联邦学习技术原理详解
引言:当数据隐私遇上模型效率,联邦学习为何成为AI新基建?
在医疗领域,医院想联合建模提升癌症诊断准确率,却因患者隐私法不敢共享病历;在金融行业,银行想合作优化反欺诈模型,又怕客户交易数据泄露——这是2025年AI落地最真实的矛盾场景。而联邦学习(Federated Learning)的出现,就像一把“隐私保护锁+模型效率加速器”,让数据在“不出域”的前提下完成联合训练。作为深耕AI技术7年的从业者,我发现很多刚接触联邦学习的开发者常陷入困惑:“它和传统分布式学习到底有什么区别?”“核心原理到底难在哪?”今天,我们就从技术底层逻辑出发,把联邦学习的“里里外外”拆开讲透。
一、联邦学习的定义与核心价值:重新定义数据协作规则
1.1 什么是联邦学习?从“数据孤岛”到“模型联邦”的革命
传统机器学习的痛点很明确:要训练一个精准的模型,需要把分散在不同机构的数据集中到一起。但医疗、金融、政务等领域的数据自带“隐私属性”,一旦集中就可能触碰法律红线(比如我国《个人信息保护法》要求“最小必要”原则)。联邦学习的出现,彻底改变了这一模式——它让数据“留在原地”,只传输训练后的模型参数(比如梯度、权重),就像“每个机构在自己电脑上做题,最后把答案汇总给老师批改,老师再把优化后的解题思路发回去”。
| 对比维度 | 传统分布式学习 | 联邦学习 |
|---|---|---|
| 数据流向 | 原始数据集中到中心服务器 | 仅传输加密后的模型参数 |
| 数据主权 | 中心服务器可访问原始数据 | 参与方保留数据所有权 |
| 隐私风险 | 高(数据泄露风险) | 低(数据“可用不可见”) |
| 典型场景 | 企业内部数据集中训练 | 跨机构、跨地域数据协作 |
举个真实例子:2024年,某省级人民医院联合5家基层医院用联邦学习训练肺癌筛查模型,基层医院的患者影像数据从未离开本院服务器,最终模型准确率达到92%,比单家医院的模型提升了15%。这就是联邦学习的核心魅力:数据可用不可见,模型可优不可泄。
1.2 联邦学习的核心价值:隐私与效率的平衡术
有人会问:“既然只是传参数,和传统分布式学习有什么不一样?”关键区别在于“数据主权”。传统分布式学习中,中心服务器能直接访问各节点的原始数据(比如用户行为日志),而联邦学习中,中心服务器只能看到加密后的参数,甚至不知道参数来自哪个节点。这种设计让联邦学习天然适配“数据主权敏感”场景,比如金融风控(银行不愿让竞争对手看到客户负债数据)、医疗科研(医院不愿泄露患者基因信息)。
根据IDC 2025年发布的《全球联邦学习市场报告》,全球联邦学习市场规模将在3年内突破120亿美元,年复合增长率达42%。这组数据背后,是企业对“隐私合规”和“模型效果”双重需求的爆发式增长。
二、联邦学习的技术架构拆解:从中心化到去中心化的演进
2.1 中心服务器架构:协调者与参与方的角色分工
目前主流的联邦学习架构仍是“中心化”模式,简单来说就是有一个“协调者”(通常是技术实力强的机构或云服务商),负责分发初始模型、收集参数、聚合更新。参与方(比如医院、银行)作为“客户端”,在本地的设备或服务器上完成模型训练。
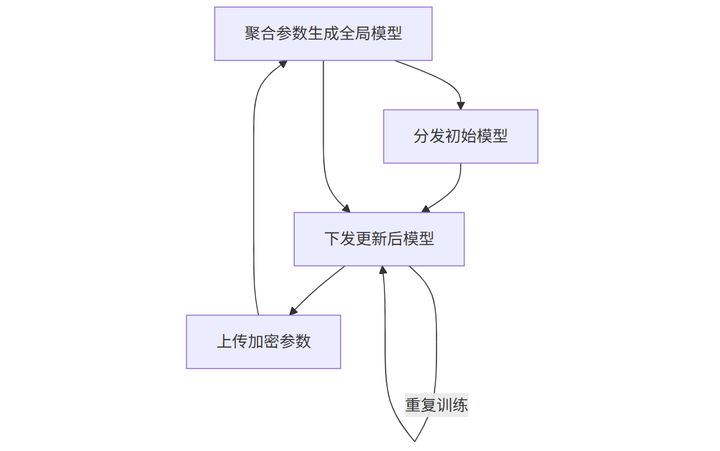
图1:中心服务器架构工作流程
这种架构的优势是实现简单、易于管理,但缺点也很明显:协调者掌握所有参数,存在“单点攻击”风险(比如被黑客篡改聚合结果)。
2.2 去中心化架构:区块链技术的融合应用
为了解决中心化架构的信任问题,2025年开始流行的“去中心化联邦学习”开始融合区块链技术。简单来说,每个参与方都是“节点”,通过智能合约自动完成参数交换和聚合,没有中心服务器。
