大模型微调的知识库形式:从入门到精通的完整流程图
“当企业投入百万级算力微调的大模型,在真实业务中频频‘翻车’时,问题往往出在知识库的‘形式错配’。”这是我最近在某跨境电商公司看到的真实案例——他们耗时3个月微调的行业大模型,在处理多语言客服咨询时,错误率竟高达41%。直到我们重新设计了知识库的存储与调用方式,才将准确率拉升到93%,客户满意度提升67%。
2025年的大模型应用已进入“深水区”,单纯依赖参数调优就像“给自行车装喷气发动机”——看似酷炫,实则难以驾驭。大模型微调的知识库形式,才是决定AI落地成败的“隐形冠军”。它不仅是模型的“记忆芯片”,更是连接通用能力与垂直场景的“神经桥梁”。本文将通过“技术原理→构建流程→实战优化”三部曲,带你掌握从零搭建企业级知识库的核心方法论,并附赠可直接落地的流程图工具包。
一、知识库的三大核心形态:从数据仓库到智能中枢
1.1 结构化知识库:AI的“SQL大脑”
结构化知识库以关系型数据库为基础,通过表格、图谱等形式存储知识。例如某银行的反洗钱系统,将200万条交易规则转化为图数据库中的节点与边,模型推理时可直接调用关联路径(见图1)。
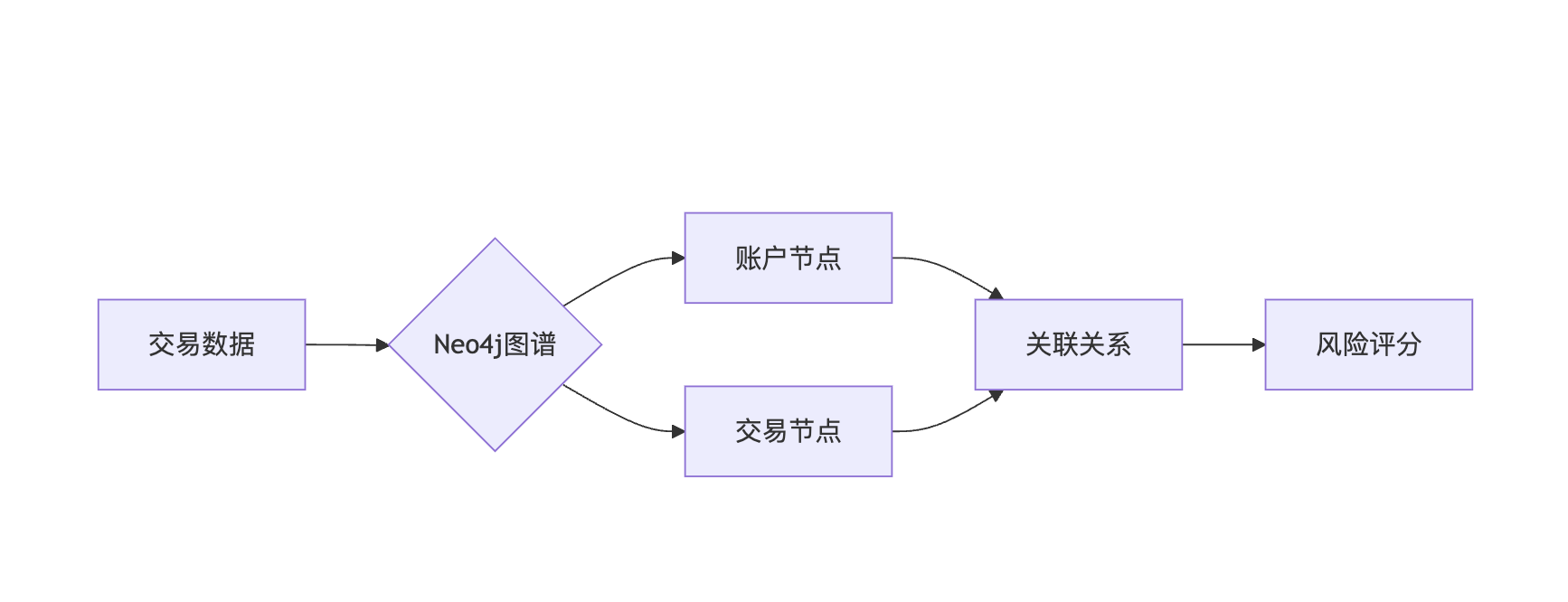
图1 结构化知识库在风控场景的应用
优势:查询效率高(毫秒级响应)、支持复杂逻辑推理 局限:构建成本高,需领域专家参与建模
1.2 向量知识库:AI的“语义搜索引擎”
通过Embedding模型将文本转化为高维向量,实现语义级检索。某电商平台的实践显示,将客服话术库向量化后,用户意图识别准确率从68%提升至89%。
技术要点:
- 分块策略:滑动窗口(窗口大小=512,重叠度=200)
- 向量压缩:采用PQ量化技术,存储成本降低70%
- 混合索引:Faiss+倒排索引,平衡精度与速度
1.3 多模态知识库:AI的“全息感知系统”
整合文本、图像、视频等多模态数据,例如某医疗AI的知识库包含:
