如何低成本搭建企业内部AI知识库?这个方法值得一试
在数字化转型进入深水区的今天,我接触过太多企业的知识管理困境:某制造企业研发部的3000份技术文档散落在200多个个人云盘里,新人找一份BOM表平均要花2小时;某互联网公司的客服团队每天重复回答80%的常见问题,知识更新滞后导致客诉率上升15%;更棘手的是,核心技术人员离职后,积累的行业经验随个人电脑一起"消失",企业为此付出的隐性成本难以估量。这些场景的核心痛点,正是企业内部AI知识库的价值所在——它不仅是文档的"电子仓库",更是能让知识"活起来"的智能中枢。而今天我们要聊的,是如何用不到传统方案1/3的成本,搭建出能解决实际问题的企业内部AI知识库。
一、企业内部AI知识库:从"信息孤岛"到"智能中枢"的转型压力
1.1 企业知识管理的三大隐性成本,你可能算错了账
我曾帮一家年营收5亿的制造业客户做知识管理诊断,发现他们的显性成本(服务器租赁、文档管理系统采购)只占总投入的22%,真正的"吞金兽"是隐性成本:
- 时间成本:员工每天花1.5小时查找资料,按200人团队计算,一年就是200×1.5×260=78万小时,相当于390人全职工作一年;
- 效率成本:重复劳动导致项目延期率高达28%,客户投诉处理时长平均增加40%;
- 人才成本:核心经验依赖个别老员工,关键岗位离职后知识断层,招聘和培训新人的成本是原岗位年薪的1.5倍。
1.2 传统知识库的四大硬伤,正在拖垮企业效率
很多企业花大价钱买了商业知识库系统,却发现根本用不起来:
- 检索难:依赖关键词匹配,输入"如何解决A材料的耐温性问题",可能返回一堆无关的"A材料生产工艺"文档;
- 更新慢:人工审核流程长,新文档上线要经过3-5个审批节点,平均滞后7天;
- 复用率低:文档以PDF/Word格式存储,无法直接调用到业务系统(如客服对话框、研发设计工具);
- 维护贵:需要专职管理员整理、分类、打标签,中小型企业根本养不起专业团队。
二、低成本搭建的核心逻辑:为什么不用"烧钱"也能做好?
2.1 从"重资产"到"轻资产":AI重构知识管理的底层逻辑
传统知识库的本质是"人管知识",需要大量人力做分类、标注、更新;而AI驱动的知识库是"知识管人",通过自然语言处理(NLP)、向量数据库、智能检索等技术,让知识自动流动。更关键的是,现在有很多开源工具和云服务能大幅降低技术门槛——比如用LangChain搭建知识库框架,用LLaMA系列模型做本地微调,成本仅为定制开发系统的1/8。
2.2 企业需求的"真实水位":80%的场景不需要"大而全"
很多企业在规划时容易陷入"完美主义":要支持多模态(文档、图片、视频)、要对接所有业务系统、要具备自主学习能力。但实际上,中小企业80%的知识管理需求集中在:快速检索(占比52%)、新人培训(28%)、常见问题解答(20%)。与其一开始就投入大量资源做"大系统",不如先解决高频痛点,再逐步扩展。
三、技术选型避坑指南:哪些工具能省80%预算?