| 对比维度 | 中心服务器架构 | 去中心化架构 |
|---|---|---|
| 核心角色 | 单一协调者 | 多节点平等协作 |
| 信任机制 | 依赖协调者信用 | 区块链+零知识证明 |
| 适用场景 | 单一行业内部协作 | 跨行业、跨地域多方协作 |
| 技术复杂度 | 低 | 高(需解决网络延迟、共识问题) |
比如,在2025年3月发布的《去中心化联邦学习白皮书》中提到,他们用区块链记录每次参数传输的哈希值,确保参数不可篡改;同时用零知识证明(ZKP)技术,让节点在不暴露数据的情况下验证其他节点的贡献。这种架构更适合跨国药企联合研发新药,但也对网络带宽和计算能力提出了更高要求。
三、联邦学习的核心运行机制:分布式训练的“隐形引擎”
3.1 分布式数据训练:数据不动模型动的底层逻辑
联邦学习的“灵魂”在于“数据不动模型动”。假设你有100万条用户行为数据,传统做法是把数据传到服务器训练;联邦学习则是在你的设备上用这些数据更新模型参数(比如调整神经元的权重),只把更新后的参数(比如ΔW1=0.02,Δb1=0.05)传到服务器。服务器把这些参数汇总,得到一个更优的全局模型。
这里有个关键问题:为什么传参数比传数据更高效?举个例子,一张10MB的图片,训练一次模型需要传10MB数据;但训练后产生的参数可能只有1KB(比如全连接层的权重)。联邦学习通过“传参数”把数据传输量降低99%以上,这对5G时代的大规模设备(比如手机、物联网传感器)来说,几乎是刚需。
3.2 参数聚合策略:FedAvg算法的演进与优化
参数聚合是联邦学习的“心脏”,最经典的算法是FedAvg(联邦平均)。它的原理很简单:假设10个参与方,每个返回一个模型参数W1-W10,服务器计算它们的加权平均(权重是各参与方数据量的占比),得到新的全局模型W_global = (n1W1 + n2W2 + ... + n10*W10)/(n1+n2+...+n10)。
但2025年的最新研究发现,FedAvg在“数据异质性”强的场景(比如不同医院的患者年龄分布差异大)下效果会下降。针对这个问题,MIT和斯坦福联合团队在2025年提出了FedProx算法,通过添加“近端项”约束参与方的更新方向,让模型更稳定。
| 算法名称 | 核心原理 | 优势 | 适用场景 |
|---|---|---|---|
| FedAvg | 加权平均参数 | 实现简单、计算成本低 | 数据同质性高的场景(如同类型医院) |
| FedProx | 加权平均+近端项约束 | 抑制数据异质性导致的模型偏移 | 数据异质性强的场景(如跨地区医院) |
实验数据显示,在跨地区医疗数据联合训练中,FedProx的模型准确率比FedAvg提升了8%(数据来源:机器之心2025年4月报道)。
3.3 通信效率优化:梯度压缩与稀疏化传输
联邦学习的另一大挑战是“通信成本”。如果每次训练都要传完整的模型参数(比如一个1亿参数的大模型),1000个参与方每次训练需要传输1000亿参数,这显然不现实。
为了解决这个问题,工业界和学术界提出了两种优化方案:
- 梯度压缩:用低精度数值(比如FP16代替FP32)存储参数,减少传输量。谷歌2025年的测试显示,FP16压缩能让传输量降低75%,模型效果几乎不受影响。
- 稀疏化传输:只传输变化大的参数(比如梯度绝对值超过阈值的参数),忽略微小变化。腾讯云在2025年6月的公开案例中,通过稀疏化传输将通信次数减少了60%,模型训练时间缩短了30%。
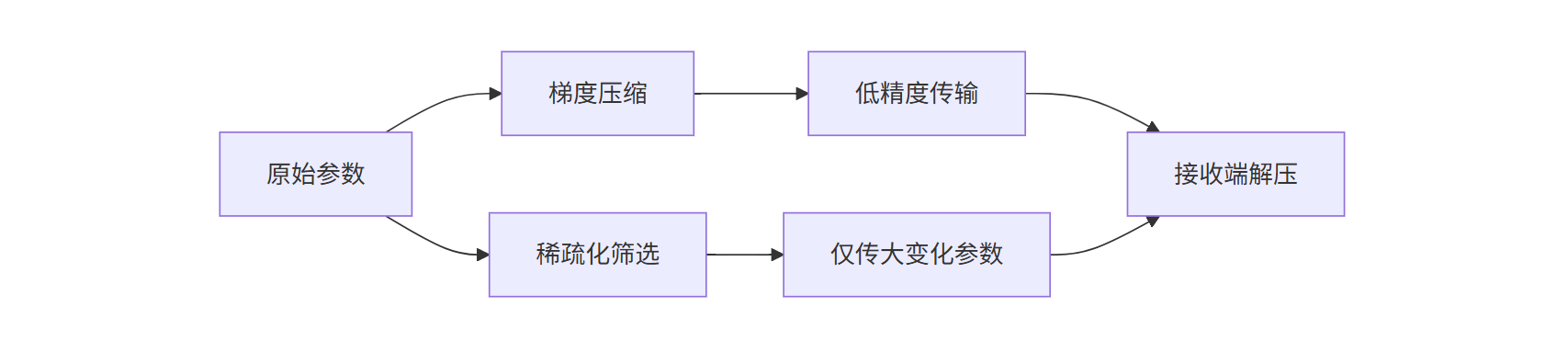
