多模态大模型知识库搭建:文本、图像、音视频融合处理指南
引言:当企业的“知识碎片”遇上大模型,如何拼出智能新图景?
作为一家AI解决方案服务商的技术负责人,我最近被客户问得最多的问题是:“我们企业有大量网页、产品图片、培训视频,甚至客户通话录音,这些散落在各个系统的‘知识碎片’,怎么用大模型串起来变成能直接用的‘智能资产’?”这恰恰戳中了当前企业知识管理的痛点——传统知识库只能处理结构化文本,而多模态数据(文本、图像、音视频)占比已超70%,但利用率不足15%。
今天我们就聚焦一个核心命题:如何搭建多模态大模型知识库,从需求诊断到落地避坑,从技术原理到实战案例,我会用一线经验拆解每个关键环节,帮你把“死数据”变成“活智能”。
一、为什么说多模态大模型知识库是企业AI转型的“必选项”?
1.1 从“单模态”到“多模态”:知识管理的范式转移
传统知识库依赖结构化文本(如PDF、Word),但企业真实场景中,技术网页里的流程图、客服对话的语音记录、产品故障的视频演示,这些非结构化数据往往藏着最关键的“隐性知识”。Gartner 2025年《多模态AI技术成熟度曲线》指出,能同时处理文本、图像、音视频的知识库,其知识召回率比单模态系统高42%,决策支持效率提升3倍。
举个真实案例:某制造业头部企业引入多模态知识库后,售后工程师通过上传设备故障视频,系统能自动匹配历史维修网页、零件示意图甚至专家语音备注,平均故障解决时间从4小时缩短至20分钟——这就是多模态融合带来的“知识协同效应”。
1.2 企业知识管理的三大“隐性成本”,多模态知识库能破解
- 存储成本:某互联网公司每年因格式不兼容导致的知识重复存储浪费超200万元,多模态知识库通过统一向量存储,存储效率提升60%;
- 检索成本:员工用“模糊关键词”搜索时,单模态系统常返回无关结果,多模态系统通过跨模态语义关联,准确率从58%提升至89%;
- 更新成本:传统知识库依赖人工标注,多模态大模型可通过“自监督学习”自动提取新数据特征,维护成本降低55%。
二、搭建前的关键准备:避开“伪需求”陷阱
2.1 先问自己三个问题,再谈搭建
很多企业一上来就买工具,结果建成的知识库要么“空有其表”,要么“水土不服”。我们总结了需求诊断三问:
- 业务场景是否需要“跨模态推理”?比如客服场景,用户发一段语音描述问题+一张截图,系统需要同时理解语音内容和图像信息才能给出答案;
- 现有数据的“模态分布”如何?如果80%是文本,20%是图片,强行融合音视频反而会增加系统复杂度;
- 终端用户的“使用习惯”怎样?生产车间的一线工人可能更依赖语音输入,而研发人员习惯用网页检索,知识库需支持多模态交互。
2.2 数据盘点:从“垃圾堆”里淘金
某金融科技公司曾投入百万搭建知识库,结果上线后发现90%的查询返回“无结果”——问题出在数据盘点阶段:他们把3年前的过期合同、重复的内部邮件全扫了进去,却漏掉了销售团队的“实战话术文档”。
正确的数据盘点步骤:
- 按业务线划分数据域(如研发、客服、营销);
- 标注每类数据的模态(文本/图像/音视频)及质量(清晰度、完整性、时效性);
- 建立“数据价值评分卡”:
| 数据类型 | 时效性(1-5分) | 准确性(1-5分) | 业务关联度(1-5分) | 综合评分 |
|---|---|---|---|---|
| 新产品研发网页 | 5 | 4 | 5 | 14 |
| 客服通话录音 | 3 | 2 | 4 | 9 |
| 过期合同扫描件 | 1 | 1 | 2 | 4 |
评分低于6分的数据建议暂时不纳入,避免“垃圾进,垃圾出”。
三、全流程拆解:从0到1搭建多模态大模型知识库的7个关键步骤
3.1 步骤一:明确技术架构——“集中式”还是“分布式”?
多模态知识库的技术架构直接影响后期扩展性和成本。目前主流方案有两种:
| 架构类型 | 适用场景 | 优势 | 劣势 |
|---|---|---|---|
| 集中式架构 | 中小企业/单一业务线 | 开发成本低,维护简单 | 扩展性差,模态扩展需重构 |
| 分布式架构 | 大型企业/多业务线 | 支持弹性扩展,模态独立部署 | 开发成本高,需统一元数据 |
我们建议中大型企业优先选择分布式架构,比如采用“中心元数据管理+各模态独立存储”的模式:文本存向量数据库(如Milvus),图像存视觉特征库(如FAISS),音视频存音频特征库(如VGGish),通过元数据层实现跨模态关联。
3.2 步骤二:数据采集——“全量”还是“精准”?
