如何制作一个知识库?90%的团队都在第3步踩坑
据麦肯锡全球研究院的研究,知识工作者平均每周有19%的工作时间花在搜索和收集信息上——折算下来,一个50人的团队每年因"找不到信息"而白白损失的工时超过2000小时。更讽刺的是,这些信息往往就存在公司某个角落的文档、邮件或聊天记录里,只是没有人能快速找到它。
知识库,正是解决这一问题的核心基础设施。但现实中,大多数团队的知识库要么"建了没人用",要么"用着用着就荒废了"。问题不在于工具,而在于搭建思路从一开始就走偏了。这篇文章将从企业视角出发,拆解制作一个真正"能用起来"的知识库所需的完整方法论,并重点解析AI时代知识库的进化方向。
一、为什么你的知识库总是"建了没人用"
很多团队制作知识库的第一步,是打开一个工具,然后开始建文件夹——按部门分、按项目分、按时间分。这种做法的结果几乎是注定的:三个月后,文件夹层级越来越深,没人知道该把新内容放在哪里,搜索功能形同虚设,最终知识库变成了一个"信息坟场"。
这背后有三个根本原因。第一,把知识库当成"项目"而非"产品"来运营。项目有终点,产品没有。知识库需要持续的内容更新、用户反馈和结构迭代,而大多数团队在"建完"的那一刻就停止了投入。第二,结构设计违背了人的检索习惯。人类在查找信息时,往往不是按照"部门-项目-文档"这样的树状路径去找,而是通过关键词、语义联想或场景触发。一个按行政架构搭建的知识库,注定与实际使用场景脱节。第三,缺乏激励机制和贡献文化。知识输出是有成本的,如果没有明确的贡献规范和正向反馈,员工默认会选择不写。
理解了这三个根本原因,才能在接下来的搭建过程中真正避开坑。
二、制作知识库前必须想清楚的3个问题
在选工具、建结构之前,有三个战略性问题必须先想清楚。跳过这个环节直接动手,是大多数知识库失败的真正起点。
问题1:知识库服务谁?
个人知识库和企业知识库的逻辑完全不同。个人知识库服务于自己的思考和记忆,结构可以高度个性化;企业知识库服务于团队协作和组织传承,必须考虑多人使用的一致性。在企业场景中,还需要进一步细分:是服务于新员工快速上手(Onboarding知识库),还是服务于客服团队的实时查询(产品知识库),还是服务于整个组织的知识沉淀(企业大脑)?受众不同,知识库的颗粒度、更新频率和检索方式都会截然不同。
问题2:知识库存什么?
一个常见的误区是"把所有东西都放进来"。知识库不是网盘,内容越多不代表越有价值,反而可能因为噪音过多而降低检索效率。建议在建库初期明确"内容边界":哪些是核心知识(必须入库)、哪些是参考资料(可选入库)、哪些是过程文档(不入库)。一个清晰的内容边界,是保持知识库长期健康运转的关键。
问题3:知识库如何被检索到?
这是最容易被忽视的问题。知识库的核心价值不在于"存",而在于"找"。在设计知识结构时,需要同时考虑三种检索路径:目录导航(适合有明确目标的用户)、全文搜索(适合关键词检索)、语义推荐(适合模糊需求的用户)。AI时代的知识库,正是在第三种检索路径上实现了质的飞跃。
图:制作知识库前的决策路径
想清楚这三个问题之后,就可以进入具体的搭建步骤了。结构决策的质量,直接决定了后续所有工作的上限。
三、制作企业知识库的5个核心步骤
3.1 梳理知识资产,确定内容范围
第一步不是打开工具,而是做一次"知识盘点"。梳理现有的知识资产分布在哪里:是散落在个人电脑、企业微信、邮件附件,还是已有部分集中在某个共享盘?同时评估这些知识的质量:哪些是高频使用的核心知识,哪些是一次性的过程文档,哪些已经过时需要淘汰?
这个盘点过程,建议以"业务场景"为单位进行,而非以"部门"为单位。例如,"客户投诉处理"这个场景涉及客服、产品、法务三个部门,但它的知识需求是统一的。以场景为单位梳理,能让知识库的内容结构更贴近实际使用路径。
3.2 设计知识架构:树状、网状还是标签体系?
