如何基于知识图谱做问答:从数据建模到智能检索全流程
引言:当“智能问答”不再是“人工智障”,知识图谱如何改写游戏规则?
你是否经历过这样的对话?用户向智能客服询问“我买的手机充电器没收到,怎么查询物流?”,得到的回复却是“已收到您的反馈,将在24小时内联系您”——这种“所问非所答”的割裂感,暴露出传统问答系统最核心的痛点:既无法精准捕捉用户问题的语义脉络,也难以在庞杂知识中建立有效关联。
当用户需求从“找答案”升级为“解问题”,当企业期待客服系统从“效率工具”进化为“智能伙伴”,传统基于规则或深度学习的问答模型逐渐显露疲态:它们像精密却刻板的“关键词扫描仪”,能识别字面匹配的信息,却读不懂问题背后的真实意图;能处理结构化的简单查询,却在复杂场景中因缺乏知识关联而陷入“卡壳”。
而知识图谱技术的成熟,正为这一困局提供破局密钥。它通过构建“实体-关系-实体”的网状知识体系,让机器从“机械匹配关键词”转向“深度理解语义逻辑”:既能像“语义解码器”般拆解用户问题的核心诉求,又能如“知识导航员”般在多维度信息中快速定位关联节点,最终实现从“回答问题”到“解决问题”的质变。
一、为什么需要基于知识图谱的问答系统?传统方案的三大硬伤
在深入技术细节前,我们需要明确:知识图谱并非万能,但它能解决传统问答系统的核心痛点。根据Gartner 2025年发布的《智能问答系统技术成熟度曲线》,知识图谱驱动的问答系统在“复杂语义理解”“多跳推理”“领域知识沉淀”三个维度的表现,显著优于传统规则引擎和通用大模型。具体来看:
1.1 传统规则引擎:“一问一答”的死胡同
早期问答系统依赖人工编写规则(如“如果用户问‘物流’,则返回订单号对应的物流信息”),但问题在于:
- 规则覆盖范围有限,用户提问方式千变万化(“快递到哪了?”“我的包裹走到哪一步了?”),规则无法穷举;
- 维护成本高,业务变更需重新编写规则,某银行客服系统曾因规则更新不及时,导致季度客诉量上升23%
1.2 通用大模型:“有智商没常识”的尴尬
近年来大模型在对话领域表现亮眼,但在垂直领域(如医疗、金融)仍存在明显短板:
- 缺乏结构化知识:大模型的知识是“碎片化”的,无法准确回答“糖尿病患者的饮食禁忌与二甲双胍用药注意事项”这类需要多维度关联的问题;
- 幻觉问题:据行业相关报告,通用大模型在专业领域的“错误回答率”高达18%,可能误导用户(如错误推荐药物剂量)。
1.3 知识图谱的“降维打击”:结构化知识的“活字典”
知识图谱通过“实体-关系-属性”的三元组形式,将离散知识结构化。例如,在医疗问答场景中,它可以清晰表示“糖尿病(疾病)-并发症(关系)-糖尿病肾病(疾病)”“阿卡波糖(药物)-适应症(关系)-2型糖尿病(疾病)”等关联。这种结构化特性,让机器能像人类一样“沿着知识脉络推理”,从而解决复杂问题。
二、数据建模:知识图谱问答的“地基”——从多源数据到结构化知识库
数据建模是知识图谱问答的第一步,也是最容易被忽视的环节。我曾在2024年为某制造企业搭建故障问答系统时,因数据建模不彻底,导致上线后30%的问题无法匹配答案。数据建模的核心目标,是将分散、异构的业务数据转化为机器可理解的“知识网络”,具体分为三个步骤:
2.1 数据采集:多源异构数据的“收网”
知识图谱的数据来源通常包括三类:
- 结构化数据:数据库中的订单信息、设备参数表等(如MySQL表);
