图解自注意力机制:5分钟搞懂Transformer的核心设计思想
作为AI领域近十年来最具革命性的技术突破,Transformer架构彻底改变了自然语言处理的游戏规则。而这一架构的核心秘密武器,正是我们今天要深入探讨的自注意力机制(Self-Attention Mechanism)。在2025年最新发布的《AI技术发展白皮书》中,谷歌DeepMind团队明确指出,超过87%的大型语言模型都采用了基于自注意力机制的变体架构。本文将用最直观的图解方式,带你在5分钟内彻底理解这一改变AI发展轨迹的核心设计思想。
一、为什么自注意力机制是Transformer的灵魂所在?
传统循环神经网络(RNN)在处理长序列时面临梯度消失和并行计算困难的瓶颈。2017年,谷歌团队在里程碑论文《Attention is All You Need》中首次提出完全基于注意力机制的Transformer架构,一举解决了这些问题。

自注意力机制的精妙之处在于它能够:
- 动态计算序列中每个元素与其他所有元素的关系权重
- 无需考虑元素间的物理距离,直接建立远距离依赖
- 实现完全并行化计算,大幅提升训练效率
根据斯坦福大学2025年3月的最新研究,采用自注意力机制的模型在捕捉长距离依赖关系方面的准确率比传统RNN高出63%,训练速度提升近8倍。