知识架构设计是整个搭建过程中技术含量最高的环节,也是最容易出错的地方。常见的三种架构模式各有适用场景:
树状结构适合内容边界清晰、层级关系明确的知识库,例如产品文档、操作手册。优点是导航直观,缺点是跨类别的知识难以关联,容易形成信息孤岛。
网状结构(双向链接)适合知识之间关联性强、需要频繁交叉引用的场景,例如研究笔记、战略分析。以Obsidian为代表的工具支持这种模式,但维护成本较高,更适合个人或小团队。
标签体系是企业知识库中最灵活的方案,允许一篇内容同时属于多个分类维度。例如,一篇"电商大促客服话术"既属于"客服"标签,也属于"大促"标签,还属于"电商"标签。标签体系的关键在于制定统一的标签规范,避免标签爆炸导致的混乱。
大多数企业知识库的最佳实践是**"树状主结构+标签辅助"**的组合方案:用树状结构提供清晰的导航框架,用标签体系实现灵活的跨维度检索。
3.3 选择合适的知识库工具
工具选型需要综合考虑团队规模、技术能力、安全要求和预算四个维度。以下是主流工具的横向对比:
表:主流知识库工具横向对比
| 工具类型 | 代表产品 | 适用规模 | 核心优势 | 主要局限 | AI能力 |
|---|---|---|---|---|---|
| 通用协作工具 | Notion、飞书 | 中小团队 | 易上手,生态丰富 | 企业级安全性不足 | 基础AI写作 |
| 专业文档平台 | Confluence | 中大型团队 | 权限管理完善,与Jira集成 | 界面较重,学习成本高 | 有限AI功能 |
| 开源自建 | Docsify、Wiki.js | 技术团队 | 零成本,高度定制 | 需要技术维护,无AI能力 | 需自行集成 |
| AI原生知识库平台 | BetterYeah AI等 | 中大型企业 | 多模态RAG、智能问答、私有化部署 | 实施成本相对较高 | 深度AI融合 |
选型的核心判断标准是:当前阶段是否需要AI智能检索能力?是否有私有化部署的安全合规要求? 如果两个问题的答案都是"是",那么传统的通用协作工具将无法满足需求,需要考虑AI原生知识库平台。
3.4 建立知识录入与审核流程
工具选好之后,最容易被忽视的是"知识怎么进来"的问题。一个没有明确录入规范的知识库,会在三个月内变成一个格式混乱、质量参差不齐的信息堆。
建议建立以下基本规范:
- 模板化:为常见知识类型(FAQ、操作手册、案例复盘)提供统一的文档模板,降低贡献门槛
- 责任制:每个知识域指定一名"知识负责人",负责内容的审核、更新和质量把控
- 更新触发机制:当相关业务发生变化时,自动触发对应知识文档的更新提醒,而非依赖人工记忆
图:企业知识库内容治理流程
3.5 AI赋能:让知识库从"存储"升级为"智能问答"
这是传统知识库搭建教程几乎从不涉及、但在2026年已经成为企业知识库核心竞争力的关键步骤。
传统知识库的使用模式是"人找知识"——用户需要知道大概去哪个目录找,或者用关键词碰运气。这种模式的效率上限很低,尤其是当知识库内容超过数百篇之后,搜索结果的噪音会急剧增加。
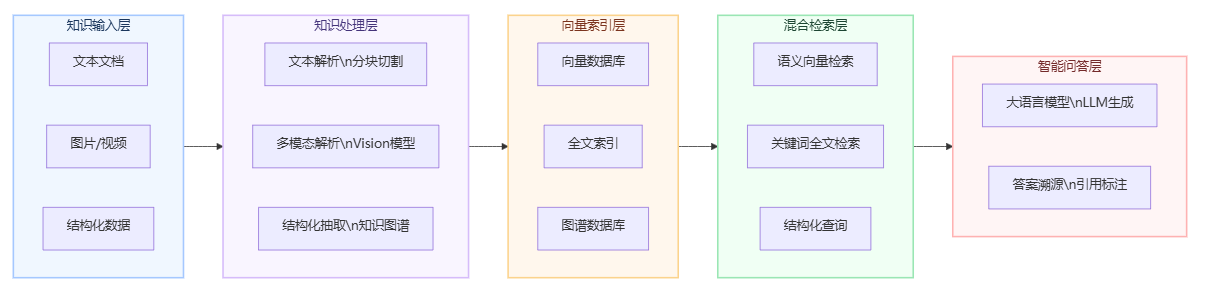
AI知识库的核心技术是RAG(检索增强生成):将知识库中的所有内容转化为向量表示,存入向量数据库;当用户提问时,系统先通过语义相似度检索最相关的知识片段,再由大语言模型基于这些片段生成准确的自然语言回答。这意味着用户可以用日常语言提问,而不需要记住任何关键词或目录路径。
