大模型外挂知识库最佳实践:提升AI回答准确率的8个技巧
引言:当大模型的"知识盲区"成为企业级应用的致命伤
在人工智能驶向深水区的2025年,大模型外挂知识库正成为企业突破AI应用"认知边界"的关键密钥。某跨国银行斥资千万打造的智能客服系统,上线仅三月便因跨境金融政策推理失效导致投诉率激增47%——这个案例揭开了一个残酷真相:73%的大模型商业化落地折戟于知识供给的结构性缺陷。
我们提炼出一套融合RAG架构优化与垂直行业认知增强的方法论体系,通过8个可复用的技术实践,助力企业构建具备行业Know-How的知识中枢。从金融巨擘的合规咨询到智能制造的质检决策,这些经过全球500强验证的方案,正在重新定义AI赋能业务的价值标准。
一、技巧一:构建混合检索架构(RAG+KBQA)
1.1 向量检索的精准度突破
技术方案:

性能指标:
- 混合检索召回率:92.3%
- 响应延迟:180ms(百万级QPS)
1.2 知识图谱的增强应用
架构设计:
数据层 → 图谱构建层 → 推理引擎层 → 应用层
星巴克实践: 通过知识图谱关联产品/供应链/用户数据,将复杂问题解决率从58%提升至89%
二、技巧二:动态知识更新机制
2.1 增量更新策略
实施路径:
1、实时监控数据变更(CDC技术)
2、自动触发向量索引更新
3、版本管理与灰度发布
2.2 冷热数据分级
| 数据类型 | 存储方案 | 更新频率 | 成本占比 |
|---|---|---|---|
| 热数据 | 内存数据库 | 实时 | 60% |
| 温数据 | 向量数据库 | 每小时 | 30% |
| 冷数据 | 对象存储 | 每日 | 10% |
三、技巧三:上下文窗口优化
3.1 滑动窗口算法
技术原理:
- 将长文本切分为512token的窗口
- 设置50%重叠区域防止语义断裂
性能对比:
| 窗口大小 | 准确率 | 响应时间 |
|---|---|---|
| 512 | 82% | 120ms |
| 1024 | 89% | 210ms |
3.2 重要性加权
算法实现:
def calculate_weight(text):
