大模型知识库RAG怎么搭建?90%的教程没告诉你的企业级落地关键
麦肯锡在其权威解读中将RAG(检索增强生成)定义为"将大语言模型与外部知识库连接的核心架构",并指出它是企业AI从实验室走向生产的关键技术路径。麦肯锡:什么是RAG?然而现实是,大量企业团队花了数周时间搭出了一个"能跑通的Demo",却在推向生产时遭遇了检索不准、权限混乱、维护困难等一系列问题——最终让项目烂尾。本文不重复那些"附完整代码"的入门教程,而是系统梳理大模型知识库RAG怎么搭建的全链路决策,重点解决从Demo到生产上线这段最难走的"最后一公里"。
一、搭建RAG知识库前,先搞清楚这3个核心决策
很多团队在没想清楚技术路线的情况下就开始动手,导致后期大量返工。在写一行代码之前,以下三个决策必须先拍板。
1.1 你的场景适合RAG,还是微调(Fine-tuning)?
这是最容易被忽视的前置问题。RAG和微调并不是非此即彼的关系,但在资源有限的情况下,必须优先选择更适合自己场景的路线。
表:RAG与微调的核心决策对比
| 决策维度 | RAG(检索增强生成) | 微调(Fine-tuning) |
|---|---|---|
| 适用场景 | 知识频繁更新、需要引用来源、私有文档问答 | 特定风格/格式输出、垂直领域专业术语理解 |
| 知识更新成本 | 低(直接更新文档库即可) | 高(需重新训练,成本数万至数十万元) |
| 数据量要求 | 低(有文档即可) | 高(通常需要数千至数万条标注数据) |
| 幻觉控制 | 强(答案可溯源到原始文档) | 弱(模型仍可能产生幻觉) |
| 部署复杂度 | 中(需要向量库+检索层) | 高(需要GPU资源+训练基础设施) |
| 推荐优先级 | 企业知识库、客服问答、内部文档检索 | 代码生成、特定格式输出、专业领域NLU |
结论:如果你的需求是"让大模型能回答企业内部文档里的问题",RAG是正确选择。只有当你需要改变模型的"行为模式"(而非知识范围)时,才考虑微调。
1.2 向量数据库怎么选?
向量数据库是RAG系统的"记忆中枢",选型直接影响检索性能和运维成本。主流方案各有侧重:
- FAISS(Meta开源):纯内存检索,速度极快,适合数据量在百万级以下的单机部署场景。不支持持久化,重启后需重建索引,不适合生产环境长期运行。
- ChromaDB:轻量级,开箱即用,适合快速验证和小规模项目。生产环境稳定性和扩展性有限。
- Milvus:支持十亿级向量,分布式架构,适合企业级大规模生产部署。有Zilliz Cloud托管版,降低运维负担。
- Weaviate:内置混合检索(向量+BM25),模块化设计,适合需要多模态检索的企业场景。
- Qdrant:Rust编写,性能出色,支持payload过滤,适合需要精细权限控制的场景。
选型建议:个人验证用ChromaDB,生产环境千万级以下用Qdrant,企业级大规模部署用Milvus。
1.3 RAG框架选LangChain还是LlamaIndex?
图:RAG框架选型决策路径
LangChain的优势在于生态丰富,适合构建多工具调用的复杂Agent;LlamaIndex的优势在于专注文档索引和检索,对知识库问答场景优化更深,数据连接器更完善。两者并不互斥——许多生产项目用LlamaIndex做索引层,用LangChain做Agent编排层。
图:企业大模型知识库RAG系统工作原理示意
二、大模型知识库RAG搭建全流程(5步实战)
理解了技术选型的逻辑,接下来进入核心搭建流程。这5个步骤是RAG系统的完整骨架,每一步都有容易踩坑的细节。
2.1 第一步:数据预处理与文档解析
RAG系统的质量上限由数据质量决定。"垃圾进,垃圾出"在这里体现得尤为明显。
文档解析需要针对不同格式做专门处理:PDF文件需区分"文字型PDF"和"扫描型PDF",后者需要OCR(推荐PaddleOCR);Word文档注意保留标题层级结构;Excel表格需要转换为自然语言描述而非直接切块;HTML网页需要剥离导航栏、广告等噪声内容。
数据清洗阶段需要去除页眉页脚、水印文字、重复段落,并统一编码格式。这一步通常占整个RAG项目工时的30%-40%,却是最容易被低估的环节。
2.2 第二步:文本分块策略(Chunk策略)
分块策略是RAG效果的核心变量,直接决定检索精度。主流策略对比:
- 固定长度分块(Fixed-size Chunking):按字符数切割(如512字符),实现简单但容易切断语义。适合格式规整的技术文档。
- 语义分块(Semantic Chunking):基于句子嵌入的相似度动态分割,保持语义完整性,效果更好但计算成本更高。
- 递归字符分块(Recursive Character Splitting):LangChain默认方案,按段落→句子→字符的层级递归切割,平衡效果与效率,推荐作为默认起点。
- 文档结构感知分块(Structure-aware Chunking):利用Markdown标题、HTML标签等结构信息进行分割,适合有明确章节结构的文档。
实践建议:chunk_size从512开始调试,chunk_overlap设置为chunk_size的10%-20%(如512字符时设置50-100字符重叠),避免关键信息被截断在块边界。
2.3 第三步:向量化与向量库构建
文本分块完成后,需要将每个Chunk转换为向量(Embedding),并存入向量数据库。
Embedding模型选择直接影响检索质量。中文场景推荐优先使用专门针对中文优化的模型:BAAI/bge-large-zh-v1.5(开源,中文效果优秀)、text-embedding-3-large(OpenAI,效果最佳但有成本)、通义文本嵌入(阿里云,中文场景表现稳定)。
向量入库时需要同时存储元数据(metadata),包括文档来源、章节标题、创建时间、权限标签等,这些元数据在后续的过滤检索和权限控制中至关重要。
2.4 第四步:检索策略配置
这是决定RAG系统"天花板"的关键步骤。Google Cloud官方文档指出,RAG通过将LLM与外部知识库结合来改善输出质量,而检索策略的选择直接决定知识库信息能否被准确调取。
图:RAG检索策略选型决策树
三种主流检索策略的选择逻辑:
- 纯向量检索:适合以语义理解为主的场景(如"帮我找关于退款政策的内容"),对模糊查询友好,但对精确词匹配(如"SKU-20240315这个产品的参数")效果差。
- 混合检索(向量+BM25+RRF):综合向量检索的语义理解能力和BM25的关键词精确匹配能力,通过RRF(倒数排名融合)算法合并两路结果。企业知识库场景的推荐方案,覆盖了语义查询和精确查询两类需求。
- 重排序(Reranker):在初步检索结果基础上,用交叉编码器(Cross-Encoder)对候选文档重新打分排序,可将Top-K精度提升15%-30%。推荐模型:BAAI/bge-reranker-v2-m3(中文场景)。
2.5 第五步:生成层接入大模型
检索到相关文档片段后,将其与用户问题一起构造为Prompt,送入大模型生成最终答案。Prompt模板设计是这一步的核心:
你是企业内部知识库助手,请严格基于以下参考文档回答用户问题。 如果参考文档中没有相关信息,请明确告知用户"当前知识库中未找到相关内容",不要编造答案。 参考文档: {retrieved_context} 用户问题:{user_query} 请给出准确、简洁的回答:
"不要编造答案"这条指令是控制幻觉的关键——明确约束模型只基于检索内容作答,而非依赖训练知识。
三、从Demo到生产——企业级RAG落地的3大关键升级
大多数教程到第五步就结束了。但对于企业而言,"本地能跑通"和"生产环境稳定运行"之间,还隔着三道关卡。这也是当前竞品内容的核心盲区。
3.1 多文档格式与多模态知识接入
企业知识库的文档格式往往复杂多样:产品图册是PDF+图片、操作视频是MP4、数据报告是Excel、内部规范是Word。纯文本RAG系统无法处理这些非结构化多模态内容,导致大量有价值的企业知识无法被检索。
解决方案分为两层:一是文档层面,用专业的解析工具(如Unstructured、DocETL)处理多格式文档,提取图片中的文字(OCR)和表格中的结构化数据;二是知识库层面,引入多模态向量化能力,让图片、音视频内容也能被语义检索。
以某大型金融保险企业为例,其通过BetterYeah AI构建了覆盖超6万种保险产品的知识大脑,接入了产品说明书(PDF)、培训视频(MP4)、费率表(Excel)等多种格式文档,最终使10万+经纪人团队的学习效率提升3倍以上——这一成果的前提正是多模态知识接入能力的完整支撑。BetterYeah AI的VisionRAG引擎原生支持图片、音视频解析与语义索引,知识库最快3天即可完成构建上线,显著降低了企业级多模态RAG的落地门槛。
