大模型Agent设计技术路线图:构建智能体系统的核心方法
最近和一位做企业数字化的朋友聊天,他吐槽道:“我们花大价钱部署了大模型,但做的智能体要么只会机械回答问题,要么在复杂任务中卡壳——这和想象中‘能自主决策的智能助手’差太远了!”这句话戳中了当下大模型Agent落地的痛点:大模型≠智能体系统,从模型到Agent的设计技术路线图,才是决定智能体能力上限的关键。
作为参与过多个企业级大模型Agent开发的技术顾问,我深刻体会到:大模型Agent的设计不是“给大模型加个对话框”,而是需要从需求分析、架构设计到组件开发的全链路技术规划。今天这篇文章,我就结合2025年最新的行业实践与权威报告,拆解大模型Agent设计的技术路线图,帮你理清从0到1构建智能体系统的核心方法。
一、大模型Agent的定义与核心价值:为什么需要“重新设计”?
要设计大模型Agent,首先要明确它与传统智能系统的区别。大模型Agent(Large Model Agent)是基于大语言模型(LLM)或其他大模型(如多模态模型)构建的自主智能体系统,具备“感知-规划-执行-反馈”的闭环能力,能像人类一样处理复杂任务。它的核心价值在于:将大模型的“生成能力”升级为“解决问题能力”。
1.1 从“工具”到“伙伴”:大模型Agent的三大跃升
传统智能系统(如基于规则的系统、简单对话机器人)依赖预设规则或单轮交互,而大模型Agent实现了三大突破:
- 自主决策:通过“规划器”模块分解任务,动态调整策略(例如:用户让“订今晚7点上海外滩的餐厅”,Agent会自动查询空位、对比评分、生成预订话术);
- 持续学习:通过“记忆库”存储历史交互数据,逐步优化决策逻辑(例如:多次订餐失败后,Agent会自动排除评分低于4.5的餐厅);
- 多工具协同:调用外部API、数据库或专用模型(如天气查询、支付接口),完成单模型无法处理的任务(例如:旅行规划Agent整合机票、酒店、景点API,生成定制化行程)。
根据相关行业报告,具备自主决策能力的智能体系统在企业服务市场的渗透率已达28%,预计2026年将突破40%——这组数据背后,是大模型Agent从“概念验证”到“规模化落地”的关键转折。
1.2 需求场景分化:哪些领域最需要大模型Agent?
大模型Agent的价值在不同场景中差异显著。结合Gartner 2025年的《智能体技术成熟度曲线》,当前最适合落地的场景包括:
| 场景类型 | 典型需求 | 大模型Agent的优势 |
|---|---|---|
| 客户服务 | 多轮对话、复杂问题解决 | 自主分析对话历史,调用知识库/工具 |
| 代码开发 | 需求拆解、代码生成与调试 | 结合代码理解与大模型生成能力 |
| 运营管理 | 流程自动化、异常检测与决策 | 动态规划任务路径,联动多系统数据 |
举个真实案例:某电商企业用大模型Agent重构客服系统后,复杂问题(如“未收到货但显示已签收”)的解决时长从平均15分钟缩短至3分钟,人工干预率下降60%
二、技术路线图的整体框架:从需求到落地的全链路规划
大模型Agent的设计不是“拍脑袋”工程,而是需要分阶段、可验证的技术路线图。结合阿里云2025年发布的《大模型Agent开发指南》,完整的技术路线图可分为四个阶段:需求分析→架构设计→组件开发→测试优化。每个阶段都需要明确目标、关键任务与交付物。
2.1 阶段一:需求分析——明确“智能体要解决什么问题”
需求分析是技术路线图的起点,核心是回答三个问题:
- 任务类型:是单轮交互(如问答)还是多轮复杂任务(如项目管理)?
- 自主程度:需要完全自主决策(如智能客服),还是辅助人类决策(如投资顾问)?
- 资源约束:可用的算力(GPU/CPU)、数据(标注数据量)、外部工具(API/数据库)有哪些限制?
