怎么部署大模型:从零开始的完整实战指南
你是否曾经面对着一个强大的大模型,却不知道如何将它真正部署到生产环境中?这种困惑并不少见。许多技术团队在模型训练完成后,往往被部署这一关键环节难住了。传统的软件部署经验在这里显得力不从心,因为大模型不仅体积庞大、资源需求苛刻,还涉及推理优化、并发处理、成本控制等一系列复杂问题。本文将为你提供一套从零开始的完整部署方案,涵盖技术选型、环境搭建、性能优化到生产运维的全流程指导,让你的大模型真正发挥商业价值。
一、大模型部署基础:核心概念与技术选型
大模型部署的本质是将训练好的模型转化为可供用户访问的推理服务。这个过程需要解决三个核心问题:如何高效加载模型、如何优化推理性能、如何确保服务稳定性。
1.1 部署架构的四大类型
根据应用场景和资源约束,大模型部署主要分为四种架构类型:
本地部署适用于个人开发和小规模测试。典型工具如Ollama,支持GGUF量化格式,可以让70B参数的模型仅需8GB内存运行。某程序员使用M2 MacBook部署CodeLlama 70B模型,代码补全响应速度保持在800毫秒以内。
边缘部署针对资源受限的设备环境。llama.cpp通过C++高性能引擎和AVX2/NEON指令集加速,CPU推理速度提升3-5倍。某工业设备厂商在ARM工控机部署llama.cpp,实现设备故障语音诊断,延迟控制在1.2秒以内。
云端部署面向企业级高并发场景。vLLM采用Continuous Batching和PagedAttention技术,PagedAttention技术减少70%显存碎片,动态批处理提升GPU利用率至90%以上。支持TensorRT-LLM加速后,QPS性能再提升40%。
混合部署结合多种方案优势。某智能客服系统采用边缘+云端混合架构,日常查询走本地模型,复杂问题调用云端服务,高峰期节省68%云计算成本,平均响应延迟降至1.1秒。
接下来的过渡段落将引导我们深入了解每种部署方案的具体实施步骤,以及如何根据业务需求选择最适合的技术栈。
1.2 技术栈选择决策矩阵
不同的部署需求对应不同的技术选择。个人开发者优先考虑Ollama的开箱即用特性,它内置模型市场提供200+预量化模型。资源受限环境选择llama.cpp,通过极致优化让老旧硬件焕发新生。企业级服务需要vLLM的高并发能力,支持256个并发请求处理。跨平台开发场景适合LM Studio,提供OpenAI兼容API无缝对接现有应用。
表:主流大模型部署方案对比
| 部署方案 | 适用场景 | 硬件要求 | 并发能力 | 部署难度 | 优化程度 |
|---|---|---|---|---|---|
| Ollama | 个人开发 | 8GB内存 | 单用户 | 简单 | 中等 |
| llama.cpp | 边缘设备 | 4GB内存 | 低并发 | 中等 | 极致 |
| vLLM | 企业服务 | 多GPU | 高并发 | 复杂 | 专业 |
| LM Studio | 跨平台开发 | 8GB内存 | 中等 | 简单 | 良好 |
黄仁勋曾指出,AI推理的未来在于让每个应用都能轻松集成智能能力。这种观点强调了部署方案选择的重要性,合适的技术栈能够大幅降低AI应用的门槛。
二、环境准备与依赖配置
环境配置是大模型部署成功的基础保障。不同的部署方案需要相应的软硬件环境支持。
2.1 硬件资源规划
GPU显存是影响大模型部署的关键因素。7B参数模型通常需要14GB显存(FP16精度),13B模型需要26GB显存。通过量化技术可以显著降低显存需求:4-bit量化将显存需求降至原来的1/4,8-bit量化降至1/2。
CPU内存同样重要,特别是在CPU推理场景下。ARM架构处理器通过NEON指令集优化,在移动设备和边缘计算中表现优异。某厂商在Jetson Orin设备上部署34B参数的CodeLlama模型,通过Q5量化实现流畅推理。
