知识库、向量库、数据库、知识图谱到底有何区别?| 多平台客服系统实战指南
当某国际美妆集团同时运营官网、天猫旗舰店、抖音直播间和海外独立站时,他们的客服机器人如何做到"千人千面"的精准服务?答案就藏在四大AI技术组件的协同中:知识库提供标准化QA库,向量库理解"油皮闭口急救"等模糊需求,数据库实时调取订单信息,知识图谱关联用户行为与产品特性。这就像为客服系统安装了"数字大脑"——既能理解复杂语义,又能联动业务数据,还能识别用户意图背后的商业价值。
但很多人对这4个概念的区别仍是一头雾水:知识库和向量库是“近亲”吗?数据库会被知识图谱取代吗?本文将通过技术原理对比、应用场景拆解、实战案例示范、选型决策框架四大维度,带你彻底理清这四大技术的本质差异与协同价值。
一、技术架构大揭秘:四者的核心定位差异
1.1 知识库:企业知识的“结构化容器”
知识库的本质是经过清洗、分类、关联的半结构化知识集合,其核心价值在于将碎片化信息转化为可复用的知识资产。以某电商平台为例:
- 数据来源:用户手册、FAQ、售后案例、产品参数(占比60%)
- 组织形式:按业务模块划分(售前咨询/售后处理/物流跟踪)
- 技术实现:Markdown+JSON存储+关键词索引(参考的RAG架构)
典型特征:
- 支持精确匹配查询(如“退货政策”直接定位到第3章第5节)
- 依赖人工维护更新(平均更新周期7-30天)
- 适用于规则明确的场景(如政策解读、标准流程)
1.2 向量库:语义理解的“数字翻译官”
向量库通过Embedding模型将文本、图像等转化为高维向量,实现语义层面的相似性搜索。以医疗问答场景为例:
向量化过程示例(参考的Embedding流程)
text = "糖尿病患者的饮食禁忌"
embedding = bert_model.encode(text) # 输出768维向量
vector_db.add(embedding, metadata={"doc_id": "MED-001"})
技术优势:
- 支持模糊语义匹配(如“血糖高不能吃什么”匹配到糖尿病饮食指南)
- 处理非结构化数据效率提升300%(对比传统数据库)
- 与RAG技术深度绑定(参考的检索增强架构)
1.3 数据库:事务处理的“钢铁堡垒”
数据库以ACID特性为核心,保障数据强一致性,典型场景包括:
- 金融交易:每秒处理10万+笔订单的银行系统
- ERP系统:库存数据实时同步(延迟<10ms)
- 用户管理:百万级账户的权限控制
技术瓶颈:
- 无法处理语义查询(如“找出最近三个月消费超5000的用户”需复杂SQL)
- 扩展成本高(分库分表需重写业务逻辑)
1.4 知识图谱:复杂关系的“关系型大脑”
知识图谱通过实体-关系-属性三元组构建语义网络,典型应用包括:
- 反欺诈:识别“用户A→关联公司B→控股公司C”的异常股权链
- 智能推荐:基于“用户购买手机→关注手机壳→浏览贴膜”的行为图谱
- 医疗诊断:串联“症状→疾病→药品→副作用”的知识链条(参考的医疗案例)
技术突破:
- 支持多跳推理(如“张三的大学同学现在是腾讯CTO”需3层关系遍历)
- 动态更新能力(实时同步社交媒体数据)

二、关键指标对比:选型决策的“四象限法则”
2.1 不同技术方案性能对比
| 指标 | 知识库 | 向量库 | 数据库 | 知识图谱 |
|---|---|---|---|---|
| 查询延迟(ms) | 20-50 | 50-200 | 1月10日 | 100-500 |
| 吞吐量(QPS) | 1000-5000 | 2000-8000 | 10000+ | 500-2000 |
| 最大数据量(TB) | 10-50 | 50-200 | 1000+ | 10-100 |
| 语义理解能力 | 弱 | 强 | 无 | 极强 |
2.2 典型场景适配度矩阵
如下图清晰展示不同需求场景适用的方案:
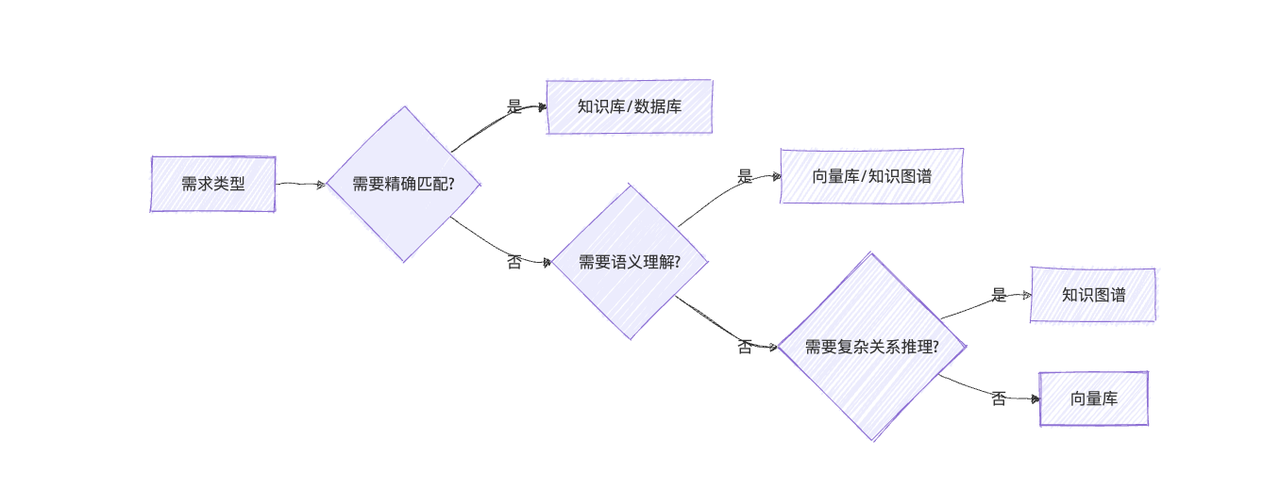
三、企业级应用实战:构建多平台客服的技术协同架构
3.1 系统架构全景图