关键动作:
- 与业务方深度访谈,梳理典型任务场景(例如:客户投诉处理需包含“情绪识别→问题分类→方案推荐→跟进反馈”);
- 定义“成功指标”(如响应时间<5秒、任务完成率>90%);
- 输出《需求规格说明书》,明确智能体的核心功能与非功能需求。
2.2 阶段二:架构设计——搭建“智能体的大脑与神经”
架构设计决定了智能体的扩展性与稳定性。大模型Agent的典型架构可分为“感知层-决策层-执行层-反馈层”四大模块(如图1所示)。、
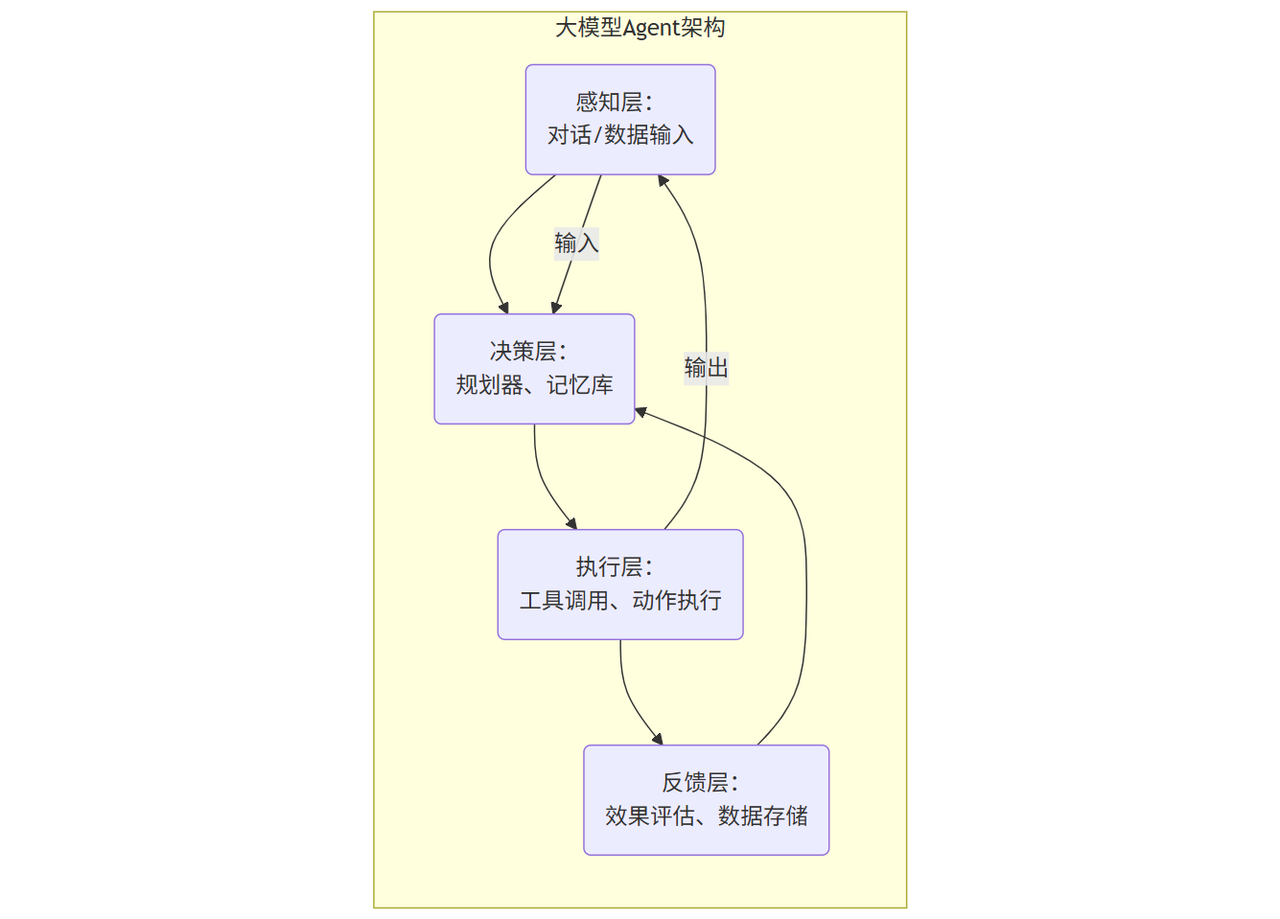
图1:大模型Agent典型架构示意图
核心模块解析:
- 感知层:负责接收外部输入(文本、语音、图像等),通过预处理(如ASR语音转文字、OCR图像识别)转化为模型可理解的格式;
- 决策层:智能体的“大脑”,包含规划器(分解任务、生成行动序列)和记忆库(存储历史交互数据、知识图谱);
- 执行层:智能体的“双手”,调用外部工具(如API、数据库)或内部模型(如代码生成模型)完成任务;
- 反馈层:智能体的“神经系统”,评估任务执行效果(如用户满意度、任务完成率),并将经验数据回流至记忆库,优化决策逻辑。
2.3 阶段三:组件开发——从模块到系统的落地实现
架构设计完成后,需逐个开发核心组件。根据Forrester 2025年Q2的《大模型Agent组件研究报告》,规划器、记忆库、工具链是大模型Agent的三大核心组件,其设计直接影响智能体的能力上限。
2.3.1 规划器:任务分解的“智能大脑”
规划器的核心功能是将用户需求拆解为可执行的子任务,并生成行动序列。例如,用户需求“帮我准备下周会议的资料”会被拆解为:
- 查询会议主题与参会人;
- 收集行业最新报告;
- 整理关键数据与结论;
- 生成PPT大纲。
技术实现要点:
- 采用“基于规则+大模型生成”的混合策略:简单任务用规则引擎(如正则匹配),复杂任务用大模型生成(如输入“用户需求+历史数据”,输出行动序列);
- 引入“代价评估”机制:对每个子任务预估时间、算力成本,选择最优执行路径(例如:优先调用本地数据库,再调用外部API)。
2.3.2 记忆库:智能体的“长期记忆”
记忆库负责存储智能体的“经验”,包括对话历史、用户偏好、任务执行结果等。根据使用场景,记忆库可分为:
- 短期记忆:存储当前对话的上下文(如最近3轮对话内容),用于理解用户意图;
- 长期记忆:存储结构化数据(如用户画像、知识图谱),通过向量数据库(如Milvus)实现高效检索。
关键挑战:如何平衡记忆的“容量”与“效率”?实践表明,使用“分层存储+动态更新”策略效果最佳:高频数据存短期记忆(内存),低频数据存长期记忆(向量数据库),并通过“遗忘机制”删除过时信息(例如:6个月未交互的用户对话)。
2.3.3 工具链:智能体的“扩展能力”
工具链是大模型Agent与外部世界交互的桥梁,常见工具包括:
- API调用(如天气查询、支付接口);
- 数据库操作(如MySQL、MongoDB查询);
- 专用模型调用(如图像识别模型、语音合成模型)。
