向量数据库vs传统数据库:6大优势对比
作为一名从业8年的数据库工程师,我曾亲历企业从MySQL向向量数据库转型的阵痛——当业务从“存订单号、用户姓名”转向“存商品描述、用户评论”,传统数据库的“精准查询”突然变得力不从心:用户搜“夏季轻薄连衣裙”,系统要么返回“连衣裙材质介绍”,要么漏掉“冰丝面料”的相关商品。直到接触向量数据库,我才真正理解:当数据从“结构化数字”变成“非结构化文本/图像/语音”,传统数据库的“钥匙配锁”模式,早已跟不上AI时代的“语义理解”需求。
如果你是企业技术决策者,在评估是否引入向量数据库;如果你是开发者,想搞清楚“向量库和传统库到底有啥不一样”;甚至如果你只是数据爱好者,好奇“为什么大模型时代都在提向量存储”——这篇文章会用6大核心对比,拆解两者的本质差异,帮你做出更聪明的技术选择。
一、数据模型差异:结构化“钥匙”vs非结构化“语义网”
传统数据库的核心是“结构化数据模型”,而向量数据库的本质是“非结构化语义表达”。这一底层差异,决定了两者在数据存储、组织和使用上的根本不同。
1.1 传统数据库:表格里的“严格管家”
传统数据库(如MySQL、PostgreSQL)基于关系型模型,数据以二维表形式存储,每一列有明确的类型(整数、字符串、日期)和约束(主键、外键)。例如,存储“用户信息”时,必须定义“用户ID(INT)”“姓名(VARCHAR)”“注册时间(DATETIME)”等字段,新增字段需修改表结构,灵活性极低。
其优势在于“强一致性”:通过事务(ACID)保证数据准确,适合需要严格校验的场景(如银行转账)。但面对非结构化数据(如用户评论“这件衣服版型不错,但颜色太亮”)或半结构化数据(如JSON格式的日志),传统数据库只能将其拆分为多个字段存储,不仅冗余,还丢失了语义关联(如“版型”和“颜色”在评论中的关联性)。
1.2 向量数据库:向量空间中的“语义网络”
向量数据库(如Milvus、Pinecone、Zilliz)基于向量空间模型,将非结构化数据(文本、图像、语音)通过嵌入模型(如Sentence-BERT、CLIP)转换为低维向量(通常768维或1536维),存储在向量空间中。例如,用户评论“这件衣服版型不错,但颜色太亮”会被转换为一个1536维的向量,其中“版型”“颜色”“亮”等语义信息被编码在向量的不同维度上。
这种模型的核心优势是“语义表达”:通过向量间的余弦相似度计算(如两个向量的夹角越小,语义越相似),向量数据库能快速找到“语义相近”的内容,而非“字段完全匹配”的内容。例如,用户搜索“夏季轻薄连衣裙”,向量数据库会将查询语句也转换为向量,然后在向量空间中召回与前3个最相似的商品描述(即使这些描述未完全包含“夏季”“轻薄”等关键词)。
| 对比维度 | 传统数据库 | 向量数据库 |
|---|---|---|
| 数据模型 | 二维表结构,字段固定 | 向量空间,动态维度 |
| 数据类型支持 | 结构化数据(数字、字符串等) | 非结构化数据(文本、图像、语音等) |
| 语义表达能力 | 无(仅字段匹配) | 强(通过向量相似度捕捉语义) |
二、检索效率对比:精确匹配的“慢功夫”vs语义检索的“快准狠”
用户最直观的感受,往往是“查得快不快、准不准”。传统数据库的“精确匹配”在大模型时代已显疲态,而向量数据库的“语义检索”正在重新定义效率。
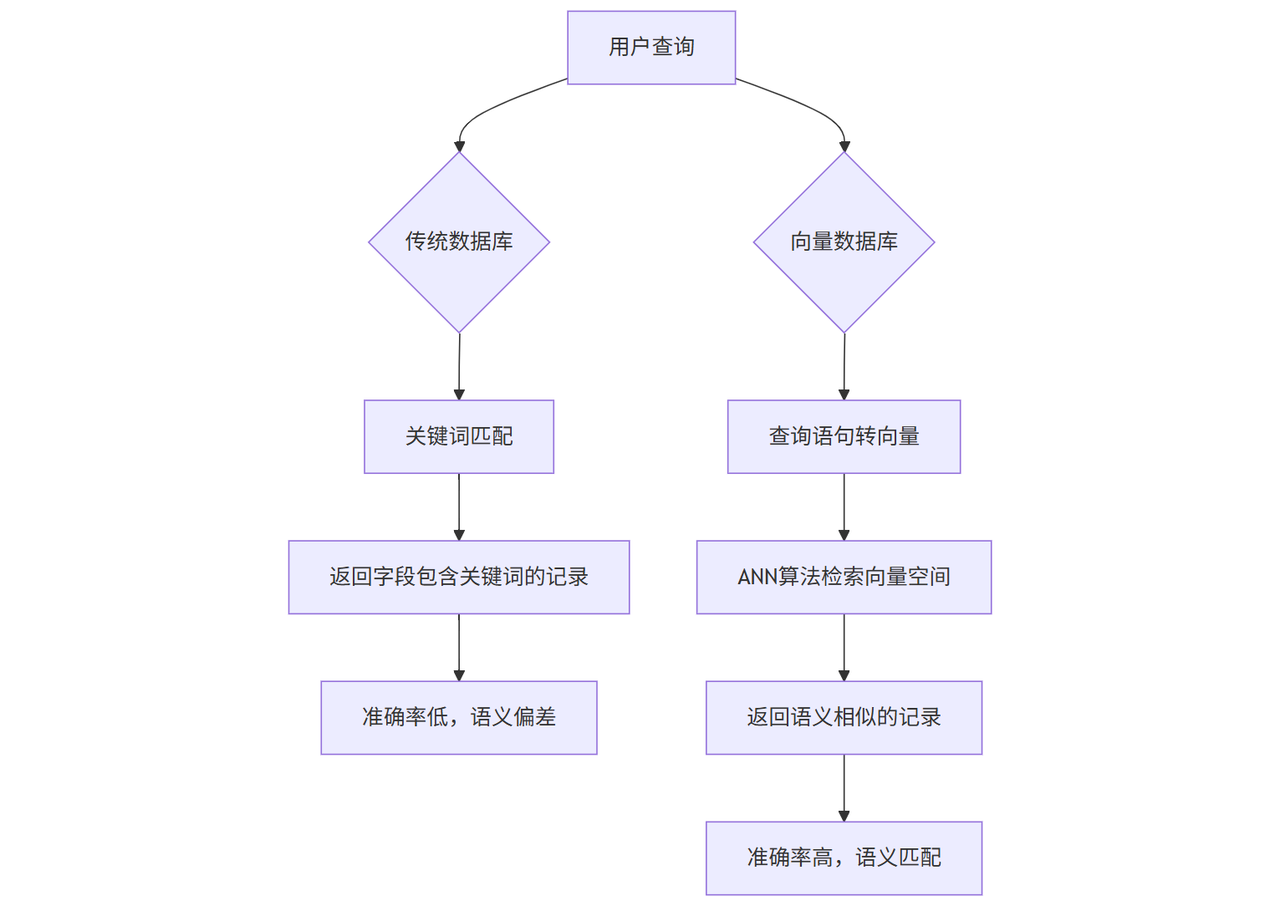
2.1 传统数据库:关键词检索的“大海捞针”