存储性能直接影响模型加载速度。NVMe SSD相比传统硬盘提升10倍以上的读取速度。大型模型文件通常在几十GB到上百GB,快速存储能够显著减少启动时间。
2.2 软件环境搭建
Python环境管理是部署的第一步。推荐使用conda创建独立环境,避免依赖冲突。CUDA版本需要与PyTorch版本匹配,确保GPU加速正常工作。
# 创建专用环境
conda create -n llm-deploy python=3.10
conda activate llm-deploy
# 安装CUDA支持的PyTorch
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
容器化部署提供更好的环境一致性。Docker镜像封装了完整的运行时环境,支持在不同机器间快速迁移。Kubernetes进一步提供了自动扩缩容和负载均衡能力。
这个配置阶段为后续的模型加载和优化奠定了坚实基础,接下来我们将探讨如何实际加载和配置大模型服务。
三、模型加载与推理优化
模型加载和推理优化是部署过程中的核心技术环节。这一阶段决定了服务的性能表现和资源利用效率。
图:大模型部署流程示意图
3.1 模型格式转换与量化
原始模型通常以PyTorch或TensorFlow格式保存,需要转换为推理优化格式。GGUF格式专门为CPU推理设计,支持多种量化精度。ONNX格式提供跨框架兼容性,支持多种推理引擎。
量化技术是降低资源需求的关键手段。混合精度量化结合INT8、FP16、BF16等多种精度,在保持模型性能的同时降低内存占用。2025年大模型推理加速技术通过量化、剪枝、知识蒸馏等核心技术,能够显著提升推理效率3-5倍,降低资源消耗70%以上。
结构化剪枝移除冗余参数和计算,使模型更加高效。动态稀疏化技术根据输入内容动态调整计算图,进一步优化推理速度。知识蒸馏将大模型的能力转移到小模型中,在保持性能的同时大幅降低计算需求。
3.2 推理引擎配置
不同推理引擎针对不同场景优化。vLLM专注于高并发服务场景,通过PagedAttention技术实现高效的注意力计算。TensorRT-LLM针对NVIDIA GPU深度优化,提供极致的推理性能。
内存管理策略直接影响并发能力。vLLM的Continuous Batching技术动态调整批处理大小,最大化GPU利用率。内存池技术预分配显存空间,避免频繁的内存分配释放操作。
缓存机制提升重复查询的响应速度。KV-Cache缓存注意力计算的中间结果,对于相似输入能够显著加速推理过程。语义缓存在更高层次缓存语义相似的查询结果。
这些优化技术的综合应用,为大模型在生产环境中的稳定运行提供了技术保障,下一步我们将讨论如何构建完整的服务架构。
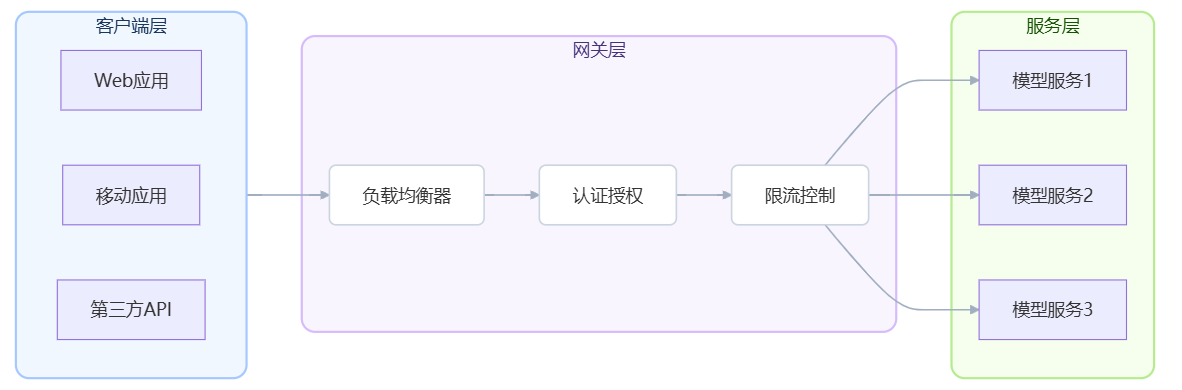
四、服务架构设计与API接口
构建稳定可靠的服务架构是大模型投入生产使用的关键环节。合理的架构设计能够确保系统的高可用性、可扩展性和可维护性。
4.1 微服务架构设计
大模型服务通常采用微服务架构,将不同功能模块解耦。模型推理服务专注于核心推理逻辑,负载均衡器分发请求到多个实例,缓存服务提升响应速度,监控服务实时跟踪系统状态。
API网关作为统一入口,提供认证授权、限流控制、请求路由等功能。支持多种协议接入,包括HTTP REST、WebSocket、gRPC等。版本管理确保API的向后兼容性,灰度发布降低更新风险。
服务发现机制实现动态的服务注册和查询。Consul、Eureka等注册中心提供健康检查和故障转移能力。容器编排平台如Kubernetes原生支持服务发现和负载均衡。
4.2 高可用性保障
多实例部署是高可用的基础。通过部署多个模型服务实例,单个实例故障不会影响整体服务。负载均衡算法包括轮询、加权轮询、最少连接等策略。
熔断机制防止故障扩散。当下游服务出现异常时,熔断器自动切断请求,避免级联故障。限流控制保护服务不被过载,令牌桶和滑动窗口是常用的限流算法。