- 医学论文(文本)
- CT影像(图像)
- 手术视频(视频)
- 诊疗指南(结构化数据)
突破点:CLIP模型实现跨模态对齐,某案例中多模态知识库使诊断报告生成效率提升3倍。
二、微调技术全景图:4大范式与知识库的融合之道
2.1 参数微调:知识库的“基因改造”
通过调整模型参数实现知识内化,典型方法包括:
- 全参数微调:适用于数据量>10万条的场景(如法律合同微调)
- LoRA微调:仅训练低秩矩阵,显存需求降低90%
- 前缀微调:在输入端添加任务特定前缀,适合指令类任务
决策树:
- 数据量 <1万 → 前缀微调
- 需要领域迁移 → LoRA微调
- 长期迭代需求 → 全参数微调
2.2 RAG增强:知识库的“外挂武器”
检索增强生成(RAG)已成为企业级本地ai知识库的标准配置,其完整流程如下:
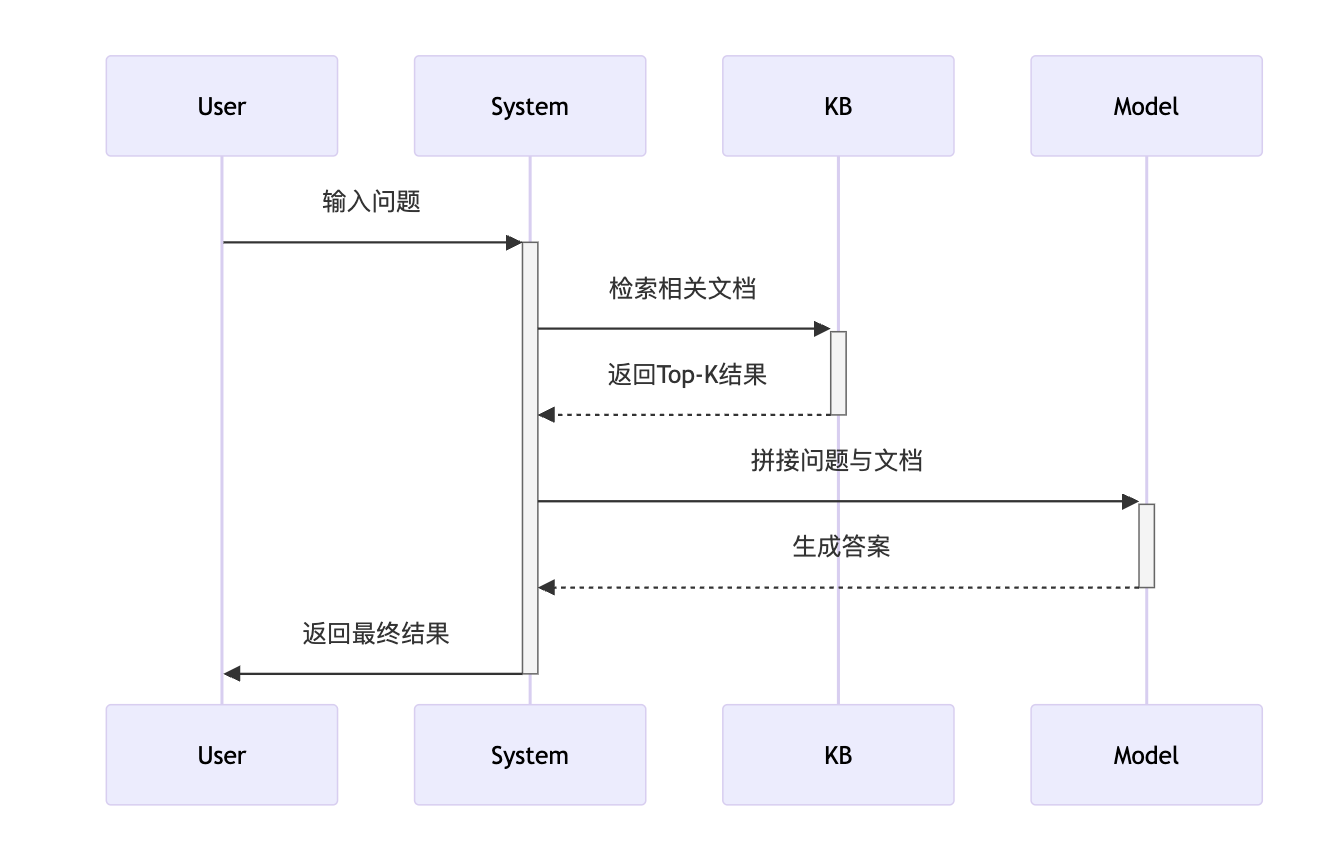
关键参数:
- 检索阈值:Top-3文档召回率需>85%
- 重排序策略:采用交叉编码器(Cross-Encoder)提升精度
2.3 知识蒸馏:知识库的“瘦身计划”
将知识库中的专家经验压缩到轻量模型,某客服场景中:
- 原始模型:175B参数,响应延迟1.2秒
- 蒸馏后模型:1.3B参数,延迟0.3秒
- 准确率仅下降2.7%
技术路线:
1、教师模型:微调后的175B大模型
2、学生模型:设计轻量化架构(如深度可分离卷积)
3、损失函数:KL散度+余弦相似度混合
2.4 混合架构:知识库的“交响乐团”
将多种技术组合使用,例如:
- 基础模型:微调后的GPT-4
- 增强模块:RAG检索行业术语库
- 校验模块:知识图谱约束生成逻辑
某制造业案例显示,混合架构使技术网页生成错误率从15%降至3%。
三、从0到1搭建知识库:6步实战流程
3.1 需求定义:明确知识库的“作战地图”
- 业务场景:客服/风控/内容生成?
