从RAG到Agent:LLM知识库问答系统的进阶之路与最佳实践
上周和某金融企业的AI负责人聊天时,他吐槽道:“我们花大价钱搭的RAG知识库问答系统,现在用户问‘去年Q3的基金持仓变化和今年Q1的对比’,系统要么答非所问,要么直接说‘无法回答’。” 这种尴尬,我太熟悉了——这正是传统RAG(检索增强生成)系统在复杂场景下的典型短板。而最近半年,我观察到越来越多企业开始将LLM知识库问答系统向Agent(智能体)方向升级,从“被动检索”转向“主动决策”,这背后究竟藏着怎样的技术逻辑?作为深度参与过3家企业知识库系统迭代的从业者,我想通过这篇文章,拆解从RAG到Agent的进阶路径,分享能让企业少走弯路的最佳实践。
一、从RAG到Agent:LLM知识库问答的演进逻辑
1.1 RAG的诞生:解决LLM“幻觉”的初始方案
2023年前后,大语言模型(LLM)虽在通用对话中表现惊艳,但在专业领域却频现“幻觉”(Hallucination)——比如回答“某上市公司2022年净利润”时,可能编造一个不存在的数据。为解决这一问题,RAG(Retrieval-Augmented Generation,检索增强生成)技术应运而生。其核心逻辑是:当LLM需要回答专业问题时,先通过检索模块从外部知识库(如企业文档、行业数据库)中召回相关内容,再将检索结果与LLM的生成能力结合,最终输出答案。
典型架构:RAG系统由“检索器”(Retriever)、“生成器”(Generator)和“知识库”三部分组成。检索器负责从海量文档中精准抓取相关段落(如通过BM25、Dense Passage Retrieval等算法),生成器基于这些段落和用户问题生成答案,知识库则是存储结构化/非结构化数据的底层载体。