四、AI时代的知识库:RAG技术如何让知识"活"起来
图:企业知识库——让组织知识汇聚为智能
4.1 传统知识库的三大技术瓶颈
传统知识库在技术层面存在三个难以突破的瓶颈:其一,只支持文本检索,图片、视频、音频中的知识无法被索引和检索;其二,关键词匹配而非语义理解,用户换一种问法就可能找不到答案;其三,知识孤岛难以打通,不同系统、不同格式的知识资产无法统一管理。
这三个瓶颈,在AI原生知识库平台上已经得到系统性解决。
4.2 多模态知识库:让图片和视频也能被"读懂"
企业的知识资产并不只是文字文档。产品图片、操作视频、设计稿、语音录音——这些非结构化的多媒体内容,往往包含了最核心的业务知识,却是传统知识库的盲区。
多模态知识库通过视觉理解模型(Vision)对图片和视频进行语义解析,将其中的内容转化为可检索的向量索引。以零售行业为例,商品图片可以被解析为"颜色、款式、材质、适用场景"等语义标签,客服人员在处理退换货时,可以直接用自然语言描述商品特征来检索相关政策,而不需要记住SKU编号。
4.3 混合检索策略:精准召回的关键
单一的向量检索并不是万能的。在实际应用中,向量检索+全文检索+结构化检索+知识图谱的混合策略,才能在不同类型的查询场景下都保持高召回率和高精度。
例如,当用户问"2025年Q4的退款率是多少"时,这是一个结构化数据查询,向量检索效果有限,需要结合结构化检索;当用户问"客户投诉产品质量问题应该怎么处理"时,这是一个语义理解型查询,向量检索效果最好。混合检索策略能够智能判断查询类型,自动选择最优的检索路径。
以BetterYeah AI为例,其知识库模块原生支持向量+全文+结构化+图谱四种检索策略的混合调用,并通过深度RAG融合确保答案的精准溯源——每一条AI回答都能追溯到具体的知识文档片段,避免大模型"幻觉"带来的错误信息。某大型金融保险企业借助这一能力,为10万+经纪人团队构建了覆盖6万余种产品的知识大脑,经纪人的知识学习效率提升了3倍以上,知识检索从"翻手册"变成了"直接问"。
图:AI知识库(RAG)技术架构
根据Gartner 2025年生成式AI知识管理应用创新指南,企业正在加速从传统文档管理向AI驱动的知识智能转型,生成式AI知识管理已成为新兴市场中增长最快的细分赛道。这意味着,今天选择构建AI原生知识库,不仅是效率的提升,更是在为未来的组织竞争力奠基。
五、知识库是组织的"第二大脑"
制作一个知识库,本质上是在为组织构建一套不依赖于个人记忆的"集体智能"系统。它的价值不在于上线的那一天,而在于每一次员工用它找到答案、每一次新人通过它快速上手、每一次AI基于它给出准确回答的积累之中。
从明确受众到设计架构,从选择工具到建立流程,再到引入AI智能检索——这五个步骤没有捷径,但每一步都有清晰的方法可循。真正让知识库"活"起来的关键,是把它当作一个需要持续运营的产品,而不是一个一次性完成的项目。一个工具,然后开始建文件夹——按部门分、按项目分、按时间分。这种做法的结果几乎是注定的:三个月后,文件夹层级越来越深,没人知道该把新内容放在哪里,搜索功能形同虚设,最终知识库变成了一个"信息坟场"。

最新发布

热门推荐