3.2 知识权限管理与多部门隔离
这是企业RAG项目中最容易被忽视、却最容易引发安全事故的环节。当一个知识库系统同时服务销售部(有权看客户合同)、财务部(有权看财务报告)、普通员工(只能看公开文档)时,如果没有细粒度的权限控制,将导致敏感信息泄露。
技术实现上,需要在向量库的每个文档Chunk的元数据中标注权限标签(如 department: finance, level: confidential),在检索时加入权限过滤条件,确保用户只能检索到有权访问的文档片段。Qdrant和Weaviate对payload过滤支持较好,可以作为权限控制场景的优先选择。
安全合规层面,企业知识库系统应通过等保三级认证,确保数据传输加密、存储加密、操作审计日志完整,以满足金融、医疗等强监管行业的合规要求。
3.3 效果评估与知识库持续迭代机制
RAG系统上线不是终点,而是一个持续迭代的起点。缺乏评估机制,就无法判断系统是在变好还是在变差。
建立RAG效果评估体系需要关注三个核心指标:
- 检索召回率(Retrieval Recall):相关文档是否被检索到。可通过构建测试问题集,人工标注"正确答案应来自哪个文档"来评估。
- 答案忠实度(Faithfulness):生成的答案是否真实来源于检索到的文档,而非模型自行编造。
- 答案相关性(Answer Relevancy):答案是否真正回答了用户的问题。
推荐使用RAGAS框架进行自动化评估,它可以同时计算以上三个维度的分数,并生成可追踪的评估报告。每次更新知识库(新增文档、修改分块策略、更换Embedding模型)后都应重新跑评估,确保系统质量不退化。
四、RAG检索效果优化:让准确率从60%提升到90%
很多团队搭完基础RAG后,发现检索准确率只有60%-70%,答案质量不稳定。以下是经过验证的优化路径。
图:RAG效果优化全景架构
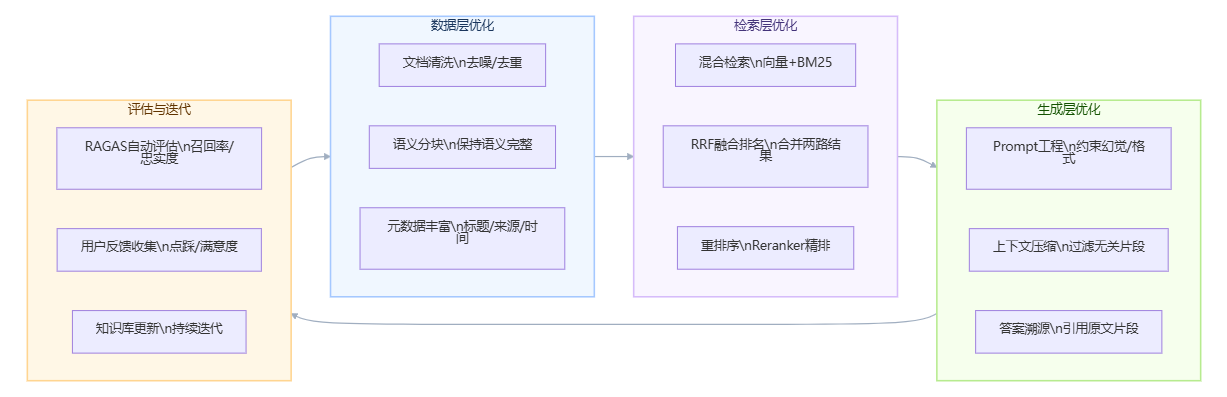
4.1 分块策略精调
如果初始准确率低于70%,首先检查分块策略。常见问题:chunk_size过大(512字符以上)导致检索到的片段包含大量无关内容;chunk_overlap为0导致关键信息被截断在块边界;未使用结构感知分块导致标题和正文分离。
精调方向:对于FAQ类文档,以"问-答对"为单位分块;对于产品手册,以"功能章节"为单位分块;对于规章制度,以"条款"为单位分块。不同文档类型使用不同分块策略,而非一刀切。
4.2 混合检索+RRF融合实战
混合检索的核心是将向量检索和BM25检索的结果通过RRF(Reciprocal Rank Fusion)算法融合。RRF公式:score(d) = Σ 1/(k + rank_i(d)),其中k通常取60。
实践中,向量检索和BM25各取Top-20结果,经RRF融合后取Top-5送入生成层。对比测试表明,混合检索相比纯向量检索,在包含专有名词(产品型号、人名、地名)的查询上准确率提升约20%-35%。
4.3 重排序(Reranker)接入
Reranker是RAG优化的"最后一公里"。它使用交叉编码器(Cross-Encoder)对查询和每个候选文档片段进行联合编码,输出精确的相关性分数,比向量检索的余弦相似度更准确。
接入成本:BAAI/bge-reranker-v2-m3可本地部署(需约4GB显存),每次检索增加约100-300ms延迟。在对准确率要求高的企业场景(如法律合规问答、医疗知识库),这个延迟成本是值得的。
对于希望跳过底层技术复杂度、直接获得企业级混合检索能力的团队,BetterYeah AI提供了开箱即用的多策略智能检索方案(向量+全文+结构化+图谱混合检索)。
五、写在最后
大模型知识库RAG的搭建,从来不是一个纯技术问题。它的本质是:用正确的技术决策,将企业沉淀多年的知识资产转化为可被AI精准调用的生产力。从RAG/微调选型、向量库选型、框架选型,到5步搭建流程,再到企业级的多模态接入、权限管理、效果评估闭环——每一个环节都有可能成为项目成败的关键变量。建议从一个具体的业务场景出发,用最小可行系统(MVP)快速验证,再逐步扩展到生产级架构,而非一开始就追求"完美系统"。RAG不是终点,它是企业AI能力持续进化的起点。

最新发布

热门推荐