1.2 Agent的出现:从“信息检索”到“主动决策”的跨越
随着企业对知识库问答的需求从“回答问题”升级为“解决问题”,RAG的局限性逐渐显现——它只能基于已有知识库内容生成答案,无法主动调用工具(如查询实时股价、发送邮件通知)、跟踪对话状态(如记住用户3天前提到的“关注新能源板块”)或进行多步推理(如分析“某项目成本超支,可能的原因是供应商涨价还是工期延误”)。
Agent的出现打破了这一限制。简单来说,LLM知识库问答Agent是在RAG基础上,为LLM增加了“记忆模块”(Memory)、“工具调用模块”(Tool Use)和“任务规划模块”(Planning),使其具备“持续学习”“主动执行”“复杂决策”的能力。例如,某电商企业的客服Agent不仅能从知识库中调取商品信息,还能主动查询物流系统实时数据,并根据用户历史投诉记录调整回复策略。
二、RAG系统的核心架构与技术瓶颈
要理解从RAG到Agent的进阶,首先需要明确RAG的技术边界。以下是其核心架构与常见瓶颈的深度拆解。
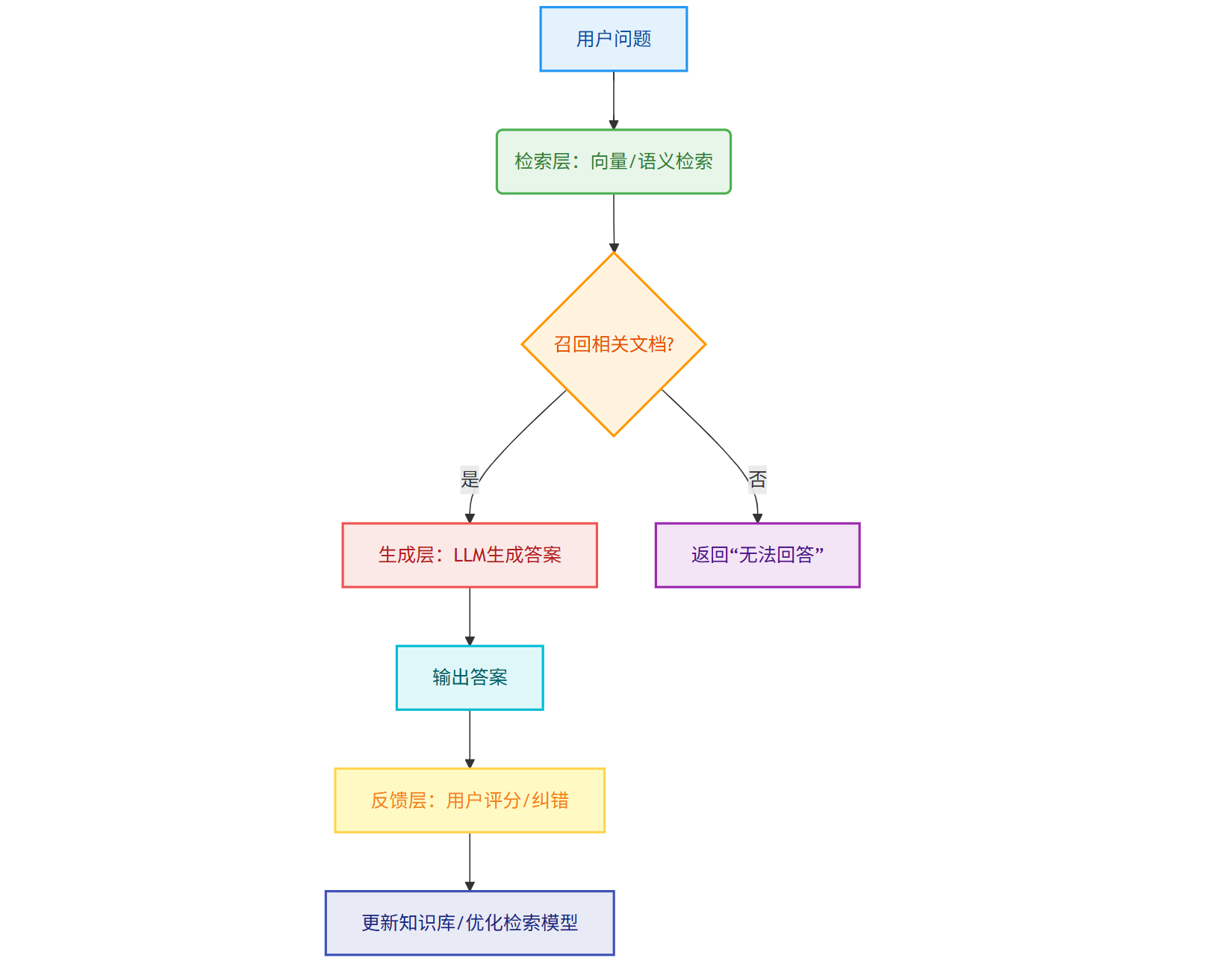
2.1 RAG的核心架构:检索-生成-反馈的闭环
典型的RAG系统架构可分为三个层级:
数据层:存储结构化数据(如SQL数据库)和非结构化数据(如PDF文档、聊天记录),需通过ETL(抽取-转换-加载)工具清洗、标准化。
检索层:使用向量数据库(如Pinecone)或传统搜索引擎(如Elasticsearch),将用户问题转化为向量后,从知识库中召回Top N相关文档(通常3-5篇)。
