怎么高效收集AI知识库知识:数据获取的核心技术与实战路径
我们可能都遇到过这样的场景:投入大量资源搭建的AI知识库,最终输出却充满“幻觉”或信息碎片。问题根源往往不在模型本身,而在于知识收集的源头、方法和质量。当前企业知识库建设中,约67%的失败案例源于数据采集环节的缺陷——要么来源单一,要么缺乏结构化处理,导致知识“地基”不稳。
作为深耕智能知识管理的从业者,我亲历了多个从数据混乱到智能响应的转型案例。本文将系统拆解AI知识库知识收集的核心技术,涵盖多源数据整合、智能解析、冲突消解等全流程,助你构建真正“可被AI理解”的知识体系。
一、数据来源规划:构建多维度知识采集网络
知识收集的第一步是明确“采什么”和“从哪采”。碎片化堆砌资料只会生成低效知识库,需以场景需求为导向,结构化规划数据来源。
1.1 内部知识资产的系统化捕获
- 业务系统数据:从CRM、ERP等系统提取客户交互记录、产品参数、工单日志(如某车企整合维修工单构建故障诊断库)
- 文档资产挖掘:合同、技术手册、项目报告等,需通过API对接Confluence、SharePoint等平台实现自动同步
- 隐性知识转化:会议录音、专家访谈视频等,通过ASR语音转文本技术提取关键信息(例:某药企将研发讨论录音转化为药物实验要点库)
1.2 外部权威数据的智能抓取
- 开放数据集:Kaggle、UCI等平台的行业数据集(如金融风控模型需整合央行征信报告)
- 行业动态捕获:用Scrapy爬虫抓取监管政策、专利数据库、学术论文,并添加时效标签
- API生态集成:通过Google Analytics API获取用户行为数据,Facebook Graph API补充社交媒体画像
1.3 工具链自动化协同
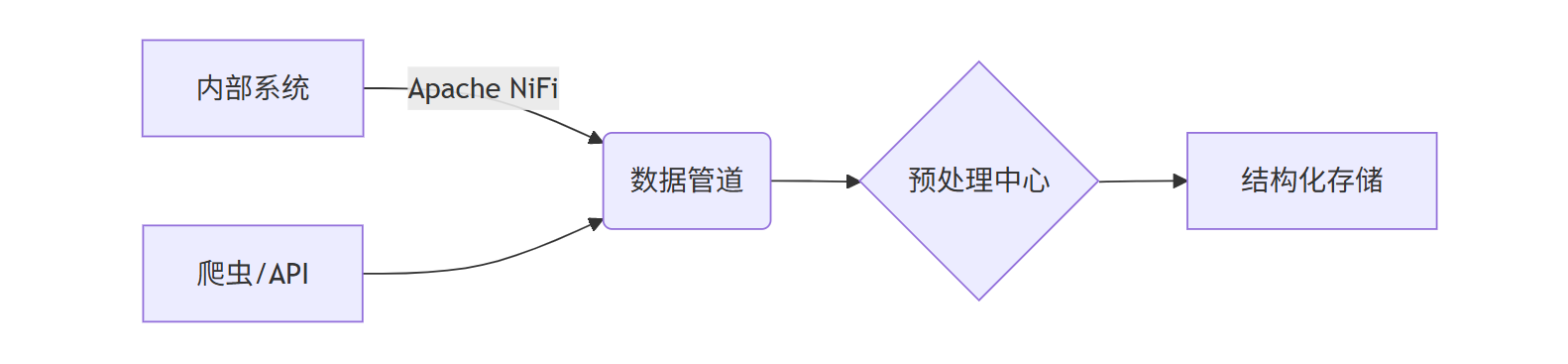
二、多模态数据处理:让机器“读懂”复杂知识形态
据IDC统计,企业80%的知识存储于非结构化数据中。传统文本处理已不足胜任,需多模态解析技术打通信息壁垒。
2.1 文本信息的深度提取
- PDF/Word解析:PyMuPDF提取文本与元数据,正则表达式匹配关键段落(例:法律知识库需精准抓取条款编号)
- 邮件/IM日志处理:NLTK分词+Spacy实体识别,抽取任务责任人、时间节点等结构化字段
2.2 图像与视频的知识转化
- OCR智能识别:Tesseract引擎解析扫描文档,CRNN模型处理表格(医疗知识库中化验单识别准确率达98%)
- 视频帧分析:FFmpeg抽帧+CLIP模型识别操作步骤(例:设备维修教学视频转SOP文档)
2.3 复杂文档的混合解析架构