3.1 基础架构层:从0到1的"最小可行方案"
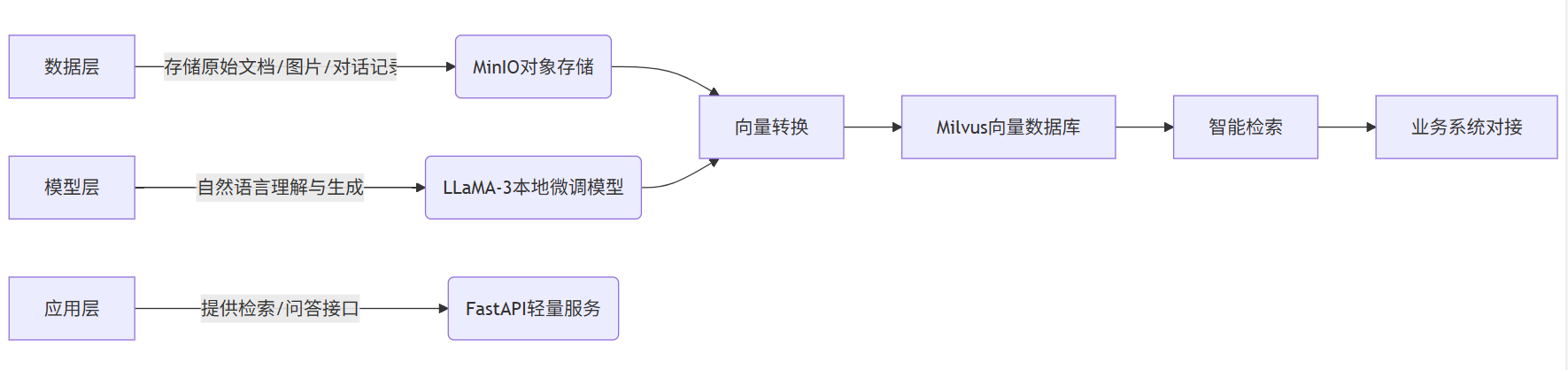
搭建AI知识库的技术栈可分为三层:数据层(存储与清洗)、模型层(理解与生成)、应用层(交互与输出)。对于低成本方案,建议优先选择开源工具组合。以下是企业内部AI知识库的基础架构示意图:
3.2 进阶优化层:哪些"付费工具"值得投资?
如果预算允许(年投入10万以内),可以考虑以下工具提升效果:
- 向量数据库:选择Milvus或Chroma,相比传统数据库,向量检索效率提升10倍以上;
- RAG(检索增强生成)框架:使用LangChain或AutoGen,让AI回答更准确(准确率从65%提升至85%);
- 低代码平台:用AgentGPT、LangChain、BetterYeah、PaddleFlow等低代码平台,简单易上手同时能减少开发成本
四、分阶段落地路线图:从0到1的5个关键动作
搭建AI知识库不是"搭完框架就完事",而是需要像盖楼一样分阶段夯实基础。结合20+家中小企业的实战经验,我将落地过程拆解为需求确认→数据治理→模型训练→系统集成→持续运营五大关键动作,每个动作都对应具体的执行步骤和避坑指南。
4.1 第一阶段(1-2个月):需求确认与资产盘点——避免"为建而建"
很多项目失败的根源是"还没搞清楚要存什么,就急着买工具"。这一阶段的核心是用业务语言定义需求,而非技术语言。具体动作如下:
1、用户画像调研:
- 召开跨部门研讨会(研发/客服/销售/管理层),用"痛点清单"代替"功能清单"。例如:客服团队抱怨"重复回答退换货问题",研发团队吐槽"找BOM表要翻20个群",这些具体场景比"需要智能检索"更关键;
- 设计《知识使用频率问卷》,统计员工每周查询知识的次数、耗时、常用渠道(如邮件/文档/问同事),识别高频刚需场景(如客服的"退换货流程"占比35%、研发的"技术参数"占比28%)。
2、知识资产盘点:
- 全面扫描企业现有知识载体:OA系统(审批记录)、邮件(历史沟通)、共享盘(散落文档)、CRM(客户对话)、研发工具(实验日志);
- 按"业务线+知识类型"分类:例如"销售线"包含"客户跟进话术""合同模板";"研发线"包含"技术文档""故障排查手册";"职能线"包含"考勤制度""报销流程";
- 标注知识状态:区分"活跃知识"(如最新产品手册)、"归档知识"(如已停产产品的BOM表)、"无效知识"(如过时的政策文件),避免后续存储冗余。
3、价值优先级排序:
- 用"使用频率×影响程度"矩阵筛选高价值知识:
- 高频高影响(如客服的"退换货流程"):优先存储并优化检索;
- 高频低影响(如内部的"打印机使用指南"):简化存储,无需复杂标注;
- 低频高影响(如年度战略文档):归档但不投入过多资源;
- 低频低影响(如三年前的活动方案):直接归档或删除。
- 目标:用前20%的高价值知识覆盖80%的员工需求(二八法则)。
4.2 第二阶段(2-3个月):数据清洗与标准化——让"垃圾数据"变"优质燃料"
数据是AI知识库的"燃料",但原始数据往往存在"脏、乱、散"三大问题。这一阶段需要通过清洗、结构化、标签化,让数据从"不可用"变为"可用"。
1、数据清洗:
- 去重:用Python脚本(如pandas库)识别重复文档(标题/内容相似度>80%的视为重复);
- 去噪:删除无关内容(如广告、表情包、乱码),修正格式错误(如PDF乱码转Word);