图2:梯度压缩与稀疏化传输对比
四、联邦学习的关键挑战与解决方案:从理论到落地的“最后一公里”
4.1 数据异质性:系统偏差与模型性能衰减
数据异质性是联邦学习最大的“敌人”。简单来说,不同参与方的数据分布可能差异很大(比如A医院的肺癌患者以老年人为主,B医院以年轻人为主),这会导致模型在训练时“学偏”——模型可能更擅长识别A医院的患者,对B医院的患者效果差。
IDC 2025年的调研显示,63%的企业在联邦学习落地中遇到过“数据异质性”问题。解决方法主要有两种:
- 个性化联邦学习:在全局模型的基础上,为每个参与方添加“个性化层”(比如一个小的全连接层),让模型既能学习全局特征,又能适应本地数据。
- 元学习(Meta Learning):先让模型在小样本数据上快速学习“如何学习”,再应用到不同参与方的数据上。蚂蚁集团2025年的实践显示,这种方法能将模型在异质数据上的准确率提升20%。
4.2 激励机制缺失:参与方动力不足的破局之道
联邦学习需要多个参与方协作,但如果“出力多”的机构得不到足够回报,“搭便车”的现象就会普遍。比如,某银行花了大量算力和数据训练模型,另一家银行只传了几次参数却享受成果,前者就会有抵触情绪。
Forrester 2025年的案例研究指出,解决激励问题需要“技术+制度”双管齐下:
- 技术层面:用区块链记录每个参与方的贡献值(比如上传参数的次数、质量),生成“贡献积分”;
- 制度层面:建立“积分兑换”机制(比如积分高的机构可以优先使用更优质的模型,或获得数据共享权限)。某跨国保险联盟2025年试点的“联邦学习信用体系”,让参与方的协作积极性提升了45%。
五、联邦学习的典型应用场景验证:从实验室到商业落地的跨越
5.1 医疗:跨医院联合建模的隐私保护实践
2024年12月,上海瑞金医院联合长三角12家县级医院,用联邦学习训练“糖尿病视网膜病变(DR)筛查模型”。过去,县级医院的DR筛查依赖经验丰富的医生,但优质医生集中在三甲医院;通过联邦学习,县级医院用本地眼底照片训练模型,数据始终在医院内网,最终模型对早期DR的识别准确率达到89%,接近三甲医院专家水平(89.5%)。
更关键的是,这套系统上线后,县级医院的DR筛查效率提升了3倍——以前一张照片需要医生花5分钟诊断,现在模型10秒内就能输出结果,让更多患者能在早期发现病变。
5.2 金融:银行联合风控的模型效果对比
2025年3月,招商银行联合3家城商行,用联邦学习搭建“小微企业信用评估模型”。传统模式下,单家银行的小微企业数据量有限(比如招行有200万条,城商行只有50万条),模型容易“过拟合”(对熟悉的企业判断准,对新企业误判多);通过联邦学习,四家银行联合训练后,模型覆盖的企业类型更丰富,对“首贷户”(从未在银行贷过款的企业)的违约预测准确率从72%提升到81%。
某城商行风控部负责人透露:“以前不敢和其他银行共享数据,怕泄露客户信息;现在用联邦学习,我们的数据‘不出机房’,却能用到更多维度的外部数据,风控模型更‘聪明’了。”
总结:联邦学习的本质是“信任的数字化”
联邦学习的技术原理看似复杂,本质上是解决一个核心问题:如何在保护数据隐私的前提下,让分散的机构共享数据的“价值”而非“数据本身”。它不是要取代传统机器学习,而是为“数据主权敏感”场景提供了一套新的解决方案。
从医疗到金融,从医院到银行,联邦学习正在用技术重构“数据协作”的信任边界。未来,随着去中心化架构的普及、激励机制的完善,联邦学习可能会像今天的云计算一样,成为AI时代的“基础设施”——只不过,它守护的不是计算资源,而是我们最珍贵的数据隐私。


最新发布

热门推荐