三、数据清洗与知识增强:构建AI可理解的语义网络
原始数据需经“AI适配”改造。人能理解的文档AI未必能解析,需语义增强与冲突消解处理。
3.1 数据清洗核心四步骤
- 去重:SimHash算法识别相似文档(某电商知识库清洗后数据量减少37%)
- 异常值处理:箱线图法检测数值型异常(如金融数据中突变的利率值)
- 标准化:日期格式统一(YYYY-MM-DD)、单位转换(MPa→kPa)
- 缺失值填补:基于BERT的上下文预测填充(如设备参数表中的空缺字段)
3.2 元数据标准化增强
为知识添加“解释性标签”提升AI识别效率:
[示例] 汽车维修手册增强处理 原始文本: “涡轮增压器需每2万公里清洗” 增强后: { “实体”: “涡轮增压器”, “动作”: “清洗”, “频率”: “20000公里”, “适用车型”: “EA888发动机”, “可信度”: 0.93 //来源为厂商手册 }
3.3 语义关系结构化
四、知识冲突与质量保障机制
知识库中的矛盾内容会导致AI逻辑混乱。需建立三层质量防线确保知识一致性
4.1 冲突检测规则引擎
- 版本优先规则:新版本文件自动覆盖旧版参数
- 权威源加权:FDA标准权重高于供应商手册(医药知识库关键规则)
- 矛盾告警:NLP比对系统检测描述冲突(如“操作温度范围:-10℃~50℃” vs “极端环境限值:-5℃~45℃”)
4.2 可信度评分体系
| 指标 | 权重 | 评估方式 |
|---|---|---|
| 来源权威性 | 0.4 | 官方文档=1.0/论坛贴=0.3 |
| 时效性 | 0.3 | 近1年=1.0/3年以上=0.2 |
| 专家验证数 | 0.2 | 3位专家确认=1.0 |
| 跨源一致性 | 0.1 | 5个来源一致=1.0 |
4.3 自动化监控闭环
- 时效性扫描:定期标记过期政策(如某银行知识库每周自动禁用旧版合规条款)
- 缺口检测:基于用户未命中查询推荐补全(例:“5G基站功耗数据”搜索失败触发采集任务)
五、BetterYeahAI 知识库:企业的智能知识伙伴
BetterYeahAI 知识库是企业智能化知识管理的核心解决方案,其价值已在多个行业得到验证。它通过全面的知识获取与处理(支持多格式上传、智能索引、近义词管理、实时更新),实现知识的有效沉淀——如医疗化验单知识库,通过OCR精准识别与结构化填充,实现字段提取准确率98%,并利用BERT预测补全缺失值,矛盾值触发高效复核。同时,平台利用智能化的知识应用(精准训练、无缝集成AI Agent/Flow、灵活查询与命中测试),驱动知识精准赋能业务——某头部电商企业通过整合产品知识库、售后政策与用户高频咨询场景,实现客服知识检索效率提升85%,新人培训周期缩短60%,智能客服机器人在大促期间提供秒级精准响应,人工客服负担降低40%。最终,BetterYeahAI知识库达成高效的企业知识管理,将海量文档转化为AI可用知识,显著提升决策效率,助力构建专业客服AI,全面优化知识管理流程。作为连接企业知识与AI应用的关键桥梁,BetterYeah AI知识库正为零售、医疗等行业数字化转型提供坚实基础。
知识收集的价值本质:从信息仓库到决策引擎
AI知识库的竞争本质是知识获取能力的竞争。真正的智能不在于模型参数量,而在于如何将碎片化信息转化为可推理的语义网络。正如某车企工程师的感悟:“当我们用多模态解析技术将20年积累的维修视频转化为图谱关系后,故障诊断效率提升了9倍——这才是知识工程的复利效应。”
核心能力需聚焦三点:多源整合的宽度(内外部数据管道)、智能解析的深度(跨模态信息理解)、质量控制的严谨性(冲突消解机制)。未来知识库的进化方向,已从“存储知识”转向“持续捕获场景化知识流”。那些能高效消化设备传感器数据、用户反馈流、行业动态的知识系统,正在成为企业智能决策的“中枢神经”。

最新发布

热门推荐