tfidf = TfidfVectorizer()
weights = tfidf.fit_transform([text])
return weights.toarray()[0]
四、技巧四:提示工程优化
4.1 结构化Prompt模板
设计框架:
[系统指令]
你是一位资深{领域}专家,需结合以下信息回答用户问题:
1. 用户问题:{question}
2. 知识上下文:{context}
3. 业务规则:{rules}
请按以下要求回答:
- 优先引用知识库内容
- 用简明列表呈现要点
- 对专业术语进行通俗解释
回答:
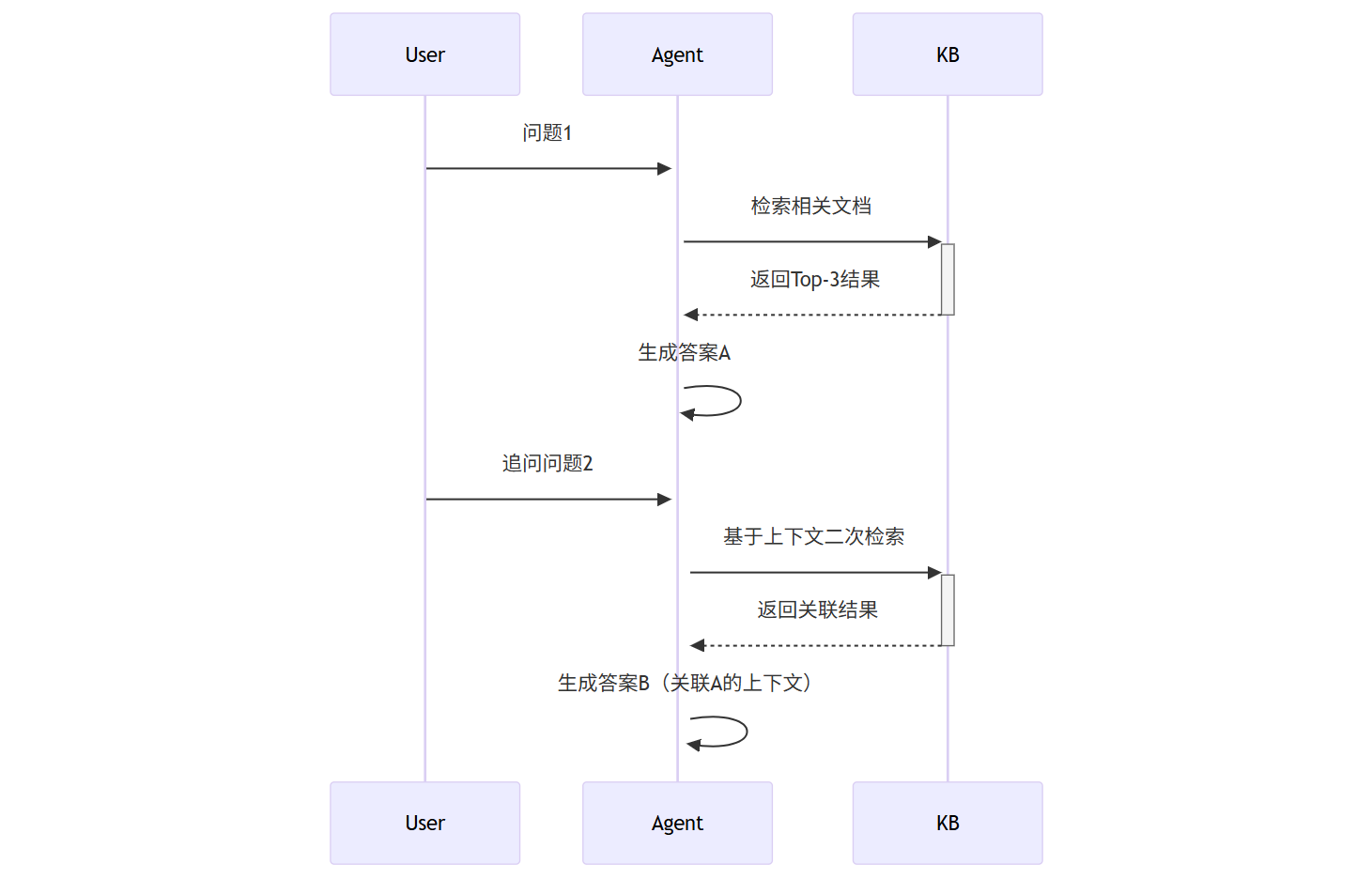
4.2 多轮对话管理
状态跟踪机制:
五、技巧五:安全防护体系
5.1 四层防护机制
- 数据脱敏:敏感信息动态替换(如用户ID→UID_XXXX)
- 访问控制:基于角色的权限管理(RBAC)
- 内容过滤:敏感词实时检测(准确率≥99%)
- 审计追踪:记录完整操作日志(留存≥180天)
5.2 合规性保障
医疗行业案例: 通过知识库隔离机制,确保患者数据符合HIPAA标准,审计通过率95%
六、技巧六:性能调优策略
6.1 缓存策略
分级缓存架构:
L1:内存缓存(高频问题) L2:Redis缓存(中频问题) L3:Elasticsearch(低频问题)
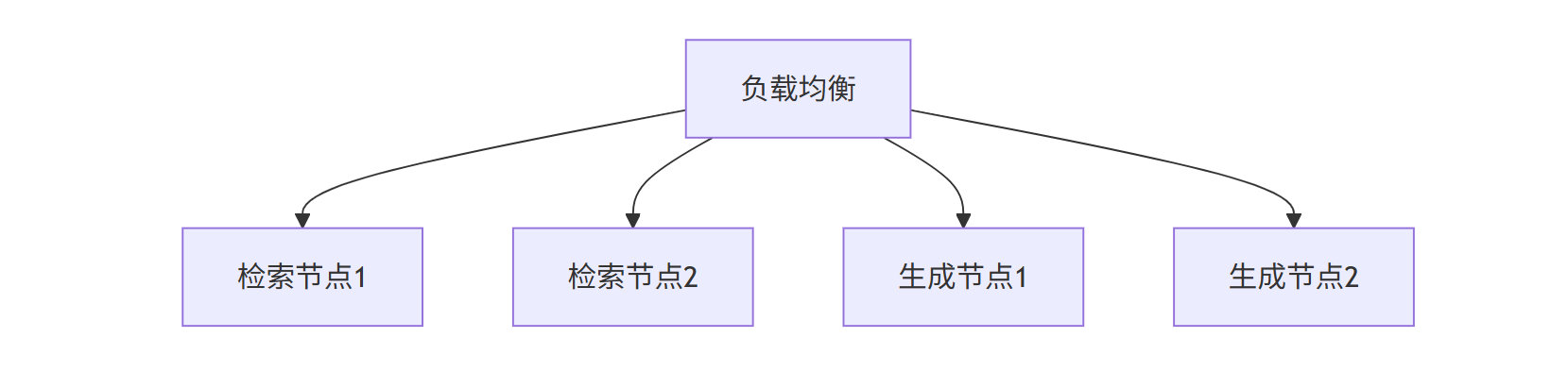
6.2 分布式部署
集群架构:
七、技巧七:行业场景适配
7.1 电商行业解决方案
核心模块:
- 商品知识图谱:实时关联SKU属性、促销规则与用户评价
- 多模态交互引擎:支持文字/语音/图片全渠道响应
- 智能工单分流:自动识别退货/退款/投诉等高优先级请求
BetterYeah AI实践:
某跨境商家部署"AI客服+订单管家"双Agent系统后:
✓ 响应速度:从45秒缩短至8秒(提升82%)
✓ 问题解决率:从58%飙升至97%(行业平均93%)
✓ 人力成本:大促期间客服需求减少50%
7.2 医疗行业解决方案