开发建议:
- 优先封装高频工具(如企业内部的CRM系统API),形成“工具库”;
- 设计统一的工具调用接口(如通过JSON格式传递参数),降低模块耦合;
- 加入“工具校验”机制:调用前检查参数合法性(如日期格式是否正确),避免无效调用。
2.4 阶段四:测试优化——从“可用”到“可靠”的终极验证
测试优化是技术路线图的最后一环,核心目标是通过系统性测试暴露问题、验证效果,并基于数据持续优化,最终实现“可用→好用→可靠”的能力跃升。结合行业实践,可分为三个核心环节:
2.4.1 功能验证:确保“基础能力”达标
功能验证需覆盖智能体的核心功能与非功能需求(如安全性、易用性)。关键动作包括:
- 单元测试:针对规划器、记忆库等单个组件单独测试(如验证规划器能否正确拆解“订酒店”任务);
- 集成测试:模拟多模块协作场景(如用户发起“会议安排”请求,验证各层是否流畅联动);
- 边界测试:验证极端输入下的表现(如超长对话、模糊指令),避免崩溃或错误输出。
关键指标:功能覆盖率(≥95%)、需求实现准确率(≥90%)。
2.4.2 性能压测:验证“大规模场景”下的稳定性
需评估高并发、多任务压力下的表现,测试重点包括:
- 响应时间:模拟1000+并发请求,验证平均响应时间是否≤5秒(按需求定义);
- 吞吐量:测试单位时间可处理的任务数量(如每秒200个请求);
- 容错能力:模拟工具调用失败等场景,验证自动重试或降级处理能力。
实践建议:使用Locust等工具结合真实业务日志生成测试用例,确保场景贴合实际。
2.4.3 持续迭代:基于反馈的“数据驱动优化”
测试暴露的问题需转化为迭代需求,通过模型优化(如微调大模型提升规划准确性)、规则调整(如修正工具调用参数)或体验升级(如优化生成话术),推动智能体能力持续提升。
通过测试优化,智能体将从“实验室可用”升级为“生产环境可靠”,避免上线后因功能缺陷导致的业务损失(据统计,未经充分测试的系统修复成本占总开发成本约40%)。因此,这一阶段是“必选项”而非“可选步骤”。
三、典型技术架构解析:从通用到专用的设计差异
不同场景对大模型Agent的要求不同,技术架构也需灵活调整。以下是三类典型场景的架构设计差异:
3.1 通用型智能体(如智能客服)
核心需求:支持多轮对话、多任务处理、跨领域知识。
架构特点:
- 采用“大模型+通用工具链”设计(如集成天气、日历、知识库API);
- 记忆库以短期对话上下文为主,长期记忆存储用户基本信息(如姓名、历史问题);
- 规划器侧重“意图识别”与“任务优先级排序”(例如:用户同时问“订单状态”和“退货政策”,优先处理订单状态)。
3.2 专业型智能体(如代码开发助手)
核心需求:理解代码语法、生成符合规范的代码、调试错误。
架构特点:
- 大模型选择代码专用模型(如CodeLlama、StarCoder),而非通用大模型;
- 工具链集成代码编译器(如GCC)、代码检查工具(如SonarQube)、版本控制系统(如Git);
- 记忆库存储代码片段、项目文档、历史bug解决方案(通过代码向量化实现快速检索)。