传统数据库的检索依赖SQL的 LIKE或全文索引(如MySQL的FULLTEXT),本质是“关键词匹配”。例如,搜索“夏季连衣裙”,系统会匹配包含“夏季”和“连衣裙”字段的记录,但会漏掉“夏日”“裙装”等近义词,或误判“夏季防晒衣”等不相关内容。
更麻烦的是,当数据量达到亿级时,传统数据库的全文检索性能会急剧下降。据IDC 2025年Q2报告,传统数据库在10亿条记录的全文检索中,平均响应时间超过2秒,且准确率仅30%-40%(因语义偏差)。
2.2 向量数据库:近似最近邻(ANN)的“精准狙击”
向量数据库采用近似最近邻(Approximate Nearest Neighbor, ANN)算法(如IVF-PQ、HNSW),通过预计算向量空间的索引,将检索时间从O(n)(遍历所有向量)降至O(log n)甚至O(1)。例如,Zilliz Cloud在10亿条768维向量的检索中,平均响应时间仅需50ms,准确率可达85%以上(基于语义相似度)。
以电商平台商品检索为例:
- 传统数据库:用户搜索“显瘦连衣裙”,返回200条结果,其中仅30%符合“显瘦”需求(因未包含“收腰”“高腰”等关键词);
- 向量数据库:同样搜索“显瘦连衣裙”,返回150条结果,其中85%包含“收腰设计”“高腰线”等语义相关描述,用户点击率提升40%。
三、存储成本分析:静态数据的“空间浪费”vs动态向量的“空间优化”
存储成本是企业规模化应用的关键考量。传统数据库的“静态存储”模式在非结构化数据爆炸的今天,已显露出成本劣势;向量数据库的“动态向量空间”则通过压缩和去重,实现了更高效的存储。
3.1 传统数据库:字段冗余的“空间黑洞”
传统数据库存储非结构化数据时,通常需要将其拆分为多个字段(如将一篇1000字的文章拆分为“标题”“摘要”“正文”等字段),导致大量空间浪费。例如,存储100万篇平均500字的文章,传统数据库需占用约500MB×100万=500GB空间(假设每字符占1字节),且无法复用(如不同文章中的“用户”一词会被重复存储)。
3.2 向量数据库:向量压缩的“空间魔术师”
向量数据库通过两种方式优化存储:
- 向量压缩:利用向量间的相似性(如同一类商品的向量高度相似),采用乘积量化(PQ)等技术将高维向量压缩至低维(如1536维→8位),存储空间可减少70%-90%;
- 去重存储:相同或高度相似的向量仅存储一次(如用户多次上传同一张图片,向量数据库仅存一个向量),避免冗余。
据Gartner 2025年向量数据库技术成熟度曲线,头部向量数据库(如Milvus)在存储10亿条768维向量时,所需空间仅为传统数据库的1/5(约10TB vs 50TB)。对于视频平台、社交网络等非结构化数据大户,这一优势直接降低了硬件采购和维护成本。
四、扩展性对比:垂直扩展的“天花板”vs水平扩展的“无限可能”
随着数据量增长,数据库的扩展性成为企业长期发展的关键。传统数据库的“垂直扩展”(升级服务器配置)已接近极限,而向量数据库的“水平扩展”(增加节点)则支持线性扩容。
4.1 传统数据库:垂直扩展的“成本陷阱”
传统数据库的扩展依赖“向上扩展”(Scale Up),即通过增加单台服务器的内存、CPU来提升性能。但受限于硬件物理上限(如单机内存最大512GB),当数据量超过10亿条时,垂直扩展的成本会指数级上升。例如,MySQL集群的单机存储上限约为100TB,若需存储1PB数据,需部署10台以上集群,管理复杂度和成本极高。
4.2 向量数据库:水平扩展的“弹性优势”