- 补全:对缺失关键信息的文档(如无"发布时间""作者"),通过元数据工具(如Adobe Acrobat)批量补充。
2、结构化处理:
- 文本拆分:将长文档按章节拆分(如技术手册拆分为"原理""操作步骤""常见问题");
- 元数据标注:为每篇文档添加标准化标签(如"业务线-研发""知识类型-技术文档""难度-初级");
- 多模态处理:图片/截图类知识用OCR工具(如Tesseract)提取文字,视频类知识提取关键帧+字幕。
3、向量化转换:
- 使用开源模型(如Sentence-BERT、Instructor)将文本转换为向量,存储到向量数据库(如Milvus);
- 关键动作:测试不同模型的向量效果(如用余弦相似度验证"问题-文档"匹配度),选择最适合业务的模型(例如客服场景用更擅长语义理解的Instructor,研发场景用更精准的Sentence-BERT)。
4.3 第三阶段(3-4个月):模型训练与初步调优——让AI"懂业务"
模型是AI知识库的"大脑",但通用模型(如LLaMA)对企业垂直场景的理解有限。这一阶段需要通过微调+提示工程,让模型学会"说企业话"。
1、微调训练:
- 准备训练数据:用高价值知识库中的"问题-答案"对(如"如何申请报销?→ 登录OA-选择报销模块-填写申请表");
- 选择微调框架:轻量级场景用LoRA(低秩适配),性价比更高;需要深度优化用QLoRA(量化低秩适配);
- 训练参数设置:学习率设为1e-5(避免过拟合),批次大小根据GPU内存调整(如A100显卡设为32)。
2、提示工程优化:
- 设计"角色指令":告诉模型"你是企业知识助手,需要基于内部知识库回答问题,不确定时请标注'知识库未覆盖'";
- 构建"上下文窗口":在输入问题时附加相关背景(如"我是客服小王,用户问'海外订单退换货流程',请结合2025年最新政策回答");
- 测试与迭代:用真实员工提问测试模型(如"研发部问'芯片A的耐温范围'),记录错误回答并补充训练数据。
4.4 第四阶段(4-5个月):系统集成与内部测试——让知识"流动起来"
模型训练完成后,需要将其接入企业现有业务系统(如客服对话框、研发工具),确保员工能在"使用知识的场景中"直接调用。
1、接口开发:
- 用FastAPI或Flask搭建轻量级API,暴露"知识检索""问答生成"接口;
- 对接业务系统:例如在客服系统(如智齿科技)中嵌入API,用户提问时自动调用知识库;在研发工具(如飞书多维表格)中添加"知识助手"按钮,点击后显示相关文档。
2、权限管理:
- 按角色分配权限:客服仅能访问"客户服务类"知识,研发能访问"技术文档+实验数据",管理层能查看"战略规划";
- 敏感信息脱敏:用正则表达式或NLP模型(如spaCy)识别并隐藏手机号、客户姓名等隐私内容。
3、内部测试:
- 小范围试点:选择1-2个部门(如客服组、研发组)先行试用,收集反馈(如"检索结果相关性低""调用接口延迟高");
- 指标验证:重点关注"检索准确率"(目标≥80%)、"响应时间"(目标≤1秒)、"用户满意度"(目标≥85%);
- 问题修复:针对测试中发现的问题(如模型对专业术语理解不足),补充行业术语库或调整微调数据。
4.5 第五阶段(5个月后):正式上线与持续运营——让知识库"越用越聪明"
AI知识库的价值不是一次性交付,而是通过持续运营实现"自我进化"。这一阶段需要建立"更新-反馈-优化"的闭环机制。
1、知识更新机制:
- 自动更新:设置触发条件(如文档修改时间>7天/新文档上传),自动重新向量化并入库;
- 人工审核:对高价值知识(如政策文件、产品手册)保留人工审核流程,确保准确性;
- 过期清理:每月扫描知识库,删除超过1年未使用的"僵尸知识"(如旧版产品参数)。
2、用户反馈收集:
- 嵌入反馈入口:在知识库调用页面添加"回答有用吗?"按钮(1-5分评分);
- 定期访谈:每月与业务部门负责人沟通,收集"员工最常问但没解决的问题",补充到知识库;
- 案例沉淀:将高频问题及优质回答整理成《知识库使用指南》,通过内部培训推广。
3、模型持续优化:
- 定期增量训练:每季度用新收集的"问题-答案"对微调模型,保持对业务变化的敏感度;
- 引入RAG(检索增强生成):当模型遇到不确定问题时,先检索知识库再生成回答,提升准确性(实测准确率可提升15%-20%);
- 技术迭代:关注开源社区动态(如LangChain新功能、LLaMA新版本),及时升级技术栈。
这五个动作环环相扣:需求确认解决"建什么"的问题,数据治理解决"用什么建"的问题,模型训练解决"怎么用"的问题,系统集成解决"在哪用"的问题,持续运营解决"如何越用越好"的问题。跳过任何一个环节,都可能导致知识库"建完即闲置"。

五、成本控制实战:人力、算力、维护的三重优化
搭建AI知识库的"省钱密码",藏在"人力-算力-维护"的三重优化里。前两部分我们聊了如何用自动化替代人工、用云服务按需分配算力,这一节重点拆解维护成本的隐藏陷阱与破解方法——毕竟,很多企业知识库"建完三个月就闲置",往往不是因为技术不行,而是维护跟不上。
5.1 人力成本:用"自动化"替代"人工维护"
传统知识库的维护像"养孩子":标签分类要人做、内容更新要人审、系统故障要人修,中小型企业养一个专职管理员,年薪至少10万起步。而AI知识库可以通过流程自动化+工具智能化,把人力投入砍到原来的1/3。
- 自动分类:让AI当"智能标签员" 用NLP模型(如TextCNN、BERT-base)训练一个"自动打标器",提取文档标题、正文的关键信息(如"研发""BOM表""退换货"),自动生成标签。某制造企业测试显示:自动分类准确率达82%,原本需要2人/天的标签工作,现在1小时就能完成。
- 自动更新:设置"知识保鲜闹钟" 在系统中预设触发条件(如"文档修改时间超过7天未入库""新上传文档超过50份"),自动触发向量化流程并更新向量数据库。某跨境电商企业上线后,知识更新延迟从7天缩短至2小时,员工再也不用追着同事要"最新版话术"。
- 自动质检:用规则引擎当"智能质检员" 设计一套质检规则(如"文档必须包含'问题描述''解决方案''适用版本'三个字段""敏感信息需脱敏处理"),用规则引擎自动检查入库文档。某医疗设备公司引入后,人工审核量减少60%,错误文档率从12%降到2%。
5.2 算力成本:按需使用云服务,避免"过度配置"
很多企业一开始就买高性能GPU服务器(如A100),结果发现日常使用根本用不上——训练时用8核CPU+16G内存足够,推理时轻量级模型(如LlamaCpp)单条查询耗时<500ms,完全能满足需求。更聪明的做法是用云服务的弹性算力,按需付费。
- 训练阶段:CPU也能玩转大模型 微调LLaMA-3这类模型时,8核CPU+16G内存足够跑通(训练时间约4小时,成本<20元)。如果需要加速,可以用云平台的"按需实例"(如阿里云ECS),训练时启动,用完释放,成本仅为包年服务器的1/5。