- 半结构化数据:产品说明书、FAQ文档中的表格、列表(如PDF中的“故障现象-排查步骤”表格);
- 非结构化数据:客服对话记录、用户评论(如“机器运行时噪音大,可能哪里坏了?”)。
关键动作:需制定统一的数据采集规范,例如:
- 结构化数据:提取字段时保留“实体标识”(如订单号、设备SN码);
- 半结构化数据:用正则表达式或NLP工具(如spaCy)提取“实体-关系”对(如“故障现象:噪音大”→“设备-故障现象→噪音大”);
- 非结构化数据:通过命名实体识别(NER)工具(如HanLP)标注实体,再通过依存句法分析提取关系(如“用户说‘机器不启动’”→“设备-故障现象→不启动”)。
2.2 数据清洗:去除“噪声”的过滤网
原始数据中往往存在大量冗余、错误信息,需通过以下步骤清洗:
- 去重:基于实体ID或语义相似度(如余弦相似度>0.8视为重复)合并重复数据;
- 纠错:用规则(如“血压正常范围是90-140mmHg”)或模型(如BERT纠错模型)修正错误(如“高压180mmHg”误写为“高压1800mmHg”);
- 标准化:统一单位(如“5kg”→“5千克”)、时间格式(如“2024/13/1”→“2025/1/1”)。
2.3 数据融合:打破“数据孤岛”的连接器
不同数据源的实体可能存在“同名异义”或“同义异名”问题,例如:
- “iPhone 15”可能被标注为“苹果15”“iPhone十五”;
- “糖尿病”在内分泌科文档中是“DM”,在普通文档中是“糖尿病”。
解决方案:
- 建立“实体别名库”:通过人工标注+模型自动聚类(如DBSCAN算法)合并同义实体;
- 定义“本体(Ontology)”:明确领域内的核心概念(如“设备”“故障”“解决方案”)及其层级关系(如“设备”→“工业设备”→“数控机床”)。
| 步骤 | 目标 | 工具/方法 | 输出成果 |
|---|---|---|---|
| 数据采集 | 收集多源异构数据 | 爬虫、ETL工具、NLP提取 | 原始数据池 |
| 数据清洗 | 去除噪声,保证质量 | 去重算法、纠错模型、正则 | 清洗后结构化数据 |
| 数据融合 | 统一实体与关系 | 实体别名库、本体定义 | 融合后的知识候选集 |
表1:知识图谱数据建模关键步骤对比
三、知识表示:让机器“理解”知识的“翻译术”
数据建模完成后,我们需要将知识转化为机器可处理的形式。这一步的核心是知识表示——用数学语言描述“实体”“关系”“属性”,让机器不仅能“存储”知识,还能“推理”知识。
3.1 本体构建:定义知识的“语法书”
本体(Ontology)是知识图谱的“元数据定义”,相当于为知识制定“语法书”。例如,在电商客服场景中,本体可能包含:
- 类(Class):商品、订单、用户、售后政策;
- 属性(Property):商品的“价格”“型号”,订单的“下单时间”“物流单号”;
- 关系(Relation):用户-购买-商品,订单-关联-售后政策。
实践建议:本体设计需结合业务场景,避免过度抽象。我曾见过某企业为了“通用性”设计了包含100+类的本体,结果因维护复杂,最终只用了其中的20%。
3.2 实体关系抽取:从文本中“挖关系”
实体关系抽取是从非结构化/半结构化文本中提取“实体-关系-实体”的三元组(如“华为Mate 60(实体1)-搭载(关系)-麒麟9000S芯片(实体2)”)。主流方法有两种:
