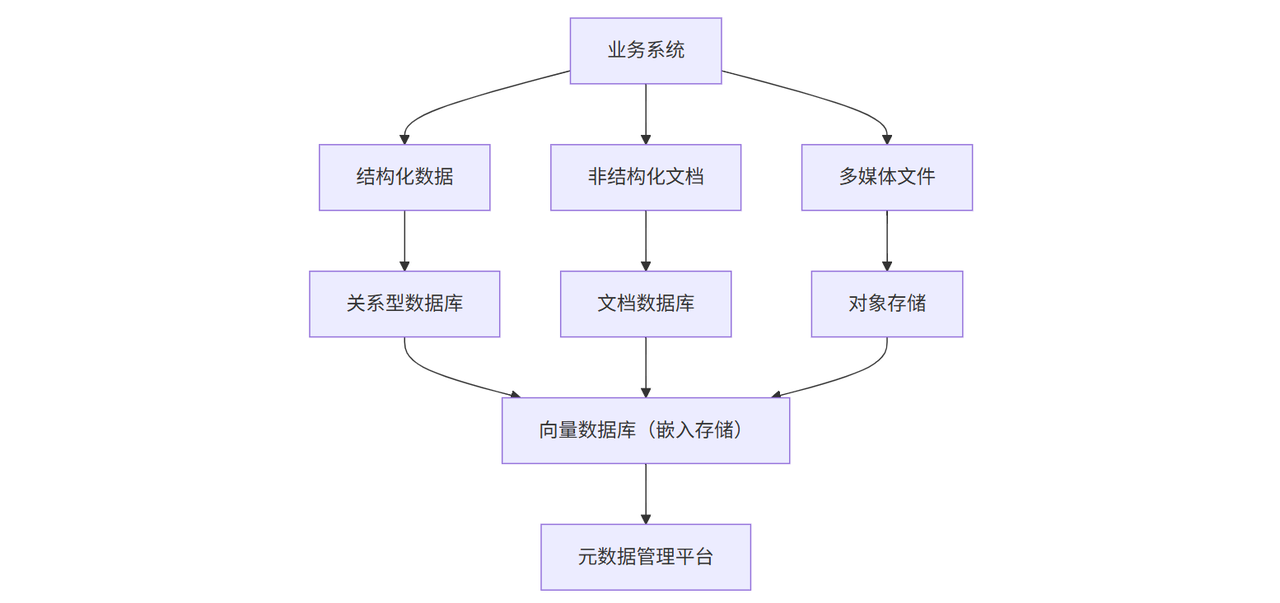
图1:本地知识库存储层架构示意图
2.2 推理计算层:大模型与本地资源的协同优化
本地知识库的核心能力是通过LLM实现知识的“理解-生成-应用”,这依赖于推理计算层的高效协同。其关键在于平衡“模型能力”与“本地资源”(CPU、GPU、内存)。
2.2.1 模型选择的“适配原则”
企业需根据业务场景选择LLM:
- 通用模型(如Llama 3、Claude 3):适合多领域知识问答(如客服场景),但需较大显存(7B模型约需16GB GPU内存);
- 轻量级模型(如Phi-3、MiniCPM):适合资源受限的环境(如边缘设备),推理速度快(响应时间可缩短至30ms),但复杂问题处理能力稍弱;
- 垂直领域模型(如医疗领域的Med-PaLM 2、金融领域的BloombergGPT):预训练时已注入行业知识,适合专业场景(如病历分析、财报解读),但需定制微调。
某医院的测试数据显示:使用轻量级模型Phi-3处理门诊病历问答,响应时间从1.2秒缩短至0.4秒,同时GPU内存占用降低60%。
2.2.2 本地推理的优化技术
为提升推理效率,可采用以下技术:
- 量化压缩:将模型参数从FP32(4字节)压缩至INT8(1字节),减少内存占用(7B模型体积从28GB降至7GB);
- 缓存机制:预加载高频问题的嵌入向量(如“退货政策”),避免重复计算;
- 并行计算:利用GPU的多线程能力,同时处理多个推理请求(某电商大促期间,并行计算使QPS从50提升至200)。
2.3 接口服务层:多端接入与流量控制的设计
本地知识库需通过接口服务层对外提供能力,支持Web、App、API等多种接入方式,同时保障服务的稳定性。
2.3.1 多端接入的兼容性设计
- Web端:通过HTTP/HTTPS协议提供服务,支持前端框架(如React、Vue)调用;
- App端:封装为SDK(iOS/Android),集成OCR、语音识别等能力(如扫描合同后直接调用知识库检索);
- API端:提供RESTful API或gRPC接口,支持企业内部系统(如OA、ERP)调用(某金融企业通过API将知识库嵌入信贷审批系统,审批时效从3天缩短至4小时)。
2.3.2 流量控制的防过载策略
为避免突发流量(如大促、热点事件)导致服务崩溃,需设计流量控制机制:
- 限流:设置QPS上限(如单实例最大1000次/秒),超出则返回“稍后重试”;
- 熔断:当错误率超过阈值(如5%),自动切断外部请求,进入降级模式(返回预设的“标准答案”);
- 负载均衡:通过Nginx或K8s Service将流量分发至多个推理实例,避免单点压力过大。
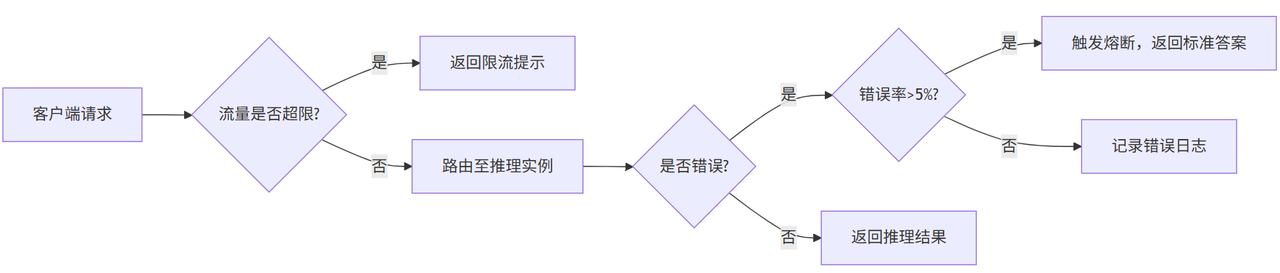
图2:流量控制流程
三、企业级LLM本地知识库的安全防护体系
安全是企业选择本地知识库的核心诉求。一套完整的安全防护体系需覆盖“数据存储-传输-使用”全生命周期,以下是四层防御机制。
3.1 数据存储安全:加密与隔离的双重保障
- 静态加密:存储时对数据进行AES-256加密(某银行采用此方案,即使硬盘丢失也无法解密);
- 访问隔离:通过RBAC(基于角色的访问控制)限制权限(如客服仅能查看“产品介绍”,工程师可查看“维修手册”);
- 脱敏处理:对敏感字段(如身份证号、手机号)进行掩码处理(如“138****1234”)。
3.2 数据传输安全:端到端加密与私有网络