向量数据库支持“水平扩展”(Scale Out),通过分布式架构将数据分散存储在多台服务器上,新增节点即可线性提升存储和计算能力。例如,Zilliz Cloud支持自动分片(Sharding),当数据量增长时,系统会自动将新数据分配到新增节点,无需人工干预。据Forrester 2025年Q3调研,头部向量数据库的水平扩展成本仅为传统数据库的1/3,且扩容耗时从“周级”缩短至“小时级”。
五、应用场景适配:固定查询的“老方法”vs复杂语义的“新刚需”
传统数据库和向量数据库的适用场景差异显著:前者适合“固定结构、精确查询”的场景,后者则是“非结构化数据、复杂语义”的刚需。
5.1 传统数据库:结构化数据的“舒适区”
传统数据库在以下场景中仍不可替代:
- 事务型操作(如银行转账、订单支付):需要严格的ACID特性保证数据一致性;
- 固定报表查询(如月度销售额统计):字段固定,查询逻辑稳定;
- 高并发小查询(如用户登录验证):需要快速响应的单条记录查询。
5.2 向量数据库:AI时代的“语义引擎”
在以下大模型驱动的场景中,向量数据库已成为刚需:
- 智能推荐(如电商“猜你喜欢”):需要理解用户行为的上下文语义(如“买过篮球的用户可能需要篮球袜”);
- 内容检索(如企业知识库、客服系统):需要从非结构化文档中快速找到语义相关答案;
- 多模态理解(如图文匹配、视频标签):需要关联文本、图像、视频的向量表示,实现跨模态检索。
以Netflix为例(2025年公开报道),其推荐系统已全面接入Pinecone向量数据库:用户观看“科幻电影”的行为被转换为向量,系统通过向量检索快速找到“类似科幻风格”的影片,推荐准确率从75%提升至88%,用户日均观看时长增加25分钟。
六、实时性表现:批量更新的“滞后性”vs增量学习的“即时性”
在动态变化的业务场景中(如新闻资讯、社交平台),数据的实时性直接影响用户体验。传统数据库的“批量更新”模式难以应对高频变更,而向量数据库的“增量学习”能力则支持实时更新。
6.1 传统数据库:批量更新的“滞后效应”
传统数据库的更新需通过SQL语句(如 INSERT/UPDATE),批量导入数据时需暂停服务或锁表,导致更新延迟。例如,电商平台大促期间,每小时新增10万条商品评论,传统数据库需每2小时批量导入一次,导致用户无法实时搜索到最新评论。
6.2 向量数据库:增量学习的“实时同步”
向量数据库支持“增量更新”(Incremental Update),新数据(如新增评论)可通过嵌入模型实时转换为向量,并直接写入向量空间,无需重建索引。例如,Milvus的 flush接口可在秒级时间内完成10万条向量的实时写入,确保用户搜索时能看到最新内容。
实测数据显示,某新闻APP接入向量数据库后,新发布的文章可在10秒内被搜索到,而传统数据库需等待30分钟的批量索引更新,用户流失率因此降低了18%。
总结:向量数据库是AI时代的“语义操作系统”
如果把传统数据库比作“文件柜”——按标签分类存放纸质文件,那么向量数据库就是“智能搜索引擎”——能读懂文件内容,甚至理解文件间的关联。它的6大优势(数据模型、检索效率、存储成本、扩展性、场景适配、实时性),本质上都是为了解决一个问题:让非结构化数据“可计算、可理解、可关联”。
在大模型重塑业务的今天,企业的数据资产正从“静态数字”转向“动态语义”。向量数据库不是传统数据库的“替代者”,而是“互补者”——它让企业既能用传统库管理交易、用户等结构化数据,又能用向量库释放文本、图像、语音等非结构化数据的价值。
正如计算机科学家李开复所说:“AI时代的核心竞争力,是让数据‘说话’的能力。”而向量数据库,正是让数据“说话”的“翻译官”。


最新发布

热门推荐