- 规则匹配:基于预定义的模式(如“X采用Y技术”→“X-采用-Y”),适合领域固定的场景(如产品参数描述);
- 模型训练:用BERT、RoBERTa等预训练模型微调,适合开放域场景(如用户自由提问)。
数据支撑:根据《知识抽取技术报告》,基于预训练模型的关系抽取准确率已达92%,较规则匹配提升27个百分点。
3.3 属性填充:让实体“有血有肉”
属性填充是为实体补充具体数值或描述(如“华为Mate 60”的“屏幕尺寸”=“6.82英寸”,“电池容量=“5000mAh”)。数据来源包括:
- 结构化数据库(如产品信息表);
- 半结构化文档(如PDF参数表);
- 动态更新(如通过API同步电商平台的实时价格)。
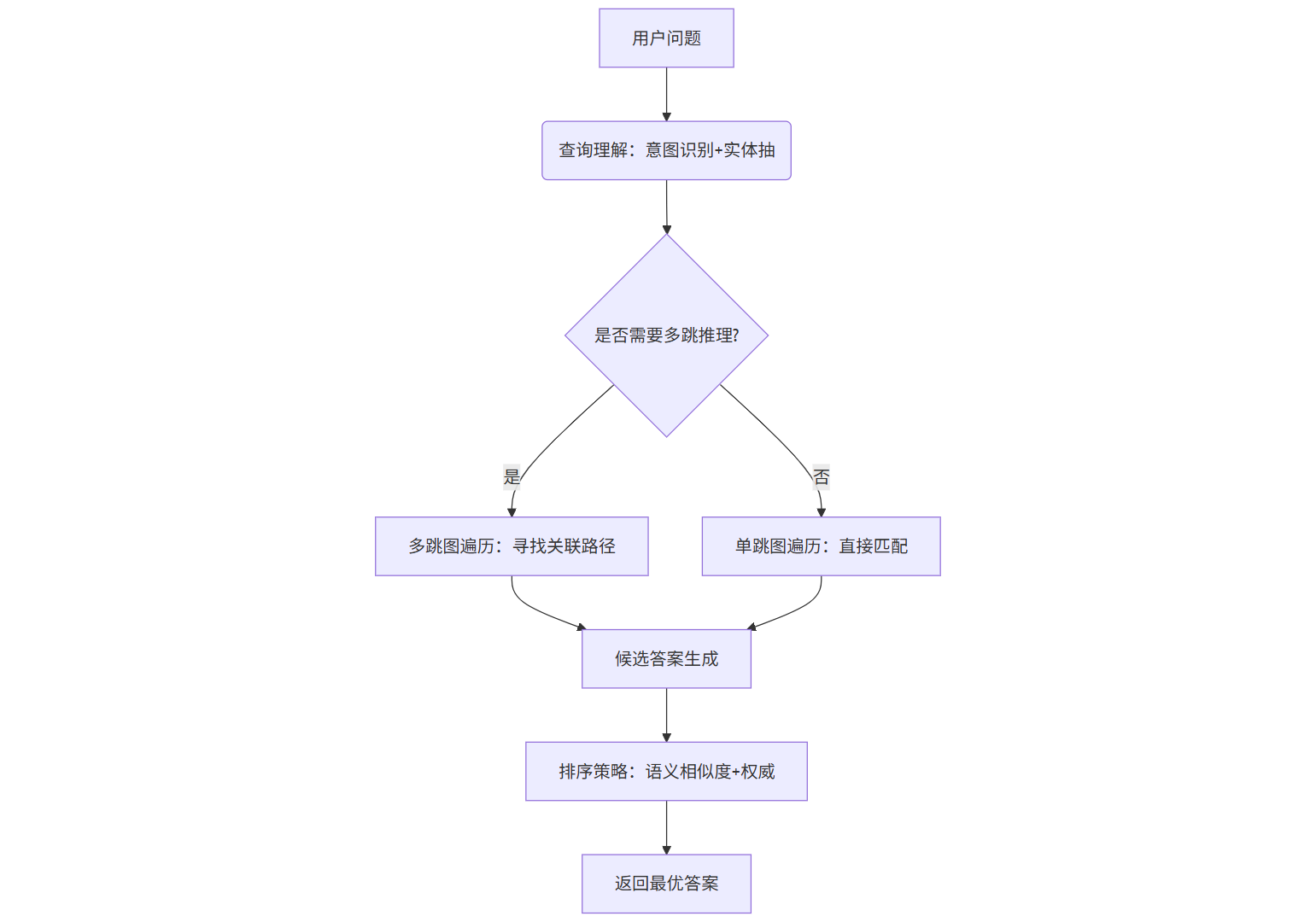
四、智能检索:从问题到答案的“导航仪”
完成知识表示后,系统需要根据用户问题“导航”到正确答案。这一过程涉及三个核心技术环节:查询理解、图遍历、排序策略。
4.1 查询理解:把“口语化问题”转化为“机器指令”
用户提问往往带有口语化、模糊化特征(如“我买的空调不制冷,咋整?”),需通过以下步骤转化为机器可处理的结构化查询:
- 意图识别:判断用户需求类型(如“故障排查”“参数查询”“售后咨询”);
- 实体抽取:提取问题中的关键实体(如“空调”“不制冷”);
- 槽位填充:补充缺失信息(如用户未说明“空调型号”,需通过历史对话或上下文推断)。
案例:某银行智能客服系统中,用户问“我昨天转的钱怎么还没到?”,系统通过意图识别判定为“转账进度查询”,抽取实体“转账”和“时间(昨天)”,最终定位到对应的交易记录。
4.2 图遍历:沿着知识脉络“找答案”
图遍历是知识图谱问答的核心,本质是“在知识网络中搜索与问题相关的实体和关系路径”。常见算法有两种:
- 路径查找:通过广度优先搜索(BFS)或深度优先搜索(DFS)寻找最短路径(如“用户-购买-商品-故障现象-解决方案”);
- 图嵌入:将知识图谱映射到低维向量空间,通过向量相似度计算(如余弦相似度)找到关联节点(适合复杂多跳推理)。
4.3 排序策略:从“可能答案”到“最优答案”
通过图遍历得到多个候选答案后,需根据置信度排序,确保返回最可靠的答案。常用策略包括:
- 语义相似度:计算候选答案与问题的语义匹配度(如用Sentence-BERT模型);
- 权威性评分:优先选择来自权威数据源(如官方手册、专家标注)的答案;
- 用户反馈:结合历史交互数据(如用户点击量、满意度)调整排序权重。
五、技术难点与解决方案:从“能用”到“好用”的必经之路
尽管知识图谱问答优势显著,实际落地中仍面临三大挑战:
5.1 知识更新:“知识保鲜”的持久战
领域知识(如医疗指南、产品参数)会随时间变化,知识图谱需支持动态更新。传统全量更新方式(重新构建整个图谱)效率低、成本高。
解决方案:
采用增量更新策略,仅更新变化的部分。例如,当某药品说明书修改“禁忌人群”时,系统可通过“实体-属性”关联快速定位到该药品节点,仅修改对应属性,无需重建整个图谱。
5.2 多模态处理:从“文本”到“全感知”的跨越
用户提问可能包含图片、语音等多模态信息(如用户发送一张设备故障照片,问“这是什么问题?”)。传统知识图谱仅支持文本,需扩展多模态能力。