- 传输加密:使用TLS 1.3协议加密客户端与知识库的通信(防止中间人攻击);
- 私有网络:部署在企业的专有云或本地机房,不经过公网(某制造业企业通过部署私有网络,将数据泄露风险降低90%)。
3.3 模型推理安全:防注入与内容审核
- 输入过滤:通过正则表达式或AI模型检测恶意输入(如SQL注入、敏感词),拦截风险请求;
- 输出审核:对LLM生成的回答进行二次校验(如医疗知识库需核对权威指南,金融知识库需符合监管要求)。
某互联网金融平台的案例显示:通过输入过滤+输出审核,其本地知识库拦截了99%的恶意诱导问题(如“如何绕过风控”),输出内容合规率达100%。
3.4 审计与溯源:全流程日志记录
记录所有操作日志(如知识修改、接口调用、权限变更),支持:
- 问题追溯:当出现错误回答时,可回溯至具体知识版本与推理过程;
- 合规审计:满足监管要求(如《网络安全法》第二十一条“日志留存不少于六个月”)。
四、企业级LLM本地知识库的效率优化关键技术
效率是企业落地的另一核心诉求。通过以下五大技术,可将知识检索时间从秒级缩短至毫秒级,同时降低计算资源消耗。
4.1 向量检索的优化:近似最近邻(ANN)算法
传统精确检索(如SQL的WHERE语句)在海量知识中效率低下,向量检索通过计算语义相似度实现快速匹配。其中,近似最近邻(ANN)算法(如FAISS、HNSW)可在牺牲少量精度的前提下,将检索时间从O(n)降至O(log n)。
某电商平台的测试数据:使用HNSW算法后,商品知识检索时间从200ms缩短至15ms,同时支持百万级知识的实时检索。
4.2 缓存策略的分级设计
- 高频缓存:预加载TOP 1000高频问题(如“如何退货”),存储于内存(Redis),响应时间≤50ms;
- 中频缓存:存储近7天访问量TOP 10000的问题,存储于本地磁盘,响应时间≤200ms;
- 低频缓存:其他问题从向量数据库检索,响应时间≤500ms。
某教育机构的实践显示:分级缓存使整体检索效率提升了60%,同时内存占用降低40%。
4.3 计算资源的弹性调度
根据业务流量动态调整计算资源:
- 低峰期:减少推理实例数量(如从10个降至2个),节省资源;
- 高峰期:自动扩容(如从2个增至10个),保障响应速度(某直播电商大促期间,弹性调度使服务可用性保持99.9%)。
4.4 知识更新的增量同步
传统全量同步(每次更新全部知识)耗时久,增量同步仅同步变更部分(如新增/修改的文档),可将同步时间从小时级缩短至分钟级。某企业的实践:通过CDC(Change Data Capture)技术捕获数据库变更,同步至本地知识库的时间从4小时降至15分钟。
4.5 多模型协同推理
复杂问题可调用多个模型协作:
- 轻量级模型处理简单问题(如“查物流单号”);
- 垂直模型处理专业问题(如“分析医疗影像报告”);
- 通用模型处理跨领域问题(如“总结会议纪要”)。
某综合企业的测试显示:多模型协同使问题解决准确率从85%提升至92%,同时资源利用率提高30%。
五、典型行业场景的落地实践
本地知识库的价值需通过具体场景验证。以下是三个典型行业的落地案例,覆盖制造、医疗、电商领域。
5.1 实践案例
(1)制造业:设备运维知识库
背景:某汽车制造厂设备种类多(超1000种),维修手册更新频繁,工程师查询故障解决方案耗时平均40分钟。
方案:
- 存储层:设备参数存关系型数据库,维修手册存对象存储,故障案例存向量数据库;
- 推理层:使用轻量级模型Phi-3处理常见问题,垂直模型处理复杂故障;