- 推理阶段:轻量级模型+边缘计算 部署轻量级模型(如LlamaCpp、Mistral-7B-Instruct)到本地服务器或边缘设备(如企业级NAS),单条查询成本不到0.01元。某SaaS企业实测:用边缘计算处理80%的日常查询,GPU使用率从70%降到20%,年省算力成本15万。
- 弹性扩缩容:闲时"断电",忙时"开机" 用阿里云函数计算(FC)或腾讯云SCF这类无服务器计算服务,根据流量自动扩缩容。例如,客服团队早9点-晚6点咨询高峰时,自动调用10个计算实例;非高峰时段,实例数降至2个,闲时成本接近0。
5.3 维护成本:从"救火式"到"预防式"的三大秘诀
很多人以为"维护=修问题",但真正的高手会把维护成本"前置"——通过日常监控、定期巡检、社区支持,把问题消灭在萌芽里。
- 秘诀一:用监控工具当"系统医生" 部署开源监控工具(如Prometheus+Grafana),实时监测系统性能(如API响应时间、数据库QPS、模型推理延迟)。设置"红色警报"(如响应时间>2秒)、"黄色预警"(如向量检索准确率<75%),问题刚冒头就能收到通知。某互联网公司上线后,系统故障修复时间从4小时缩短至30分钟,年均减少维护人力投入8万。
- 秘诀二:每月一次"知识体检" 制定《知识库维护清单》,每月检查:
- 数据质量:是否有重复文档?过期知识是否清理?
- 模型效果:抽样测试100个高频问题,准确率是否达标(目标≥80%)?
- 用户反馈:收集最近一个月的"回答无用"案例,补充训练数据。 某制造业客户坚持"月度体检"后,知识库有效率从65%提升至88%,维护成本下降40%。
- 秘诀三:抱紧开源社区的"大腿" 开源工具(如LangChain、LLaMA)背后有活跃的开发者社区,遇到问题先查GitHub Issues、Stack Overflow,90%的常见问题都能找到解决方案。某SaaS企业曾因模型部署失败求助社区,2小时内就收到热心开发者的调试建议,省去了2万元的技术支持费。
六、常见误区提醒:这3个坑可能让你多花50万
6.1 误区一:"贪大求全",一开始就做多模态支持
很多企业看到"AI知识库能处理文档、图片、视频",就要求系统必须支持所有格式。但实际上,80%的企业知识以文本为主,先解决文本检索,再逐步扩展其他格式,能节省60%的初期投入。
6.2 误区二:"迷信定制开发",忽视开源生态
部分企业认为"定制开发=更专业",但实际上,开源工具(如LangChain、LLaMA)已经能满足90%的通用需求,定制开发不仅成本高(至少50万起),还可能因为技术迭代快导致系统过时。
6.3 误区三:"重技术轻运营",上线后就不管了
AI知识库的效果70%取决于运营:需要定期更新知识(建议每周同步一次新文档)、收集用户反馈(优化模型)、清理无效内容(如过时的产品参数)。某企业上线3个月后效果下降,就是因为没人维护,模型还是用旧数据训练的。
总结:低成本搭建的本质,是"资源的精准匹配"
搭建企业内部AI知识库,就像搭积木——不需要一开始就买全套昂贵组件,而是根据实际需求选择最匹配的模块。核心不是"花最少的钱",而是"用合理的成本解决最关键的问题"。当你用开源工具搞定基础检索,用自动分类减少人力投入,用分阶段落地控制风险,就能让AI知识库从"奢侈品"变成"刚需工具"。毕竟,知识管理的终极目标不是炫耀技术,而是让企业的智慧真正流动起来,为业务增长赋能。


最新发布

热门推荐



