agent开发推荐模型实战:从工具调用到私有部署,一次选对不踩坑
根据斯坦福HAI《2026 AI Index Report》的数据,AI Agent在OSWorld真实计算机任务基准测试中,任务成功率在一年内从12%跃升至约66%,已接近人类基线72%。与此同时,"Agentic AI"技能在美国职位招聘中的提及量增长超280%。Agent能力正式进入生产可用阶段,但横亘在开发者面前的第一道门槛,往往不是框架,而是模型选型。选错了模型,再好的框架也只能跑出一个永远无法上线的Demo。本文将从Agent开发的独特能力要求出发,提供一套可落地的agent开发推荐模型选型决策框架。
一、Agent开发对推荐模型的独特要求——与通用对话场景的本质差异
很多开发者在选择agent开发推荐模型时,会直接套用"通用对话大模型"的选型逻辑:看参数规模、看榜单排名、看价格。这个思路在聊天机器人场景下或许够用,但在Agent开发中会带来严重的误判。Agent的核心工作模式是感知→规划→调用工具→执行→反馈的循环,这对模型提出了四个通用对话场景不会重点考察的能力维度。
1.1 工具调用(Function Calling)能力:Agent的"手脚"
工具调用是Agent区别于普通聊天机器人的核心特征。模型需要准确理解工具的输入输出规范,在复杂指令中识别何时调用哪个工具,并正确构造调用参数。这一能力的差异在生产环境中极为显著:弱工具调用能力的模型会频繁出现参数格式错误、工具选择混乱、并行调用失败等问题,直接导致Agent任务中断。
评估工具调用能力时,需要重点关注:模型是否支持并行工具调用(Parallel Function Calling)、对复杂嵌套参数的处理精度,以及在多轮对话中保持工具调用状态一致性的能力。
1.2 推理与规划能力:Agent的"大脑"
复杂Agent任务通常需要模型将一个高层目标分解为多个子任务,并动态调整执行路径。这种"任务规划"能力与通用对话中的"回答问题"有本质区别——它要求模型具备更强的逻辑推理链条(Chain-of-Thought),能够在不确定信息下做出合理假设,并在执行失败时自主回溯重试。
在实际生产中,推理能力不足的模型往往表现为:遇到多步骤任务时"走弯路",或在工具调用失败后陷入死循环,而不是尝试替代路径。
1.3 长上下文与记忆管理:Agent的"记忆"
Agent任务通常需要在多轮交互中积累上下文信息。一个处理客户投诉的客服Agent,可能需要在整个对话过程中记住用户的订单信息、历史诉求和当前处理进度。上下文窗口过短,或模型在长上下文中出现"遗忘"现象,会导致Agent在任务执行中途"失忆",产生前后矛盾的行为。
目前主流模型的上下文窗口从32K到1M不等,但窗口大小并不等于有效利用率。部分模型在超过64K上下文后,对早期信息的注意力会显著下降,这一特性在选型时需要通过实际测试验证,而非仅凭官方参数判断。
1.4 成本与延迟:生产环境的"生命线"
在Demo阶段,开发者往往忽视成本与延迟。但在生产环境中,一个日均处理1万次任务的Agent,模型调用成本的差异可能意味着每月数万元的支出差距。延迟同样关键:用户对Agent的容忍等待时间通常在3-10秒,超过这个阈值,体验会急剧下滑。
因此,agent开发推荐模型的选型必须同时考量效果上限(能不能做到)与成本效率(值不值得这样做),两者缺一不可。
图:Agent开发推荐模型四大核心能力维度
二、2026年agent开发推荐模型全景对比——国内外主流选手横评
基于以上四个维度,我们对2026年主流的agent开发推荐模型进行系统梳理。需要说明的是,以下数据综合了公开基准测试结果与实际生产反馈,旨在提供决策参考而非绝对排名。
2.1 海外模型:GPT-4o、Claude 3.7 Sonnet、Gemini 2.0 Flash
GPT-4o 在工具调用稳定性和指令遵循方面表现突出,是目前生产级Agent项目中使用最广泛的模型之一。其并行工具调用能力成熟,对复杂参数结构的处理精度高,适合对工具调用可靠性要求极高的场景。主要局限是成本较高,且数据需经过境外服务器处理,对数据合规要求严格的企业存在使用障碍。