生成层:LLM基于检索结果生成答案,部分系统会加入“验证模块”(如通过小模型检查答案与知识库的一致性)。
2.2 RAG的四大技术瓶颈:为什么企业需要进阶到Agent?
根据艾瑞咨询2025年发布的《LLM知识库问答系统成熟度报告》,企业在使用RAG时最常遇到的四大痛点:
静态知识库:知识库更新依赖人工审核,无法实时同步业务变化(如某零售企业的新品信息延迟24小时入库)。
多轮对话断裂:无法记住用户历史对话中的关键信息(如用户前一轮问“北京明天的天气”,后一轮问“那后天呢?”,系统需重新解析上下文)。
复杂任务无力:面对需要多步骤推理或多工具调用的任务(如“对比A、B两家供应商的价格、交期和服务评分,推荐最优选择”),RAG仅能提供零散信息,无法整合决策。
个性化缺失:难以根据用户身份(如普通员工vs管理层)调整回答深度(如普通员工需要“操作指南”,管理层需要“数据洞察”)。
三、Agent赋能下的LLM知识库问答:能力边界的突破
当LLM知识库问答系统升级为Agent后,其能力边界被大幅拓展。以下从技术架构、功能模块和典型场景三个维度,解析其核心升级点。
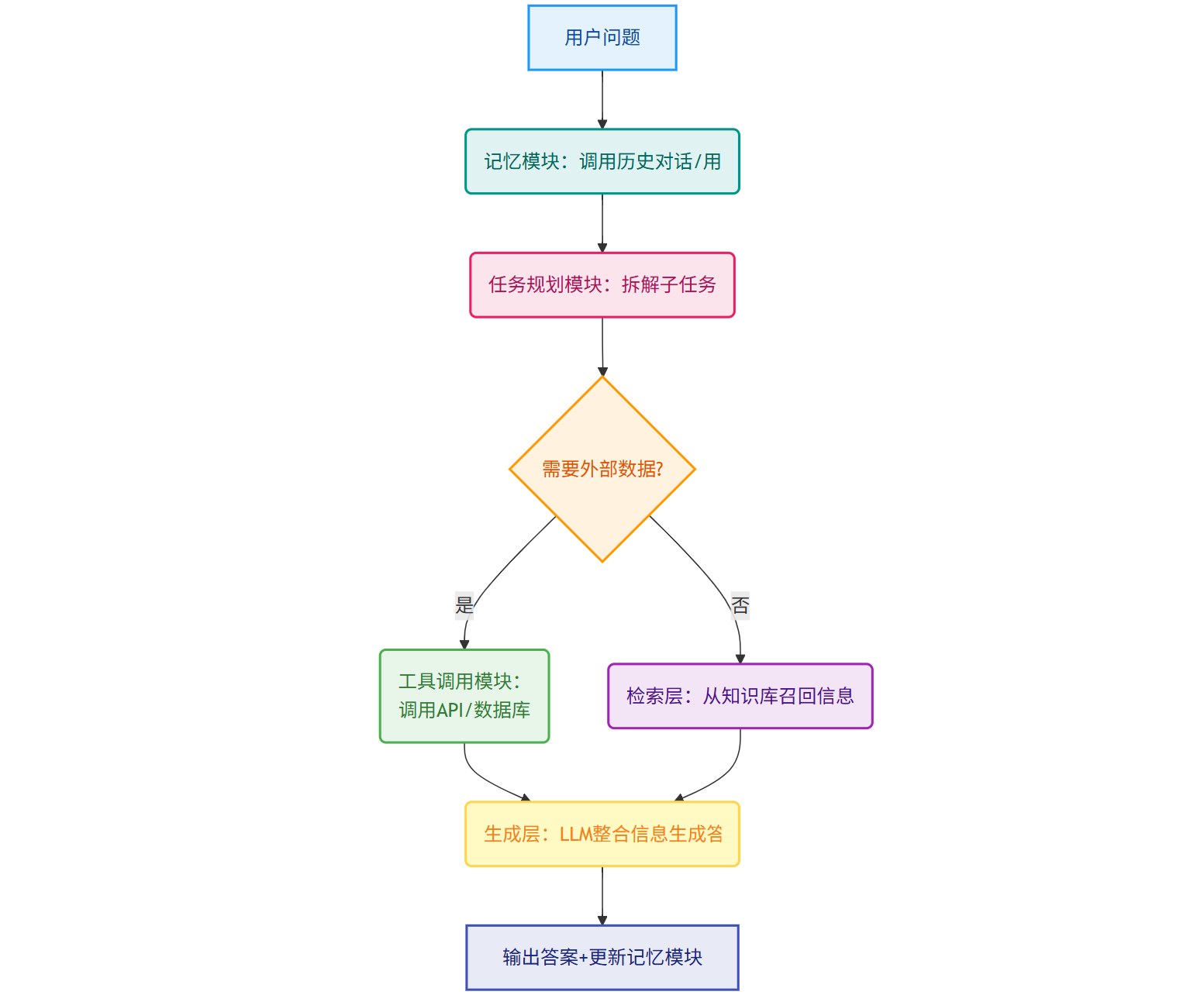
3.1 技术架构升级:从“检索-生成”到“记忆-规划-工具”的全链路增强
LLM知识库问答Agent的典型架构在RAG基础上增加了三大模块:
记忆模块:通过向量数据库(存储短期对话)+ 图数据库(存储长期知识图谱)+ 本地缓存(存储用户偏好),实现对对话历史、用户画像、业务规则的长期记忆。
任务规划模块:将复杂问题拆解为子任务(如“分析项目成本超支原因”拆解为“提取合同条款”“查询供应商报价”“对比历史数据”),并动态调整执行顺序。
工具调用模块:集成API接口(如天气API、物流API、CRM系统),允许Agent主动获取外部数据或执行操作(如自动发送提醒邮件)。
3.2 功能模块升级:四大能力的质的飞跃
对比RAG系统,LLM知识库问答Agent在以下方面实现了显著提升:
| 能力维度 | RAG系统 | LLMAgent |