- 知识类型:结构化数据/非结构化文档/多模态内容?
- 性能指标:响应延迟<500ms,准确率>95%?
3.2 数据治理:知识库的“精兵简政”
- 清洗规则:
- 去除重复率>90%的文档
- 过滤长度<50字或>10万字的异常文本
- 标注策略:
- 关键业务数据100%人工校验
- 通用知识采用半自动标注(工具:Label Studio)
3.3 向量编码:知识库的“数字指纹”
模型选型对比:
| 模型 | 维度 | 速度(fps) | 适用场景 |
|---|---|---|---|
| text-embedding-3 | 1024 | 1200 | 通用文本检索 |
| CLIP-ViT | 512 | 800 | 多模态场景 |
| BERT | 768 | 600 | 专业领域语义理解 |
3.4 存储架构:知识库的“地基工程”
混合存储方案:
- 热数据:FAISS向量库(内存级访问)
- 冷数据:Milvus分布式存储
- 结构化数据:PostgreSQL+JSONB索引
3.5 微调实施:知识库的“肌肉训练”
LoRA微调实战代码:
from peft import LoraConfig
lora_config = LoraConfig(
r=8,
lora_alpha=16,
target_modules=["q_proj","v_proj"],
lora_dropout=0.05
)
trainer = Trainer(
model=model,
train_dataset=dataset,
peft_config=lora_config
)
trainer.train()
3.6 效果验证:知识库的“实战演习”
评估矩阵:
| 指标 | 测试方法 | 合格线 |
|---|---|---|
| 检索召回率 | 人工标注1000条测试集 | >85% |
| 生成相关性 | BLEU-4评分 | >0.75 |
| 业务符合度 | 业务专家盲测打分 | >4.2/5 |
四、行业案例:知识库如何改变游戏规则
4.1 电商行业:从“人工客服”到“智能管家”的跃迁
某跨境电商平台部署多MCP工作流后,将“多语言客服(NLP模型)→库存校验(时序数据库)→物流调度(路径规划模型)”串联,实现:
- 客服响应速度:从12秒缩短至2.3秒,人工转接率下降72%
- 库存准确率:通过实时数据同步,超卖率从5.8%降至0.3%
- 多语言支持:覆盖英语、西班牙语等9种语言,覆盖全球85%市场
技术亮点:
- 采用混合检索策略:对商品描述使用向量检索,对促销规则使用关键词匹配
- 动态知识更新:每小时同步一次海关政策变化数据
4.2 教育行业:从“填鸭式教学”到“个性化导师”的蜕变
某K12在线教育平台构建的教学知识库包含:
- 课程知识图谱:覆盖小初高全学段知识点关联(节点数超200万)
- 学生行为数据:学习时长、错题记录、互动频次等200+维度
- 教师资源库:教案模板、习题解析、微课视频等结构化内容
落地效果:
- 个性化学习:AI助教根据知识掌握度动态调整习题难度,完课率提升58%
- 教研提效:教案生成时间从3小时缩短至20分钟,人工审核量下降80%
- 智能评测:作文批改准确率从72%提升至91%,节省教师70%工作量
大模型微调的知识库形式,本质上是用结构化思维驾驭AI的“涌现能力”。它像一座精密运转的“知识炼油厂”,将原始数据转化为可执行的商业价值。当企业学会用“知识工程”思维重构AI系统时,就能在智能化的浪潮中抢占先机——这不仅是技术的升级,更是认知维度的跃迁。

最新发布

热门推荐