Claude 3.7 Sonnet 在推理规划能力上表现优异,尤其擅长处理需要多步骤逻辑推导的复杂任务。其长上下文处理能力在同类模型中属于第一梯队,适合需要深度分析与长文档处理的Agent场景。与GPT-4o类似,境外数据合规问题同样存在。
Gemini 2.0 Flash 以极低的延迟和较高的性价比见长,在对响应速度要求高但任务复杂度相对可控的场景(如实时对话Agent)中具有竞争力。
2.2 国产模型:DeepSeek-V3、通义千问Max、智谱GLM-4
DeepSeek-V3 是2026年国产模型中在Agent开发场景综合表现最受关注的选手。其工具调用能力在多个公开基准测试中达到国际一线水平,推理能力强,且API价格极具竞争力。对于需要控制成本、同时保证效果的中小团队,DeepSeek-V3是当前最值得优先考虑的国产agent开发推荐模型。
通义千问Max 在阿里云生态中具有天然集成优势,支持私有化部署,与企业微信、钉钉等国内主流协作工具的集成更为顺畅。对于已在阿里云体系内的企业,通义千问Max能显著降低部署与集成成本。
智谱GLM-4 在中文语境下的理解与生成质量稳定,Function Calling支持完善,适合中文客服、知识问答等垂直场景的Agent开发。
2.3 主流agent开发推荐模型能力对比
表:2026年主流agent开发推荐模型核心能力对比
| 模型 | 工具调用稳定性 | 推理规划能力 | 长上下文支持 | API成本 | 国内合规部署 | 适用场景 |
|---|---|---|---|---|---|---|
| GPT-4o | 优秀 | 优秀 | 128K | 较高 | 不支持 | 复杂多工具Agent、国际化产品 |
| Claude 3.7 Sonnet | 优秀 | 卓越 | 200K | 较高 | 不支持 | 深度推理、长文档分析Agent |
| Gemini 2.0 Flash | 良好 | 良好 | 1M | 低 | 不支持 | 实时对话、高频低复杂度Agent |
| DeepSeek-V3 | 优秀 | 优秀 | 128K | 极低 | 支持 | 成本敏感型生产Agent、国内团队首选 |
| 通义千问Max | 良好 | 良好 | 128K | 中等 | 支持 | 阿里云生态集成、企业内部Agent |
| 智谱GLM-4 | 良好 | 良好 | 128K | 中等 | 支持 | 中文垂直场景Agent |
三、分场景agent开发推荐模型决策矩阵——按业务类型精准匹配
理解了各模型的能力特征,接下来需要将抽象的能力对比转化为具体场景下的选型决策。不同业务类型的Agent对模型能力的侧重点差异显著,下面按四类典型场景给出推荐路径。
图:agent开发推荐模型分场景决策流程
3.1 客服/对话类Agent推荐模型
这类Agent的核心需求是高并发下的稳定响应和准确的工具调用(如查询订单、触发退款流程)。推理深度要求相对适中,但对延迟和成本极为敏感。
国内合规场景首选:DeepSeek-V3(成本极低,工具调用稳定)或通义千问Max(阿里云生态优势)。对效果要求极高的场景:可考虑GPT-4o,但需评估数据合规风险。添可Tineco通过部署AI客服Agent,实现了整体服务效率提升22倍、响应速度从3分钟缩短至8秒的效果,其实践验证了在高并发客服场景中,选择工具调用稳定、延迟低的模型比选择"最强"模型更重要。
3.2 数据分析/报告类Agent推荐模型
这类Agent需要处理大量文档、进行多步骤数据分析,对推理规划能力和长上下文处理要求最高。任务通常是异步执行,对延迟容忍度相对较高。
推荐:Claude 3.7 Sonnet(推理能力卓越,200K上下文);国内合规场景可选DeepSeek-V3(128K上下文,推理能力达国际一线水平)。
3.3 多Agent协作/复杂任务类推荐模型