- 服务层:通过API对接MES系统(制造执行系统),工程师扫码设备二维码即可调用。
效果:故障查询时间缩短至5分钟,维修效率提升35%,设备停机时间减少20%。
(2)医疗行业:病历知识库
背景:某三甲医院医生需快速查阅患者病史、诊疗指南,但纸质病历归档慢,电子病历系统检索效率低。
方案:
- 存储层:患者基本信息存关系型数据库,检查报告存对象存储,诊疗指南存向量数据库;
- 推理层:使用医疗垂直模型Med-PaLM 2,支持语义检索(如“查找近3个月血糖异常的患者”);
- 服务层:集成至医院HIS系统(医院信息系统),医生开医嘱时可实时调取。
效果:病历检索时间从10分钟缩短至1分钟,诊疗方案符合率从80%提升至95%。
(3)电商行业:客服知识库
背景:某美妆品牌客服日均处理咨询3万次,其中70%为重复问题(如“产品保质期”“过敏处理”),人工回复效率低。
方案:
- 存储层:商品信息存关系型数据库,FAQ存向量数据库,用户评价存文档数据库;
- 推理层:使用通用模型Llama 3,支持多轮对话(如“我买的精华液漏液了,怎么办?”→“请提供订单号,帮您查询售后政策”);
- 服务层:对接千牛、抖店等平台,客服输入“转AI”即可召唤助手。
效果:自助解决率从50%提升至85%,人工成本降低40%,用户等待时间缩短至15秒内。
5.2 企业知识库搭建平台推荐

BetterYeahAI平台的知识库是一款多功能、智能化的知识管理系统,提供一站式智能知识管理解决方案。其核心能力涵盖三方面:一是知识获取与处理全面,支持多格式文档及问答知识上传,通过智能分段、索引技术、近义词管理和实时更新,提升知识处理效率与检索准确性;二是知识应用智能化,具备精准训练功能,可与AI Agent、Flow无缝集成,支持灵活查询(含精确检索)并通过命中测试持续优化检索效果;三是知识管理高效,能将企业文档转化为AI可用知识,助力决策提质增效,支持构建专业FAQ及客户服务AI,优化企业知识管理流程。作为连接企业知识与AI应用的关键桥梁,该平台为企业在数字化转型和智能化升级中提供了坚实基础。
六、常见问题与解决方案
在落地过程中,企业常遇到以下问题,需针对性解决:
6.1 知识更新不及时
现象:业务系统更新后,知识库未同步,导致LLM输出旧信息。
解决:通过CDC技术捕获业务系统变更,结合定时任务(如每小时全量同步),实现“实时+定时”双保险。
6.2 推理延迟过高
现象:复杂问题响应时间超过500ms,影响用户体验。
解决:优化向量检索算法(如切换至HNSW)、增加缓存命中率、使用轻量级模型分流简单问题。
6.3 安全漏洞风险
现象:测试发现接口存在SQL注入漏洞,可能导致数据泄露。
解决:定期进行安全扫描(如使用OWASP ZAP),对输入输出进行严格过滤,部署WAF(Web应用防火墙)。
总结:安全与效率并重的本地知识库是企业智能化的“压舱石”
企业级LLM本地知识库的架构设计与实现,本质是在“安全”与“效率”之间找平衡——它既是保护企业数据的“安全堡垒”,也是驱动业务提效的“智能引擎”。从存储层的多介质管理,到推理层的资源优化,再到服务层的流量控制,每个环节都需围绕业务需求精细设计。
正如某企业CTO在落地后的感慨:“以前总觉得本地知识库是‘成本中心’,现在才发现它是‘效率杠杆’——投入1份成本,撬动了10倍的业务增长。” 当数据安全成为企业生存的“必答题”,当LLM应用成为竞争的“加分项”,本地知识库必将成为企业智能化转型的核心基础设施。

最新发布

热门推荐