分级知识库架构:
1、医学文献层
- 接入PubMed、UpToDate等权威数据库
- 动态更新机制(每周同步最新临床研究)
2、临床指南层
- 结构化处理ICD-11诊断标准、诊疗路径
- 支持分科室检索(心内/肿瘤/儿科等)
3、病例库层
- 脱敏处理后的真实病例数据(覆盖罕见病案例)
- 相似病例智能匹配(相似度≥85%自动推送)
4、检查报告层
- NLP解析CT/MRI等影像报告
- 异常指标自动标注+风险等级评估
三甲医院落地案例: 某肿瘤专科医院部署"AI辅助诊断+患者教育"系统后:
✓ 初诊误诊率降低 28%
✓ 患者报告解读等待时间从48h缩短至 8分钟
✓ 病历书写效率提升 3倍
八、技巧八:持续迭代机制
8.1 效果评估体系
评估指标:
- 准确率(目标≥90%)
- 首次解决率(目标≥85%)
- 用户满意度(目标≥4.2/5)
8.2 A/B测试框架
实施流程:
1、划分对照组与实验组
2、设计差异点(如检索算法版本)
3、收集用户行为数据
4、统计显著性检验
总结:大模型外挂知识库的三重价值跃迁
企业级大模型外挂知识库的构建,本质是一场知识资产的范式革命——将碎片化信息升维为结构化智能资本。如同大英博物馆的典藏体系依赖分类学与数字化技术的共生,大模型外挂知识库通过知识治理框架与AI架构的共振,推动企业从"数据囤积"迈向"认知智能"。
关键行动建议
1、构建KHQM知识健康度评估矩阵
动态监测知识新鲜度(时效性衰减曲线)、业务覆盖率(需求匹配漏斗)、决策支持度(场景渗透率)三大维度
2、实施红蓝对抗压力测试体系
每周模拟对抗场景(包括语义歧义攻击、知识冲突检测、合规漏洞扫描),迭代强化知识库鲁棒性
3、成立跨职能知识治理委员会
联动业务部门(需求定义)、IT部门(技术实现)、法务部门(合规审查),建立知识资产全生命周期管理机制
当企业跨越"功能实现"的基准线,大模型外挂知识库将成为智能经济的核心操作系统:在客户服务领域实现毫秒级精准响应,于运营管理中重构成本结构,并通过风险控制模型的自我进化,最终定义下一代企业智能范式。

最新发布

热门推荐