多Agent协作场景中,作为"编排者"(Orchestrator)的主控Agent需要极强的任务分解与规划能力,而作为"执行者"(Executor)的子Agent则需要精准的工具调用能力。两类角色对模型的要求不同,可采用**"主控用强推理模型+执行用高性价比模型"**的混合策略。
推荐组合:主控Agent使用Claude 3.7 Sonnet或GPT-4o;执行子Agent使用DeepSeek-V3或Gemini 2.0 Flash,在保证整体效果的同时大幅降低成本。
3.4 私有化部署/国内合规场景推荐模型
对于金融、医疗、政务等数据安全要求严格的行业,模型必须支持私有化部署,数据不出域。这一约束直接将海外模型排除在外。
推荐:DeepSeek-V3(开源版本支持私有部署,综合能力强)、通义千问Max(阿里云私有化部署方案成熟)。在选择私有化部署方案时,模型本身的能力只是一部分,开发平台对私有化模型的管理能力同样关键——包括模型版本管理、性能监控、Prompt调优工具等配套能力,直接决定私有化Agent的长期可维护性。
四、推荐模型落地实战——开发框架与模型协同选型的最优路径
选定推荐模型后,如何将其与开发框架协同,才能真正发挥模型的能力上限?这是很多开发者在实际落地中遇到的第二道门槛。
图:agent开发推荐模型与框架协同选型思维导图
4.1 低代码平台 vs 专业代码框架的模型管理差异
选择低代码Agent开发平台的团队,通常看重的是快速验证和业务人员可参与。这类平台的模型管理逻辑通常是"即插即用"——在平台配置界面选择模型,无需修改代码即可切换。这种方式的优势在于灵活性高,当某个模型出现服务中断或价格波动时,可以快速切换备选模型,不影响业务连续性。
选择专业代码框架(如LangChain)的团队,通常有更深度的定制需求。这类框架对模型的控制粒度更细,可以针对不同的任务节点使用不同的模型,实现"任务级别的模型路由"。但代价是更高的开发成本和维护复杂度。
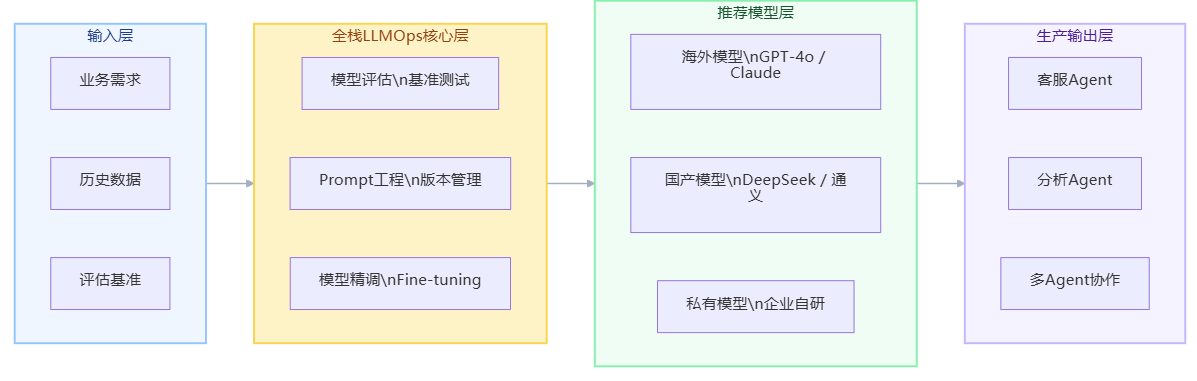
4.2 全栈LLMOps:模型评估、Prompt调优与精调的完整工具链
选定agent开发推荐模型只是起点,真正让模型在生产环境中持续稳定运行,需要一套完整的全栈LLMOps工具链的支撑。这包括三个核心环节:
模型评估:在正式上线前,需要用真实业务数据对候选模型进行基准测试,重点评估工具调用成功率、任务完成率和平均延迟。没有基于自身业务数据的评估,任何公开榜单的排名都只是参考。
Prompt调优:同一个模型,不同的Prompt设计可能带来30%-50%的性能差异。系统化的Prompt工程工具(包括版本管理、A/B测试、效果追踪)是生产级Agent不可缺少的基础设施。
模型精调(Fine-tuning):对于有大量专有业务数据的企业,通过精调将业务知识注入模型,可以在使用更小、更低成本模型的同时,达到甚至超越大模型的效果。这是降低长期运营成本的重要路径。
以BetterYeah AI为例,其平台提供了支持100+主流大模型灵活接入的全栈LLMOps工具集,涵盖模型评估、Prompt调优、模型精调等完整链路,并支持公有云、混合云、私有化三种部署模式。对于需要同时管理多个agent开发推荐模型、兼顾效果与成本的企业团队,这类平台能显著降低模型管理的工程复杂度。
图:全栈LLMOps在agent开发中的模型管理架构
五、选对agent开发推荐模型,让Agent真正跑进生产
Agent能力的跃升已是既成事实,但"选对模型"这道门槛依然真实存在。核心结论可以归纳为三点:第一,用Agent专属的四维框架(工具调用、推理规划、长上下文、成本延迟)替代通用对话模型的选型逻辑;第二,根据具体业务场景从对比矩阵中精准匹配推荐模型,而非盲目追求"最强";第三,模型选型不是终点,全栈LLMOps工具链才是让推荐模型在生产环境中持续发挥价值的真正保障。选型做对了,Agent才能从Demo走进生产,从工具进化为真正的"数字员工"。

最新发布

热门推荐