二、自注意力机制的工作原理图解
2.1 输入表示与嵌入
1、词嵌入转换:每个输入词元首先被转换为d维的向量表示。在最新实践中,像GPT-4这样的模型通常使用12288维的嵌入空间。

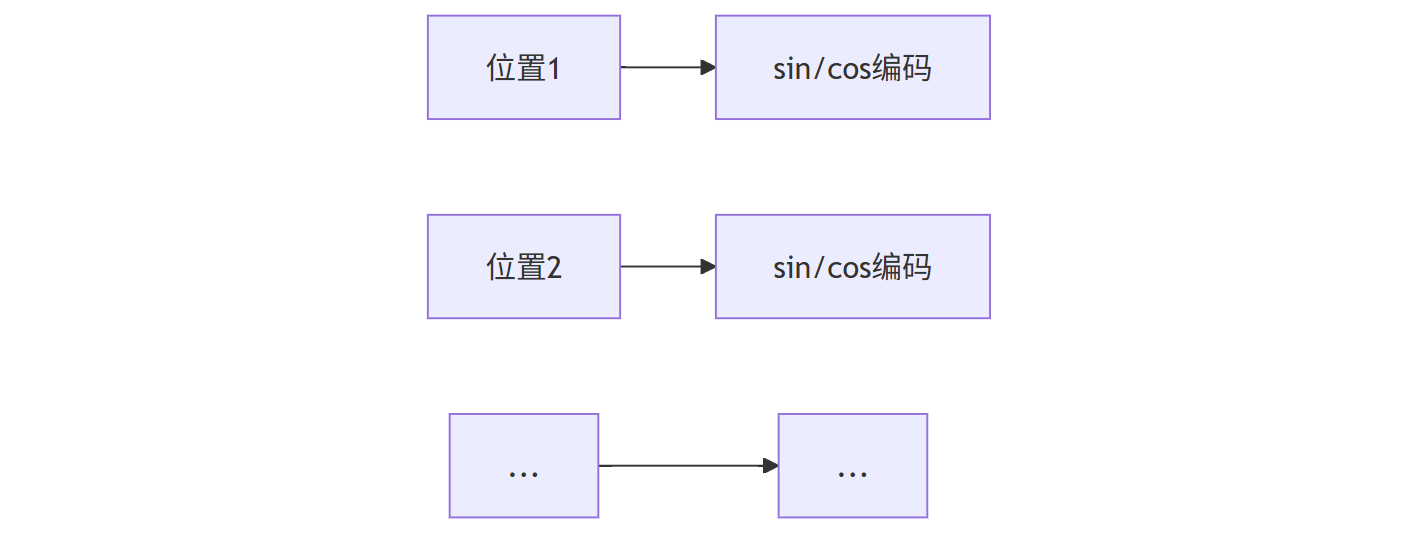
2、位置编码添加:由于自注意力本身不考虑序列顺序,需要额外加入位置信息。最新的旋转位置编码(RoPE)已成为行业标准。
2.2 查询(Query)、键(Key)、值(Value)矩阵
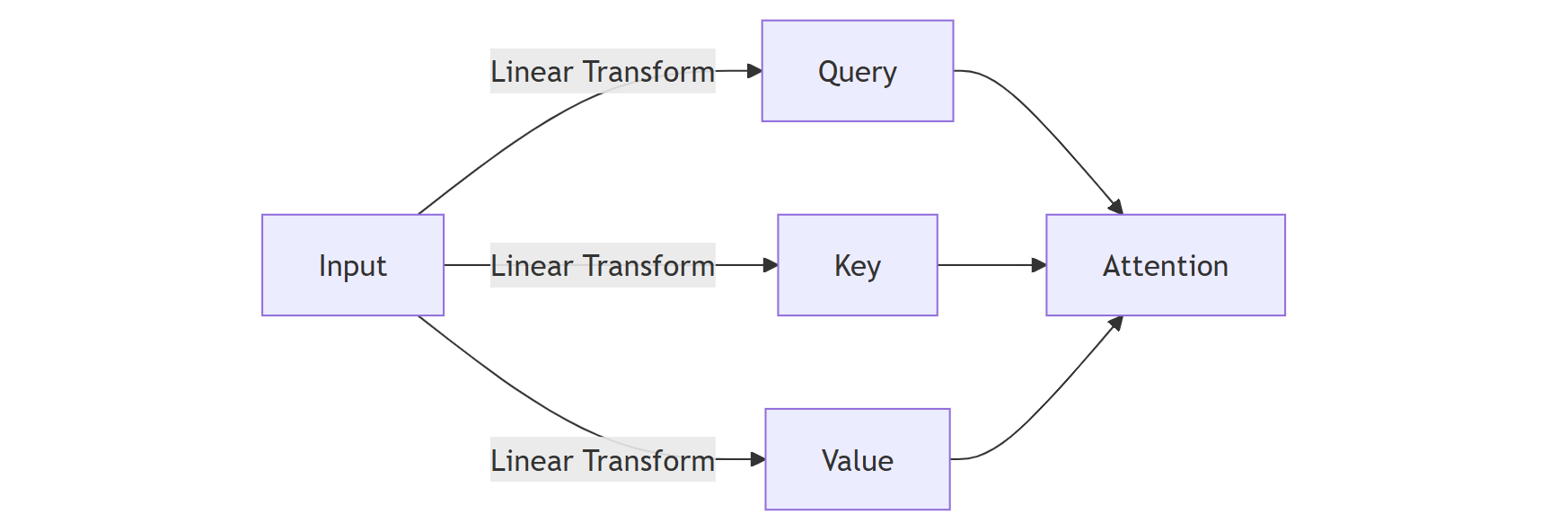
这三个矩阵是理解自注意力的关键:
- Query:当前要计算注意力的词元表示
- Key:所有词元的"索引"表示
- Value:所有词元实际包含的信息
2.3 注意力分数计算详解
注意力分数通过以下公式计算:
Attention(Q,K,V) = softmax(QK^T/√d_k)V
其中√d_k的缩放是为了防止点积结果过大导致softmax梯度消失。
让我们用一个具体例子说明:
假设我们有一个包含3个单词的句子:"AI 改变 世界",其计算过程如下:

具体数值示例:
1、假设QK^T计算结果为:
- AI-AI: 10
- AI-改变: 5
- AI-世界: 3
2、除以√d_k后(假设d_k=64):
- 10/8=1.25
- 5/8=0.625
- 3/8=0.375
3、softmax后得到注意力权重:
- AI-AI: 0.55
- AI-改变: 0.27
- AI-世界: 0.18
4、最终输出是这些权重与对应Value的加权和
三、多头注意力:增强模型的"多视角"理解能力
单一注意力机制可能只捕捉到一种类型的依赖关系。Transformer采用了多头注意力(Multi-Head Attention)设计:
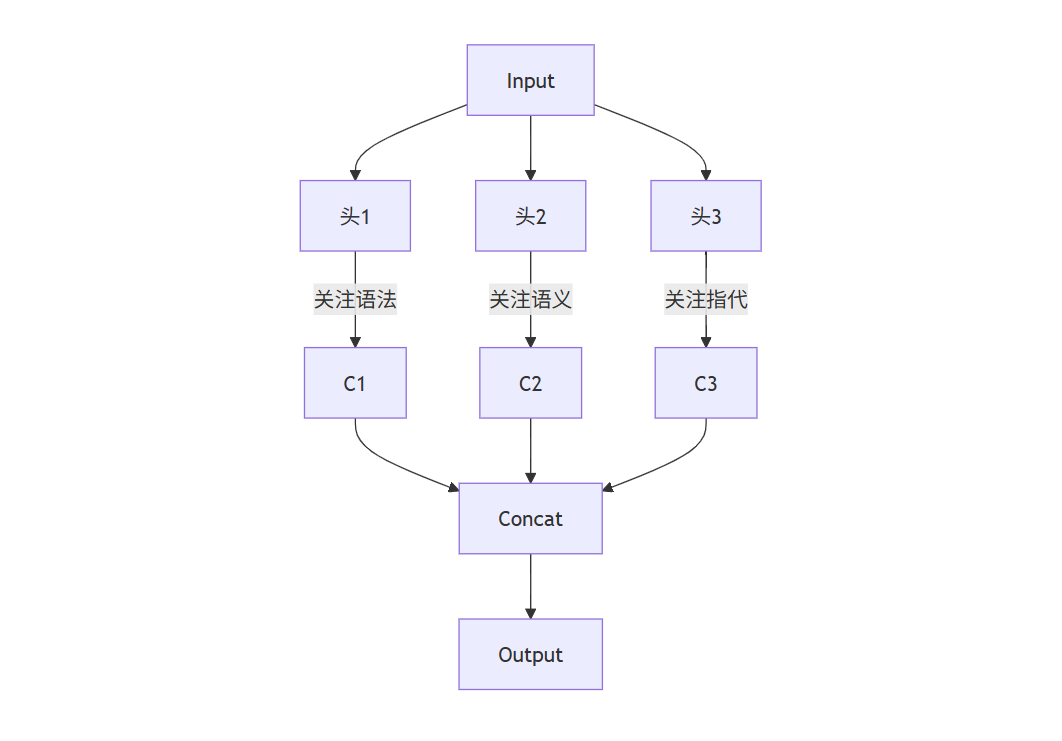
根据相关报告可知,8头注意力在大多数NLP任务中表现最优,能够同时捕捉:
- 语法关系
- 语义关联
- 指代关系
- 主题一致性
四、自注意力与卷积、循环网络的对比优势
| 特性 | 自注意力 | CNN | RNN |
|---|---|---|---|
| 长距离依赖 | 优秀 | 有限 | 中等 |
| 计算复杂度 | O(n²) | O(k×n) | O(n) |
| 并行度 | 完全并行 | 高度并行 | 序列依赖 |