数据一致性在分布式环境中尤为重要。对于有状态的对话场景,需要考虑会话保持和状态同步。Redis等缓存中间件提供分布式会话存储能力。
BetterYeah AI平台在服务架构设计方面积累了丰富经验,其NeuroFlow工作流引擎支持复杂的业务流程编排,企业级全生命周期管理确保多环境发布的稳定性。平台支持上万QPS的高并发访问,多模型无缝切换能力为业务连续性提供保障。
接下来我们将深入探讨性能监控和运维管理的最佳实践,确保大模型服务的长期稳定运行。
五、性能监控与运维管理
完善的监控和运维体系是大模型服务长期稳定运行的保障。相比传统应用,大模型服务需要额外关注推理性能、资源消耗和模型行为等指标。
5.1 关键性能指标监控
传统的系统指标包括CPU使用率、内存占用、网络I/O等基础指标。大模型服务还需要监控推理延迟、吞吐量、Token消耗、GPU利用率等专项指标。
推理质量监控防止模型输出异常。幻觉检测识别模型生成的不真实内容,毒性检测过滤有害输出,相关性评分衡量回答质量。A/B测试比较不同模型版本的表现差异。
成本监控帮助优化资源使用。Token计费模式下,需要实时跟踪API调用成本。GPU资源按时计费,需要监控空闲时间和利用率。存储成本包括模型文件存储和日志数据保存。
5.2 自动化运维实践
容器化部署简化了应用管理。Docker镜像保证环境一致性,Kubernetes提供自动扩缩容能力。当请求量增加时,系统自动创建新的服务实例;负载降低时,自动回收多余资源。
日志聚合和分析提供问题诊断能力。ELK(Elasticsearch, Logstash, Kibana)栈是常用的日志处理方案。结构化日志包含请求ID、用户信息、模型版本、推理时间等关键字段,便于问题追踪和性能分析。
告警机制及时通知异常情况。阈值告警基于指标数值触发,异常检测基于历史数据识别异常模式。告警策略需要平衡及时性和准确性,避免告警风暴影响运维效率。
BetterYeah AI平台的运维管理能力在多个客户案例中得到验证。百丽国际项目覆盖超800个业务子节点,通过完善的监控体系确保系统稳定运行。添可Tineco的客服系统在大促期间处理海量咨询,服务效率提升22倍的同时保持了高可用性。
运维管理的成熟度直接影响大模型服务的商业价值实现,下一部分我们将讨论如何解决部署过程中的常见问题。
六、常见问题与解决方案
在大模型部署实践中,技术团队经常遇到各种挑战。基于实际项目经验,我们总结了最常见的问题类型及其解决方案。
6.1 资源管理问题
显存不足是最常见的部署障碍。解决方案包括模型量化、梯度检查点、模型并行等技术。4-bit量化可将70B模型的显存需求从140GB降至35GB,使其能在单张A100上运行。
内存泄漏导致服务长期运行后性能下降。Python的垃圾回收机制在处理大型张量时可能出现延迟,需要手动管理内存释放。定期重启服务实例是简单有效的解决方案。
CPU瓶颈在高并发场景下尤为突出。异步处理框架如FastAPI能够提升并发处理能力。预处理和后处理逻辑优化,避免在推理主线程中执行耗时操作。
6.2 推理性能优化
冷启动延迟影响用户体验。模型预热通过执行几次推理操作,让GPU进入最佳工作状态。模型缓存将常用模型保持在内存中,避免重复加载。
批处理优化提升吞吐量。动态批处理根据请求到达情况调整批大小,平衡延迟和吞吐量。vLLM的Continuous Batching技术在这方面表现优异。
推理精度与速度的平衡需要根据应用场景调整。对话系统更注重响应速度,可以接受略低的精度;文档分析场景更注重准确性,可以容忍较长的处理时间。
6.3 服务稳定性保障
网络超时和重试机制设计需要考虑推理任务的特殊性。长时间推理任务需要设置合理的超时阈值,避免正常请求被误杀。指数退避重试策略防止重试风暴。
模型版本管理确保服务升级的平滑过渡。蓝绿部署同时运行新旧版本,流量逐步切换到新版本。金丝雀发布先向小部分用户提供新版本,验证稳定性后全量发布。