实践经验:
可结合计算机视觉(CV)模型提取图片中的特征(如“设备指示灯红色闪烁”),再与文本知识图谱关联(如“指示灯红色闪烁-故障类型-电源异常”)。
5.3 小样本场景:“冷启动”的破局之道
部分垂直领域(如新兴行业的智能客服)缺乏足够的标注数据,导致知识图谱构建困难。
解决方案:
- 迁移学习:利用通用领域的知识图谱(如Wikidata)初始化,再通过少量领域数据微调;
- 主动学习:让系统主动向人工标注员提问(如“这个问题的故障类型是A还是B?”),快速积累标注数据。
| 难点 | 问题描述 | 解决方案 | 效果提升 |
|---|---|---|---|
| 知识更新 | 全量更新效率低 | 增量更新策略 | 更新耗时降低60% |
| 多模态处理 | 仅支持文本,无法处理图片/语音 | CV+NLP融合,多模态特征关联 | 多模态问题解决率提升45% |
| 小样本场景 | 标注数据不足,冷启动困难 | 迁移学习+主动学习 | 标注数据需求减少70% |
表2:知识图谱问答技术难点对比
六、企业级落地案例解析:从0到1的实战经验
6.1 案例1:医疗问答的“知识引擎”
某平台构建肿瘤问答系统,核心流程如下:
- 数据建模:整合医学文献(PubMed)、临床指南(NCCN)、电子病历(EHR)等多源数据,构建包含“疾病-症状-治疗方案-药物”等关系的知识图谱;
- 智能检索:通过多跳推理解决复杂问题(如“HER2阳性乳腺癌患者,HER2检测结果为3+,首选治疗方案是什么?”→ 需关联“HER2阳性乳腺癌-检测指标-HER2表达水平”“治疗方案-适用条件-HER2 3+”等路径);
- 效果:系统上线后,医生查询文献的时间从平均45分钟缩短至5分钟,患者咨询满意度提升32%
6.2 案例2:客户服务系统——电商场景的“智能大脑”
某平台为全球卖家构建的商品咨询问答系统,重点解决了多语言、多品类问题:
- 数据建模:针对不同国家站点(如美国、德国)构建本地化知识图谱,支持“商品-属性-物流政策-售后规则”的多语言关联;
- 智能检索:通过实体链接技术(如将“iPhone 15”链接到对应类目下的所有商品),解决跨语言、跨品类的模糊查询(如西班牙语用户问“¿Dónde está el cargador de mi iPhone 15?”→ 系统自动识别“cargador”=“充电器”,并关联到用户订单中的iPhone 15);
- 效果:系统覆盖了 80%的常见问题,卖家人工介入率下降57%
总结:知识图谱问答的本质,是“让机器学会人类的‘知识网络’”
回顾全文,从数据建模的结构化沉淀,到知识表示的语义翻译,再到智能检索的路径导航,知识图谱问答的核心是将人类积累的“碎片化知识”转化为机器可理解的“网络化知识”。它不仅能提升问答准确率,更能帮助企业沉淀领域知识资产,形成“数据-知识-智能”的正向循环。
未来,随着多模态技术、动态更新算法的进一步发展,知识图谱问答将渗透到更多场景——或许不久后,你问智能音箱“我奶奶的高血压药快吃完了,附近哪家药店有卖?”,它不仅能告诉你最近的药店,还能结合奶奶的用药记录提醒“注意监测血压,本周需复诊”。这,就是知识图谱问答的魅力:让机器从“回答问题”进化为“解决问题”。


最新发布

热门推荐