3.3 协作型智能体(如团队项目管理助手)
核心需求:理解团队角色、协调任务进度、同步信息。
架构特点:
- 大模型需具备“多角色理解”能力(如识别“产品经理”“开发工程师”的不同需求);
- 工具链集成项目管理工具(如Jira、Trello)、即时通讯API(如企业微信、Slack);
- 记忆库存储团队成员的技能标签(如“擅长前端开发”“熟悉数据库”)、历史任务完成情况。
四、开发流程与实践要点:从原型到量产的关键步骤
设计完技术路线图后,就进入开发实施阶段。根据甲子光年2025年5月的《大模型Agent开发实战手册》,完整的开发流程可分为原型验证→迭代优化→量产部署三个阶段,每个阶段都有需要注意的实践要点。
4.1 原型验证:用最小可行产品(MVP)快速试错
原型验证的目标是“用最简方案验证核心能力”,避免过度设计。 关键步骤:
- 选择1-2个典型场景(如“会议纪要生成”),定义核心功能(如自动提取重点、生成待办事项);
- 使用轻量级工具(如LangChain快速搭建Agent框架),减少开发周期;
- 邀请5-10名目标用户内测,收集反馈(如“待办事项不够准确”“响应速度慢”)。
注意事项:原型阶段不必追求“完美”,重点是验证“大模型是否能理解需求”“工具链是否稳定”“规划器是否能生成合理行动序列”。
4.2 迭代优化:基于数据的持续改进
原型验证通过后,需进入“数据-优化-验证”的循环。 核心动作:
- 日志记录:记录每一次任务执行的详细数据(如用户输入、规划器生成的行动序列、工具调用结果、用户反馈);
- 问题分析:通过日志定位瓶颈(如“规划器在复杂任务中生成错误行动序列的概率达30%”);
- 模型微调:用标注数据微调大模型(如增加“任务分解”的示例),或优化规划器的规则引擎;
- A/B测试:对比优化前后的效果(如任务完成率从70%提升至85%),确认改进有效后再全量发布。
4.3 量产部署:平衡性能与成本
量产部署的关键是“在效果与成本间找到平衡点”。 实践建议:
- 算力优化:对大模型进行量化(如FP16转INT8)或剪枝,降低推理成本(千亿参数模型推理成本可降低40%);
- 弹性扩容:根据流量峰值动态调整实例数量(如高峰时段增加GPU服务器);
- 监控告警:部署实时监控系统(如Prometheus+Grafana),监控响应时间、错误率、算力使用率等指标,异常时自动告警。
4.4 Agent搭建平台推荐
BetterYeah AI Agent——国内专注于企业级智能体设计的专业平台,为企业AI大模型应用落地提供实用支持。平台主打“零代码搭建”理念,通过图形化界面降低使用门槛,无需编程即可快速搭建并部署功能适配的智能体Agent,助力释放大模型潜力,应对多样化业务需求。
平台提供一站式模型集成功能,内置ChatGLM、阿里通义千问、百度千帆等国内外主流AI模型,支持用户根据场景灵活选择,适配不同业务需求。知识管理方面,配备自动向量化、分段及混合检索工具,保障Agent基于本地知识库输出精准内容,并深度集成企业业务数据,形成持久记忆与个性化服务能力。