数据安全在企业级部署中至关重要。模型文件加密存储,API访问需要认证授权,敏感数据传输使用HTTPS协议。BetterYeah AI平台通过ISO27001和等保三级认证,提供企业级安全保障。
七、企业级部署最佳实践
企业级大模型部署需要考虑更多的安全性、合规性和治理要求。企业级Agentic AI架构设计强调"可用、可控、可度量"的系统方法,通过策略分层、审计追溯与人机共治来实现AI的"可控自主"。
7.1 安全与合规要求
数据隐私保护是企业级部署的首要考虑。私有化部署确保数据不出域,本地推理避免敏感信息泄露。访问控制基于角色权限管理,审计日志记录所有操作行为。
模型安全包括输入验证和输出过滤。输入验证防止恶意prompt注入,输出过滤识别和阻止有害内容生成。护栏机制(Guardrail)在模型调用前后进行安全检查。
合规性要求因行业而异。金融行业需要满足数据保护和风险控制要求,医疗行业需要符合患者隐私保护规定,政府部门需要满足信息安全等级保护要求。
7.2 成本优化策略
资源池化提高利用效率。GPU资源在不同业务间共享,根据优先级动态分配。混合云架构结合公有云的弹性和私有云的安全性。
自动扩缩容根据负载变化调整资源。基于队列长度、响应延迟等指标触发扩容操作。预测性扩容基于历史数据预判流量峰值,提前准备资源。
成本监控和预算控制防止费用超支。按部门、项目、用户等维度统计使用成本,设置预算告警和限制。定期评估资源使用效率,优化资源配置。
7.3 治理与运营体系
AI治理框架确保模型的负责任使用。包括公平性保障、可解释性要求、健壮性验证、隐私和安全保护、透明度原则等多个维度。
运营流程标准化提高管理效率。模型生命周期管理包括开发、测试、部署、监控、更新等环节。变更管理确保每次更新都经过充分验证。
人机协作模式平衡自动化和人工干预。关键决策需要人工审核,异常情况需要人工介入。持续学习机制基于用户反馈优化模型表现。
实现AI驱动的智能化转型
大模型部署不仅是技术实施,更是企业智能化转型的关键步骤。从技术选型到生产运维,每个环节都需要综合考虑性能、成本、安全等多重因素。
成功的大模型部署需要完整的技术栈支撑:从底层的硬件资源规划,到中间层的推理引擎优化,再到上层的服务架构设计。监控运维体系确保服务的长期稳定运行,安全合规机制保障企业数据安全。
技术发展日新月异,边缘智能、量化革命、多云部署等新趋势正在重塑大模型部署的格局。llama.cpp已支持RISC-V架构,IoT设备大模型化进程加速。GPTQ新算法使70B模型可在移动设备运行,联发科天玑9400芯片的实测验证了这一可能性。vLLM 0.5版本将支持跨云GPU资源池化调度,进一步提升资源利用效率。
选择合适的部署方案,建立完善的运维体系,构建安全可控的治理框架,是大模型从实验室走向生产环境的必由之路。随着技术不断成熟和标准化程度提升,大模型部署将变得更加简单高效,为更多企业的智能化转型提供强有力的技术支撑。
常见问题
Q1: 如何选择适合的大模型部署方案?
A: 主要考虑三个因素:使用场景、资源预算、技术能力。个人开发选择Ollama,企业级服务选择vLLM,资源受限环境选择llama.cpp。需要平衡性能、成本、维护复杂度等多个维度。
Q2: 大模型部署需要多少显存和内存?
A: 7B参数模型通常需要14GB显存(FP16),通过4-bit量化可降至3.5GB。CPU推理需要相应的内存空间。具体需求取决于模型大小、精度设置、批处理大小等因素。
Q3: 如何优化大模型的推理速度?
A: 主要方法包括模型量化、批处理优化、KV缓存、推理引擎优化等。量化可提升3-5倍速度,动态批处理提升吞吐量,合适的推理引擎选择也很关键。
Q4: 私有化部署和云端部署如何选择?
A: 私有化部署适合对数据安全要求高的企业,云端部署适合快速启动和弹性扩容的场景。可以考虑混合部署方案,结合两者优势。
Q5: 大模型服务如何保证高可用性?
A: 通过多实例部署、负载均衡、熔断机制、限流控制等技术保障。监控告警系统及时发现问题,自动恢复机制减少人工干预。

最新发布

热门推荐