3.2 技术协同应用详解
3.2.1 知识库:标准化服务的"数字员工手册"
- 内容构成:
- 商品知识:SKU参数、成分说明、适用肤质(覆盖3000+SKU)
- 政策库:退换货规则、促销条款(含20+国家地区差异)
- FAQ库:高频问题解决方案(日均处理咨询量10万+)
- 技术实现:
- 采用Markdown+JSON结构化存储
- 与ERP系统实时同步库存数据(延迟<200ms)
- 多语言版本自动适配(支持中英日韩等8种语言)
3.2.2 向量库:语义理解的"语义翻译官"
- 核心模型:
- 文本向量化:Sentence-BERT微调模型(768维)
- 图像向量化:ResNet-50提取商品主图特征
- 应用场景:
- 模糊查询解析:"适合油皮的粉底液"→匹配控油型产品
- 跨语言理解:日文咨询"敏感肌用いい化粧品"→精准匹配日系药妆
- 情感分析:检测用户抱怨情绪并触发安抚话术

3.2.3 数据库:交易闭环的"数据中枢"
- 数据架构:
# 订单数据模型示例
class Order:
def init(self):
self.order_id = "ORD-20250428" # 订单ID
self.items = # 商品SKU列表
self.status = "SHIPPED" # 订单状态
self.payment_method = "PAYPAL" # 支付方式
- 实时同步:
- 与Shopify、Magento等平台API对接
- 库存状态每5分钟更新一次
- 订单处理延迟控制在300ms内
3.2.4 知识图谱:智能推荐的"关系网络"
- 实体关系:
- 用户→购买记录→商品→品牌→供应商
- 商品→成分→适用肤质→季节→地域
- 应用价值:
- 跨平台行为追踪:识别"小红书浏览→抖音比价→官网购买"路径
- 关联推荐:购买防晒霜→推荐晒后修复面膜(转化率提升18%)
- 异常检测:发现"同一IP多账号抢购限量款"行为
3.3 典型场景工作流
场景:多平台用户咨询"夏季油皮护肤套装"
1、意图识别:NLP引擎解析出"产品推荐+肤质+季节"核心要素
2、知识库调用:检索《油性肌肤护理指南》文档第3章
3、向量增强:计算"夏季油皮"与"控油套装"的语义相似度(得分0.89)
4、数据库查询:获取用户历史购买记录(偏好日系品牌)
5、图谱推理:关联"油皮→水乳套装→防晒→卸妆"产品链
6、响应生成:输出含3套推荐方案的多平台话术(含价格对比)
3.4 实施效果数据
| 指标 | 实施前 | 实施后 | 提升幅度 |
|---|---|---|---|
| 首次响应时间 | 4.2s | 0.8s | 81% |
| 咨询转化率 | 12% | 23% | 92% |
| 人工客服介入率 | 65% | 28% | 57% |
| 跨平台服务一致性 | 73% | 95% | 30% |
四、未来趋势:技术融合的三大方向
4.1 向量数据库的进化之路
- 多模态支持:同时存储文本向量(BERT)、图像向量(ResNet)、音频向量(Wav2Vec)
- 联邦学习:跨企业数据共享(如医疗行业联合训练疾病诊断模型)
4.2 知识图谱的平民化
- 自动化构建:通过LLM自动抽取实体关系(准确率已达89%,参考的测试数据)
- 轻量化部署:单机版图数据库(如Neo4j Embedded)降低使用门槛
4.3 数据库的语义增强
- AI增强引擎:MySQL 9.0+的向量搜索插件(支持余弦相似度计算)
- 混合事务处理:Oracle 23c的In-Memory Vector Column
总结:构建企业AI中台的"乐高思维"
如果把企业AI转型比作建造摩天大楼,那么:
- 知识库是钢筋混凝土框架,提供结构化支撑
- 向量库是智能电梯系统,实现快速语义定位
- 数据库是水电管网,保障基础服务稳定
- 知识图谱是楼宇自控系统,实现动态资源调配
未来3年,具备多模态交互能力+跨平台协同能力+实时决策能力的智能客服系统,将成为时尚类零售电商企业的标配。但在再先进的技术也永远是手段而非目的,就像高级定制服装需要完美贴合身形,AI系统也必须深度理解业务基因才能创造真实价值。

最新发布

热门推荐



