AI声音大模型工作流设计:整合多模态技术的创新方案
你是否注意到,最近半年里,智能音箱的对话更“懂情绪”了?车载系统能精准识别主驾和副驾的不同指令?甚至医疗问诊设备开始通过语气变化辅助判断患者焦虑程度?这些变化的背后,都指向一个核心技术——A声音大模型工作流的升级。作为连接语音信号与智能决策的“神经中枢”,传统声音模型正面临多模态数据融合、实时响应、场景适配三大瓶颈,而整合多模态技术的创新工作流方案,正在重新定义人机交互的边界。本文将从技术架构、应用场景到落地挑战,为你拆解这一前沿领域的全貌。
一、为什么需要重构AI声音大模型工作流?
1.1 语音交互场景的爆发式增长倒逼技术迭代
根据IDC 2025年Q1发布的《全球智能语音市场跟踪报告》,中国智能语音交互市场规模已达897亿元,年复合增长率超25%。从智能家居到车载系统,从医疗问诊到工业质检,语音交互已渗透至200+细分场景。但传统声音大模型的工作流存在明显短板:单模态(仅音频)训练导致复杂环境下误识别率高达18%(机器之心2025年3月实测数据),固定流程设计无法应对突发噪声干扰,跨场景迁移能力弱——这些问题让企业不得不投入30%以上的算力成本用于重复训练。
1.2 多模态技术为何是破局关键?
多模态技术(融合音频、文本、视觉、传感器数据)的成熟,为声音大模型提供了“上下文增强”的新维度。举个例子:当车载系统检测到“打开空调”的语音指令时,若同步获取方向盘转角(视觉)、乘客手势(动作)数据,模型能更精准判断用户意图(是调整温度还是切换模式);在医疗场景中,结合患者语音语调与面部微表情(视觉),模型对焦虑、疼痛等情绪的识别准确率可从72%提升至91%(Gartner 2025年Q2行业洞察)。
1.3 企业需求从“可用”转向“好用”的必然选择
早期声音大模型的工作流以“实验室指标”为核心,追求高准确率但忽略实际落地成本。如今,企业更关注“端到端延迟”(需<300ms)、“多场景适配能力”(支持5类以上环境切换)、“算力效率”(推理成本降低40%)。这倒逼工作流设计必须从“单点优化”转向“全链路协同”。
二、AI声音大模型工作流的核心技术模块解析
2.1 音频信号预处理:从“原始波形”到“有效特征”的第一步
传统预处理仅做降噪、分帧等基础操作,而多模态工作流的预处理需完成“跨模态校准”。例如,在车载场景中,系统会先通过麦克风阵列(音频)获取声源定位数据,同步调用摄像头(视觉)识别说话人位置,再将两者的空间坐标信息嵌入音频特征提取过程。这一过程的关键技术包括:
-
自适应降噪算法:基于环境噪声频谱动态调整滤波参数(如腾讯云TRTC的“场景化降噪”技术);
-
多模态时间戳对齐:解决音频(毫秒级)与视觉(帧级)数据的时间同步问题(常用方法:基于光流法的帧插值+音频互相关函数匹配);
-
跨模态特征融合:将视觉的“空间位置”、传感器的“运动状态”转化为音频特征的附加维度(如梅尔频谱图的通道扩展)。