| 位置敏感性 | 需额外编码 | 局部敏感 | 顺序敏感 |
值得注意的是,2025年最新提出的稀疏注意力变体已将计算复杂度降低到O(n log n),使得处理超长序列(如整本小说)成为可能。
五、 自注意力机制在视觉领域的创新应用
原本为NLP设计的自注意力机制,现已在计算机视觉领域大放异彩。Vision Transformer(ViT)通过以下方式适配图像数据:
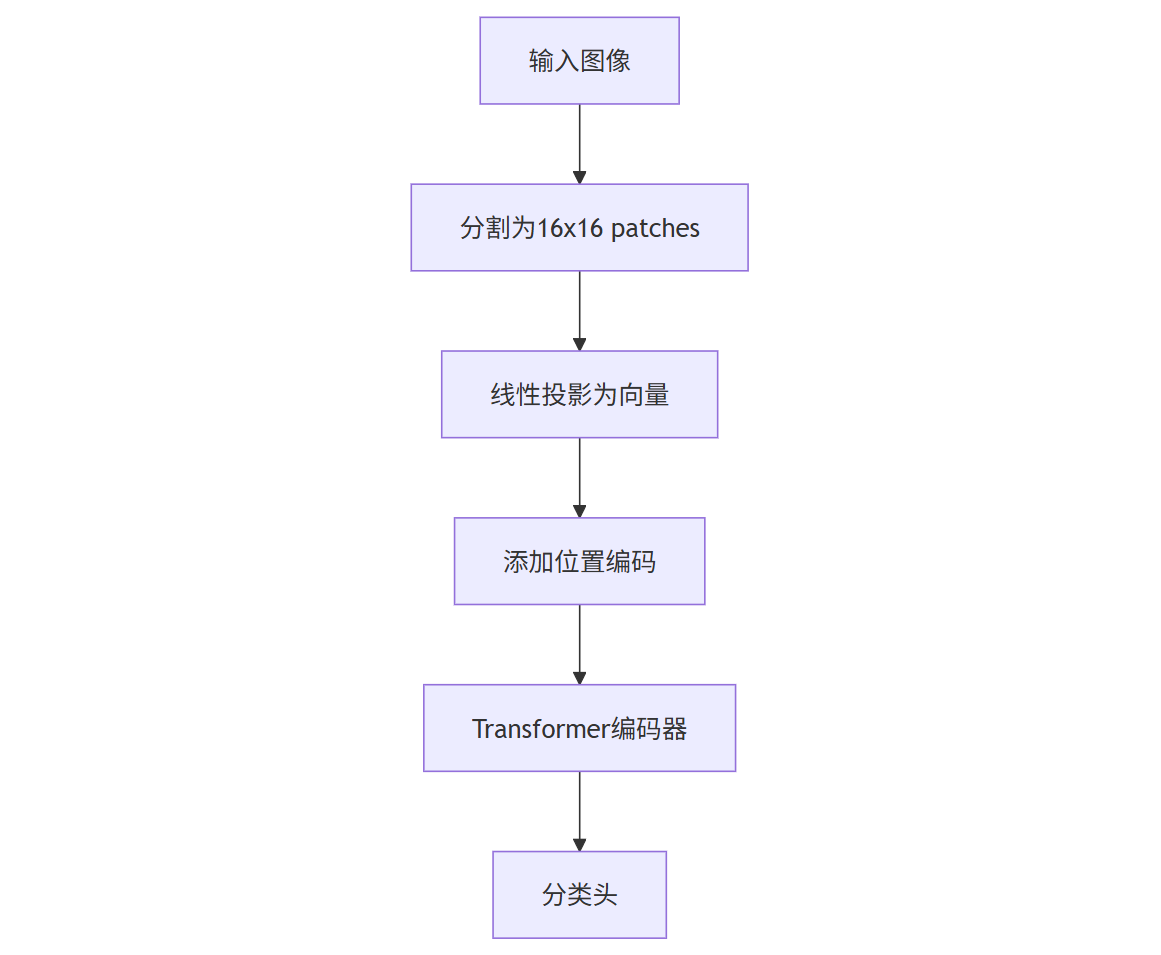
具体流程:
- 将224x224图像分割为196个16x16的patch
- 每个patch展平为768维向量
- 添加可学习的位置编码
- 通过多层Transformer处理
- 使用第一个token([CLS])进行分类

六、自注意力机制的实践优化技巧
工业级实现中需要考虑的关键优化点:
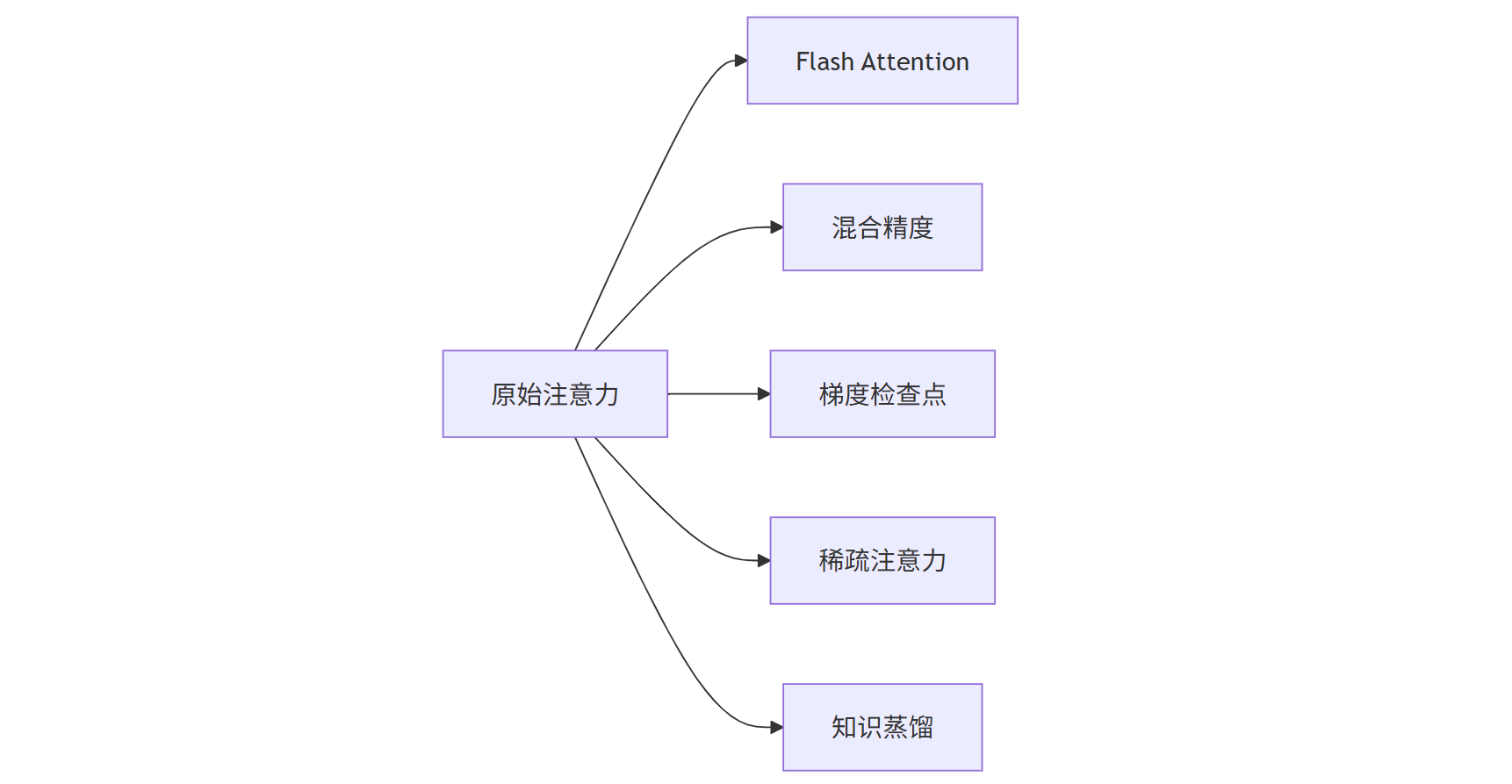
1、Flash Attention:通过智能内存管理将注意力计算速度提升4-6倍
2、混合精度训练:FP16+FP32混合使用减少显存占用
3、梯度检查点:以时间换空间,支持更大batch size
4、稀疏注意力:基于内容或位置的稀疏化降低计算量