|---|---|---|
| 知识更新时效性 | 依赖人工审核,更新周期长(小时/天级) | 支持实时接入业务系统(如ERP、CRM),分钟级同步 |
| 对话连贯性 | 仅支持单轮或简单多轮(3轮内) | 记忆用户历史对话(支持10轮以上长对话) |
| 任务处理能力 | 仅能回答“是什么”类问题 | 能解决“为什么”“怎么做”类复杂问题(如故障排查) |
| 个性化服务 | 统一回答模板 | 根据用户身份/场景调整回答深度(如员工vs管理层) |
3.3 典型场景:从“答疑”到“解决”的落地案例
某跨国制造企业的实践颇具代表性:
RAG阶段:员工询问“某型号设备的维修手册”,系统能从知识库中召回PDF文档链接,但无法解答“手册中第5页的部件编号对应哪个供应商”的问题。
Agent阶段:升级后的客服Agent不仅能调用手册内容,还能主动调用供应商管理系统(SMS)查询部件编号对应的供应商信息,并通过邮件将结果同步给用户,任务完成时间从“1小时”缩短至“2分钟”。
四、关键技术对比:RAG vs Agent在知识库问答中的差异
为了帮助企业更清晰地判断何时选择RAG、何时需要升级Agent,我们从技术实现、适用场景、成本投入三个维度进行对比。
4.1 技术实现对比
RAG:依赖检索算法(如DPR、ColBERT)和生成模型(如LLaMA、GPT-3.5),技术门槛集中在“如何提升检索准确率”和“如何减少幻觉”。
Agent:除RAG的技术外,还需掌握记忆管理(如记忆衰减策略)、任务规划(如强化学习优化子任务拆解)、工具调用(如API稳定性处理)等复杂技术,对工程能力要求更高。
4.2 适用场景对比
适合RAG的场景:知识更新频率低(如法律法规、产品说明书)、问题类型单一(如“查询某个参数”)、对实时性要求不高(如内部培训文档答疑)。
适合Agent的场景:知识更新频繁(如电商促销规则、金融实时行情)、问题复杂(如“分析客户流失原因并给出挽留策略”)、需要多系统协作(如跨ERP、CRM、OA的业务流程处理)。
五、最佳实践:企业如何从RAG平滑过渡到Agent?