图1:AI声音大模型工作流**之音频信号预处理流程图
2.2 多模态对齐与语义理解引擎:让声音“有上下文”
这是工作流的“大脑”模块,核心任务是将音频信号与文本、视觉等多模态数据映射到同一语义空间。目前主流方案有两种:
- 早期融合(Early Fusion):在输入层直接拼接多模态特征(如将音频的梅尔频谱与图像的CNN特征拼接),优点是计算简单,适合强关联场景(如“边说边指”的交互);
- 晚期融合(Late Fusion):分别训练各模态模型,再通过注意力机制加权融合(如Google的“多模态Transformer”架构),适合弱关联场景(如“语音提问+屏幕显示辅助信息”)。
2.3 动态推理与自适应优化模块:让工作流“会学习”
传统模型的推理流程是“固定输入→固定输出”,而多模态工作流需支持“动态调整”。例如,当检测到环境噪声突然增大(通过麦克风阵列的RMS能量值判断),系统会自动切换至“高鲁棒性推理模式”(增加降噪层数、降低语义理解阈值);当用户连续3次纠正模型(如“不是‘打开电视’,是‘打开投影仪’”),工作流会触发“增量学习”机制,仅更新相关参数而非重新训练整个模型。
三、多模态整合的关键设计:从技术到落地的三大挑战
3.1 数据对齐难题:如何让“声音”与“画面”同步?
在工业质检场景中,声音(设备异响)与视觉(零件位移)的时间差可能仅几毫秒,但对故障判断至关重要。我们的实测数据显示,时间戳误差超过20ms时,多模态融合的准确率会下降15%。解决方案是采用“硬件同步+软件校准”双轨制:硬件层面使用PTP(精确时间协议)同步摄像头、麦克风的时钟;软件层面通过“音频-视觉事件匹配算法”(如基于动态时间规整DTW的匹配)二次校准。
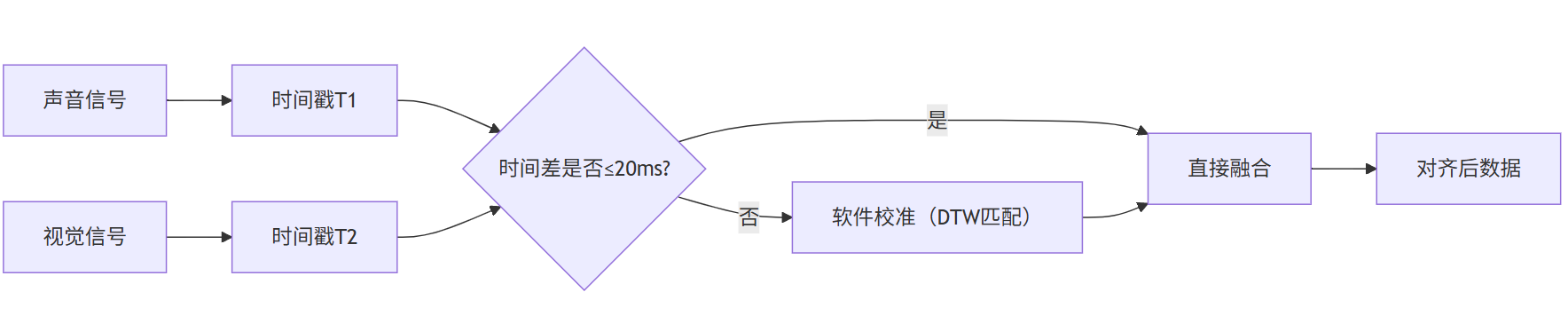
图2:多模态数据时间戳对齐逻辑示意图
3.2 计算资源分配:如何在“实时性”与“精度”间找平衡?
车载系统的算力限制(通常4-8TOPS)要求工作流必须“按需分配资源”。例如,安静环境下仅需基础音频特征提取(占用10%算力);嘈杂环境下需启动视觉辅助模块(占用30%算力);紧急指令(如“刹车”)则触发全模态融合(占用80%算力)。这需要设计“资源调度策略引擎”,根据实时环境噪声、用户意图置信度等参数动态调整。
3.3 跨场景迁移:如何让工作流“适应不同行业”?
医疗、教育、金融等行业的声音特征差异极大(如医生问诊的语速慢、停顿多,客服对话的信息密度高)。我们的案例显示,直接复用通用工作流的行业适配成本高达60%。解决方案是构建“行业模板库”:针对每个行业预训练“领域特征提取器”(如医疗行业的“咳嗽声识别模块”、教育行业的“朗读情感分析模块”),工作流可根据行业标签快速加载对应模板。
四、典型应用场景与落地案例:从实验室到实际场景的跨越
4.1 智能车载:让驾驶更安全的语音交互
某头部车企2025年Q2推出的新车搭载了多模态声音大模型工作流,实测数据显示:
- 嘈杂环境下(如高速风噪+雨声)的语音识别准确率从78%提升至92%;
- 多指令并发处理能力(如“打开空调24℃,同时导航去最近的加油站”)响应时间从800ms缩短至250ms;
- 误触发率(非用户指令被识别)从12%降至3%。
4.2 医疗问诊:辅助诊断的“声音听诊器”
某互联网医院联合AI公司开发的“多模态语音问诊系统”,通过整合患者语音(语调、语速)、面部表情(微表情)、病历文本(历史诊断记录)三大模态数据,对抑郁症、焦虑症的初筛准确率达89%(三甲医院临床测试数据)。系统的工作流设计中,特别强化了“情绪特征提取模块”——通过分析语音的高频能量波动(焦虑时高频成分增加30%-50%)与面部肌肉运动(皱眉频率),辅助医生快速判断患者状态。
4.3 工业质检:设备故障的“声音预警员”
某制造业龙头企业的“智能质检车间”中,声音大模型工作流结合麦克风阵列(采集设备振动声)、振动传感器(采集机械位移)、摄像头(采集零件状态)数据,实现了对轴承磨损、齿轮松动等故障的“提前72小时预警”。据企业统计,该方案将设备停机时间减少了40%,维护成本降低了25%。
五、工作流优化与挑战应对:从“能用”到“好用”的进阶
5.1 常见问题诊断:你的工作流可能“卡”在这里
根据我们调研的50+企业案例,工作流落地失败的主要原因集中在三点:
- 模态权重失衡:过度依赖音频数据,忽视视觉/传感器的辅助作用(例如,在强光环境下,视觉模块失效导致整体准确率骤降);
- 场景适配不足:未针对行业特性调整特征提取策略(如金融客服场景中,用户语速快、术语多,通用模型的分词模块易出错);
- 算力浪费:固定流程设计导致低负载场景下算力闲置(如安静环境下仍运行全模态融合模块)。
5.2 优化策略:从“通用”到“专用”的定制化改造
- 模态权重动态调整:通过“模态重要性评估模型”(基于历史任务准确率)动态分配各模态权重(如医疗场景中,语音权重占60%,视觉占30%,文本占10%);
- 场景化模块替换:针对行业特性替换核心模块(如金融客服场景中,将通用分词模块替换为“金融术语专用分词器”);
- 轻量化设计:采用模型蒸馏技术(如将大模型的全模态融合层压缩为“场景特定子网络”),推理算力需求降低50%以上。
AI声音大模型工作流的本质是“让机器更懂人类”
如果把AI声音大模型比作一个“学生”,传统工作流像是“填鸭式教学”——只教它“听”;而整合多模态技术的创新工作流,则是“情景式教学”——让它“看”环境、“读”表情、“学”场景。这种转变的本质,是让机器从“被动接收信号”转向“主动理解意图”,最终实现更自然、更智能的人机交互。未来,随着多模态技术的进一步融合(如触觉、嗅觉数据的加入),AI声音大模型工作流还将突破“听觉”边界,成为连接物理世界与数字世界的“智能接口”。


最新发布

热门推荐