针对业务流程设计,平台支持自定义AI工作流,提供官方插件扩展功能,简化多场景应用开发流程,提升部署效率。此外,平台支持API、SDK、Webhook等方式与现有系统(如微信客服、钉钉、飞书)无缝对接,并具备多模态智能问答能力,可处理文字、图片、语音、视频等多类型内容,满足多样化交互需求。
可通过BetterYeah AI Agent平台设计自己的专属Agent,助力智能化转型实践。
五、挑战与解决方案:大模型Agent设计的三大难点
尽管技术路线图逐渐清晰,大模型Agent的设计仍面临诸多挑战。结合2025年行业实践,以下三大难点最需关注:
5.1 难点一:大模型的“幻觉”问题如何解决?
大模型在生成内容时可能产生“幻觉”(即错误信息),这对智能体的可信度是致命打击。解决方案:
- 引入“事实校验”模块:调用权威数据库(如维基百科、企业内部知识库)验证生成内容;
- 使用“少样本学习”:在提示词中加入示例(如“正确格式:会议时间-地点-参会人”),引导模型生成准确信息;
- 混合专家模型:对关键任务(如医疗咨询),用专用小模型(如BioBERT)辅助大模型决策。
5.2 难点二:多工具调用的“协同效率”如何提升?
智能体常需调用多个工具(如查天气、订机票、发邮件),工具间的协同效率直接影响任务完成速度。解决方案:
- 工具编排引擎:通过可视化界面定义工具调用顺序(如“先查天气,再根据天气推荐穿搭”),避免硬编码;
- 缓存机制:对高频调用的工具结果(如实时天气)缓存5分钟,减少重复调用;
- 错误重试:对失败的工具调用(如API超时)设置重试次数(建议3次),并记录错误日志。
5.3 难点三:个性化与泛化性的“平衡术”
智能体需要在“适应特定用户习惯”(如“用户A喜欢简洁回复”)和“泛化到新用户”(如“用户B需要详细回复”)间找到平衡。解决方案:
- 用户画像标签:通过用户行为数据(如历史对话长度、偏好功能)生成标签(如“简洁型”“详细型”);
- 动态风格切换:根据用户标签调整回复风格(如对“简洁型”用户,生成“会议时间:周五14:00”;对“详细型”用户,补充“地点:3楼会议室,需携带笔记本”);
- 小样本微调:收集新用户的少量交互数据(如10-20条对话),快速微调大模型,提升个性化适应能力。
总结:大模型Agent设计是“系统工程”而非“模型游戏”
如果把大模型Agent比作“智能机器人”,大模型是它的“大脑”,技术路线图则是“建造图纸”——没有清晰的图纸,再强大的大脑也无法变成能完成复杂任务的机器人。
从需求分析到量产部署,大模型Agent的设计需要技术团队、业务方、用户的深度协同,既要懂大模型的“能力边界”,也要懂业务的“真实需求”。正如一位资深AI工程师所说:“好的大模型Agent不是‘大模型的炫技’,而是‘用技术解决具体问题的艺术’。”
下次再看到“大模型Agent”的宣传,不妨多问一句:“它的技术路线图清晰吗?能解决哪些具体问题?”——这,才是判断一个智能体系统是否真正有价值的关键。

最新发布

热门推荐