对于已部署RAG系统但希望进阶的企业,以下是经过验证的最佳实践路径,分三步走:
5.1 第一步:评估现有RAG系统的瓶颈
通过用户调研和日志分析,明确当前系统的核心问题:是知识更新慢?对话断裂?还是复杂任务无力?例如,某教育企业发现70%的用户投诉集中在“无法回答跨学期课程安排对比”,这指向RAG的“多轮对话断裂”和“复杂推理无力”问题。
5.2 第二步:分阶段升级,优先解决高价值场景
不建议“一刀切”替换为Agent,而是从高价值场景切入,逐步扩展:
阶段1:增强RAG的记忆能力:为现有RAG系统添加“短期对话记忆”(如存储最近5轮对话),解决多轮对话断裂问题(可通过集成Redis实现,成本低且见效快)。
阶段2:试点Agent功能:选择1-2个高频复杂场景(如“客户投诉处理”),为LLM增加“任务规划”和“工具调用”模块(如接入CRM系统查询客户历史记录),验证Agent的价值。
阶段3:全链路升级:当试点场景验证成功后,逐步扩展至其他业务线,同步优化知识库更新机制(如实时接入业务数据库)和记忆模块(如图数据库存储长期知识)。
5.3 第三步:建立“人机协同”的优化机制
LLM知识库问答Agent并非“完全替代人类”,而是需要“人机协同”持续优化:
人工标注:对Agent回答错误的问题进行标注,反哺知识库和检索模型训练。
用户反馈:在对话界面增加“答案有用/无用”按钮,收集用户偏好数据,优化任务规划策略。
规则校准:针对敏感场景(如金融合规),设置“人工审核阈值”,当Agent生成的答案涉及高风险内容时,自动转交人工确认。
六、挑战与应对:LLM知识库问答系统的落地难点及解决方案
尽管从RAG到Agent的进阶为企业带来了显著价值,但落地过程中仍需解决以下挑战:
6.1 挑战一:记忆模块的“噪声干扰”
Agent的记忆模块会存储大量对话历史,其中可能包含错误信息(如用户口误)或过时信息(如已失效的促销规则),导致生成错误答案。
解决方案:引入“记忆验证机制”——通过小模型(如BERT微调)对记忆内容进行可信度评分,低置信度内容自动标记并触发人工审核;同时设置“记忆过期时间”(如促销规则仅保留30天)。
6.2 挑战二:工具调用的“稳定性风险”
Agent依赖的外部工具(如API接口)可能出现超时、参数变更等问题,导致任务失败。
解决方案:采用“工具熔断机制”——当某工具连续3次调用失败时,自动切换至备用工具或回退到RAG模式;同时记录工具调用日志,定期与工具提供方核对参数。
6.3 挑战三:个性化与隐私的平衡
Agent需要收集用户个人信息(如职位、历史行为)以提供个性化服务,但这可能引发隐私合规问题。
解决方案:遵循“最小必要”原则,仅收集完成任务所需的信息(如处理售后问题仅需用户订单号);对敏感信息(如身份证号)进行脱敏处理(如替换为“*”),并通过加密存储(如AES-256)保障安全。
七、结语:从RAG到Agent,是进化更是“重新定义智能”
如果说RAG是LLM知识库问答的“望远镜”——让LLM看得更远(接入外部知识),那么Agent就是“显微镜+指南针”——不仅让LLM看得更细(处理复杂任务),还能指引方向(主动解决问题)。这不是一次简单的技术升级,而是对“智能问答”本质的重新定义:从“信息搬运工”到“问题解决者”,从“被动响应”到“主动服务”。
下次当你和企业的LLM知识库系统对话时,不妨观察它是否能“记住”你上周的问题、是否能“协调”多个系统帮你完成任务、是否能“分析”数据并给出建议——这些细节里,藏着LLM从“工具”进化为“智能伙伴”的密码。


最新发布

热门推荐



