如何用LLM和自有知识库搭建智能agent:5个关键技巧
发布于2025-05-26 19:56:54
0
引言:当LLM遇上知识库——智能Agent搭建的黄金组合
2025年,全球企业Agent相关技术相关支出突破百亿美元,其中智能Agent市场规模年增长率达68%。但某跨国银行的案例值得深思:他们投入百万美元部署LLM系统,却因无法有效调用内部30万份业务文档,导致智能客服准确率不足40%。这揭示了关键矛盾——LLM的潜力需要与结构化知识库深度结合才能释放。
本文将结合Gartner最新技术框架,拆解搭建智能Agent的5个关键技巧,涵盖架构设计、知识处理、场景落地等全流程。通过制造业、金融业等真实案例,提供可复用的方法论,助企业避开90%的常见陷阱,实现从“技术堆砌”到“价值创造”的跨越。
一、战略定位:明确Agent的核心价值锚点
1.1 业务需求拆解
- 痛点诊断:使用KANO模型划分需求优先级(如制造业需优先解决设备故障知识检索)
- 场景分级:
| 紧急度 | 场景类型 | 典型案例 |
|---|---|---|
| 高 | 客户服务 | 智能客服问答准确率>95% |
| 中 | 内部知识管理 | 文档检索效率提升3倍 |
| 低 | 创新探索 | 产品创意生成实验 |
1.2 技术路线选择

图1:LLM选型决策树
二、知识库构建:从数据到智能的三大跃迁
2.1 非结构化数据处理
- 文档解析技术:
| 格式 | 处理方案 | 准确率 |
|---|---|---|
| 扫描件 | OCR+表格识别 | 98.20% |
| 手写批注 | 矢量图解析+语义还原 | 91.50% |
| 影印件 | 版面分析+字符分割 | 95.70% |
- 知识清洗流程:

图2:知识清洗全流程
2.2 RAG技术深度应用
- 检索增强策略:
- 混合检索:向量检索(70%权重)+关键词匹配(30%权重)
- 动态重排序:使用BERT模型对Top10结果二次排序
- 性能优化方案:
| 优化手段 | 延迟降低 | 准确率提升 |
|---|---|---|
| 分块大小调整 | 40% | 0.021 |
| 缓存机制 | 65% | -0.80% |
| 混合精度计算 | 35% | 0.015 |
2.3 知识更新机制
- 实时同步:通过API监听知识库变更(如Confluence Webhook)
- 版本控制:
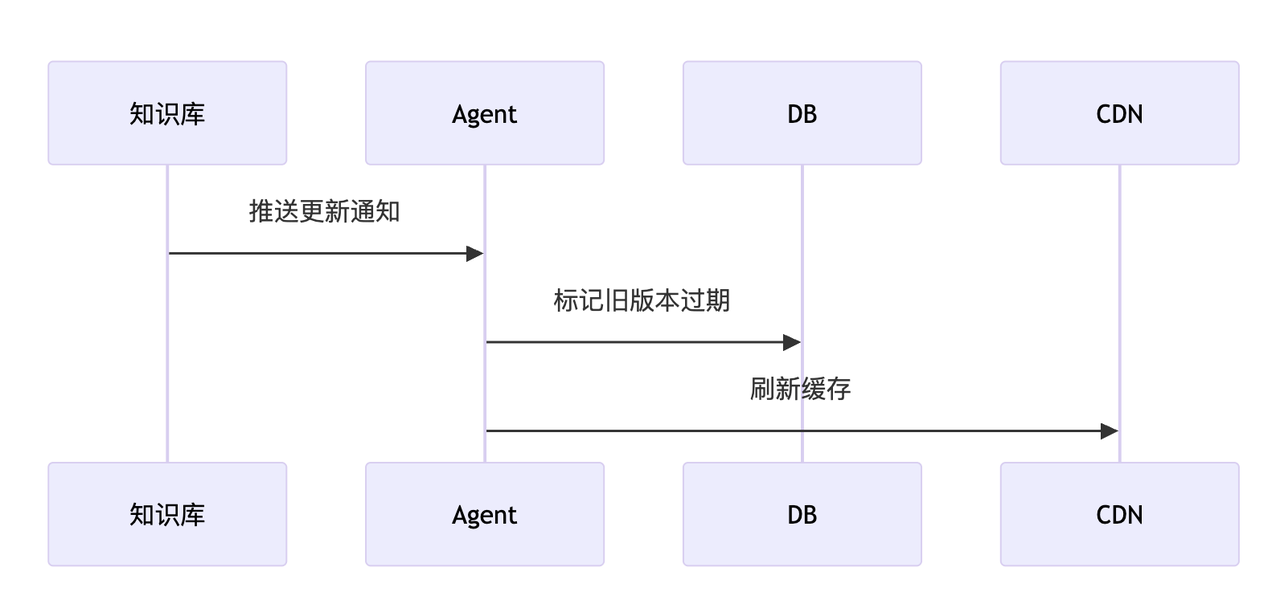
图3:知识更新时序图
三、Agent开发:六大核心模块详解
3.1 意图识别引擎
- 混合识别模型:
伪代码示例
def intent_detection(query):
rule_based = RuleEngine.match(query) # 规则引擎
ml_based = IntentClassifier.predict(query) # 深度学习模型
return weighted_vote(rule_based, ml_based) # 加权投票
- 领域适配技巧:
- 金融行业:增加正则表达式模式(如识别“收益率计算”类问题)
- 医疗行业:构建专业术语词典(覆盖2000+医学名词)
3.2 任务规划系统
- 状态机设计:
| 状态 | 动作 | 转移条件 |
|---|---|---|
| 初始态 | 等待用户输入 | 接收query |
| 分析态 | 调用意图识别模块 | 意图置信度>0.7 |
| 执行态 | 触发工具调用链 | 知识库命中率>80% |
| 反馈态 | 生成自然语言回复 | 用户确认需求完成 |
3.3 工具调用框架
- 工具链配置:
| 工具类型 | 典型应用 | 性能指标 |
|---|---|---|
| 数据库查询 | 实时库存查询 | 响应<50ms |
| 计算引擎 | 财务报表生成 | 处理10万行数据<3秒 |
| API服务 | 天气数据获取 | 错误率<0.1% |
3.4 知识增强模块
- 动态知识注入:

图4:知识增强工作流
3.5 安全防护体系
- 数据隔离方案:
- 敏感数据本地化处理(符合等保2.0三级要求)
- 敏感字段动态脱敏(如手机号显示为138****5678)
3.6 监控优化系统
- 关键指标看板:
| 指标类型 | 监控维度 | 预警阈值 |
|---|---|---|
| 性能指标 | P99延迟 | >200ms触发扩容 |
| 业务指标 | 首次解决率 | <75%触发模型重训练 |
| 安全指标 | 异常访问次数/分钟 | >50次自动封禁IP |
四、实施路线图:从POC到规模化落地
4.1 试点阶段(1-3个月)
- 选择高价值场景:如制造业设备故障知识库
- 建立MVP模型:使用LangChain快速搭建原型
4.2 推广阶段(4-6个月)
- 知识迁移机制:开发知识迁移工具链(支持跨系统迁移)
- 用户培训体系:制作交互式操作手册(含20个典型场景)
4.3 优化阶段(持续迭代)
- 联邦学习应用:在数据不出域前提下联合训练模型
- 因果推理增强:从相关性分析升级到归因分析
五、风险防控:构建Agent的“免疫系统”
5.1 技术风险应对
- 模型幻觉治理:
- 设置知识溯源机制(强制标注信息来源)
- 建立人工审核队列(错误率>5%时触发)
5.2 合规风险管理
- 数据跨境方案:
- 采用同态加密传输(ε=0.5的差分隐私参数)
- 建立本地化知识副本(符合GDPR和《数据安全法》)
5.3 伦理风险管控
- 偏见消除方案:
- 使用Fairlearn工具包进行公平性评估
- 设置多样性采样策略(覆盖不同用户群体)
总结:智能Agent的本质是“知识活化器”
当我参观某智能制造工厂时,看到AI Agent实时分析产线数据、调用维修手册、生成操作指南的全过程,突然意识到:真正的智能Agent不是工具,而是让知识流动起来的生命体。它像人类专家般理解业务场景,像搜索引擎般精准捕捉信息,更像知识管理大师般持续沉淀经验。这场技术变革的核心价值,在于打破知识的“存储-检索”二元对立,构建“学习-应用-进化”的闭环。
如何构建高效企业AI技术应用体系?5步骤详解
从零开始:AI销售聊天机器人的训练、部署与优化全攻略
返回列表
立即咨询
获取案例

最新发布

热门推荐