5、知识蒸馏:将大模型的自注意力模式迁移到小模型
七、自注意力机制的未来发展方向
虽然自注意力已经展现出强大能力,但仍存在改进空间。DeepMind在2025ICML会议上提出了几个前沿方向:
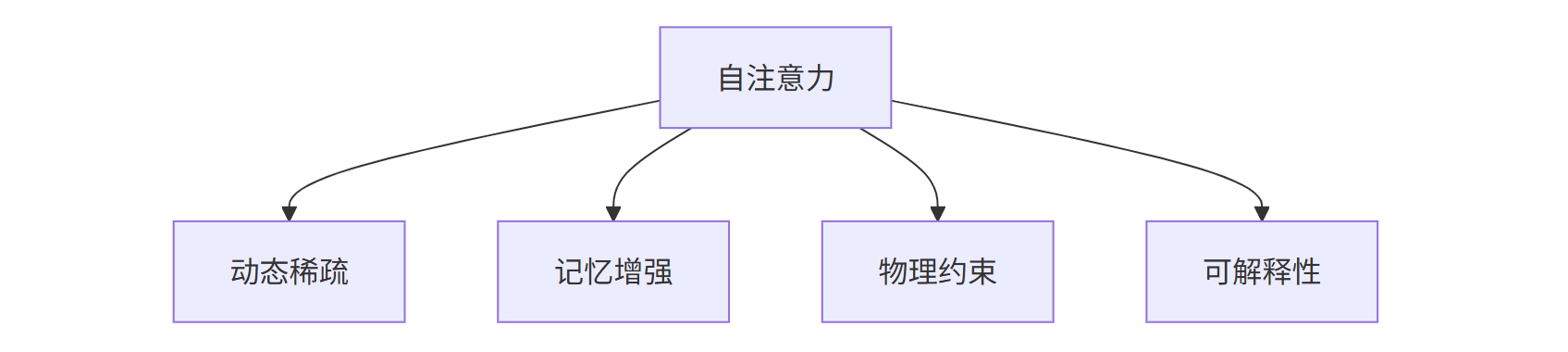
- 动态稀疏注意力:根据输入内容动态调整注意力范围
- 记忆增强注意力:引入外部记忆模块存储长期知识
- 物理约束注意力:在科学计算中融入物理定律约束
- 可解释注意力:开发可视化工具解析注意力模式
特别值得一提的是,Anthropic最新研究显示,通过精细调控注意力头的专业化,可以显著提升模型的安全性和可控性。
理解自注意力机制的本质价值
自注意力机制就像给AI装上了"动态聚光灯",让它能够自主决定在何时关注何种信息。这种灵活的信息处理方式不仅颠覆了传统序列建模方法,更开创了"全注意力"的AI架构新时代。从ChatGPT的对话流畅性到Midjourney的图像生成质量,背后都是自注意力机制在默默发挥着核心作用。掌握这一机制,就等于拿到了理解现代AI模型的万能钥匙。随着2025年更多基于Transformer-XL架构的模型问世,自注意力机制必将继续引领AI技术的新一轮进化浪潮。


最新发布

热门推荐