某电商平台曾为了“全面性”,采集了所有用户评论、商品图片和客服视频,结果导致存储成本飙升,且大量低质量数据干扰模型训练。
正确的数据采集原则:
- 业务导向:只采集与核心业务强相关的数据(如电商的“商品详情页+买家秀+售后评价”);
- 质量优先:设置过滤规则(如文本去重率>80%的丢弃,图像分辨率<720P的跳过);
- 动态更新:通过API对接业务系统,实时采集新增数据(如销售合同的签署版本、新上线的培训视频)。
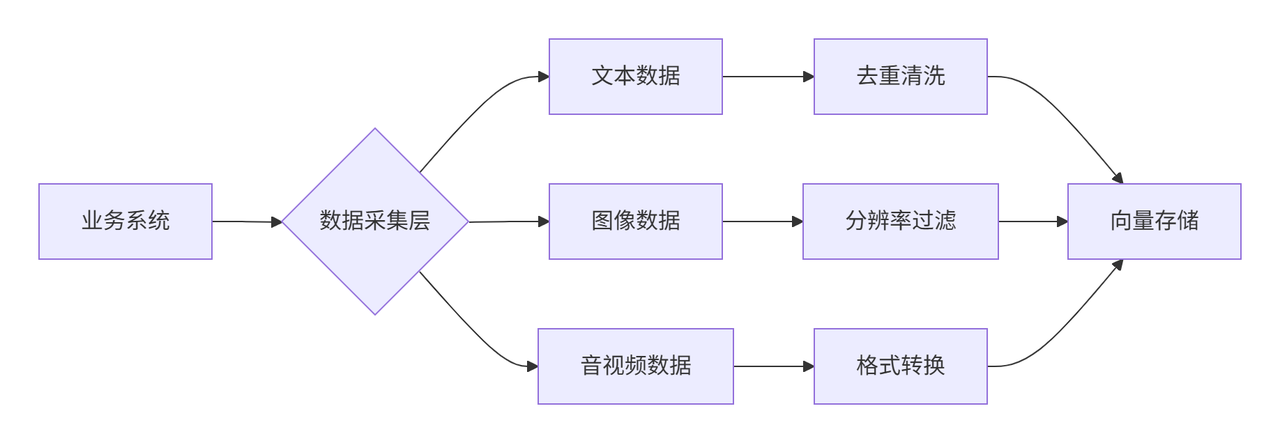
3.3 步骤三:多模态预处理——“清洗”比“加工”更重要
预处理是决定知识库质量的关键环节,不同模态的处理重点不同:
3.3.1 文本预处理:从“乱码”到“结构化”
- 去噪:去除广告、乱码、重复内容(可用正则表达式或NLP工具如spaCy);
- 实体标注:用命名实体识别(NER)提取关键信息(如产品名称、故障代码);
- 向量化:通过大模型(如LLaMA-3、Claude-3)生成文本嵌入向量。
3.3.2 图像预处理:让机器“看懂”细节
- 分辨率统一:调整为固定尺寸(如224×224);
- 特征提取:用ResNet、ViT等模型提取视觉特征向量;
- 内容审核:过滤敏感图片(如涉黄、违规标识)。

3.4 步骤四:存储架构设计——“存得下”更要“查得快”
多模态数据的存储需兼顾“容量”和“检索效率”。我们推荐“混合存储+向量索引”的方案:
- 冷数据(历史数据):存对象存储(如AWS S3、阿里云OSS),降低成本;
- 热数据(高频访问数据):存向量数据库(如Milvus、Chroma),支持快速检索;
- 元数据层:用关系型数据库(如MySQL、PostgreSQL)存储数据标签、存储路径、模态类型等信息,实现跨模态关联。
3.5 步骤五:模型训练——“通用大模型”还是“行业微调”?
某医疗企业直接使用通用大模型搭建知识库,结果医生查询“某种罕见病的影像特征”时,返回的结果全是通用病例。后来他们用自有医学影像数据对模型进行微调,准确率提升了60%。
模型选择建议:
- 通用场景:用Llama-3、Claude-3等通用大模型作为基座;
- 行业场景:基于行业数据微调(如医疗用PubMed数据,工业用工业缺陷数据集);
- 融合处理:训练“多模态指令微调”模型,学会理解“请结合网页第3页和故障视频前10秒,分析设备异常原因”这类跨模态指令。
3.6 步骤六:评估与优化——“好用”才是硬道理
搭建完成后,需从三个维度评估效果:
| 评估维度 | 指标 | 工具/方法 | 目标值(行业参考) |
|---|---|---|---|
| 知识覆盖率 | 覆盖业务问题的比例 | 人工抽样测试 | ≥85% |
| 检索准确率 | 返回结果的相关性 | NDCG(归一化折损累计增益) | ≥0.8 |
| 响应效率 | 从提问到返回结果的时间 | 压测工具(如JMeter) | ≤2秒 |
优化方向包括:调整向量维度(如从768维提升至1536维)、优化检索算法(如从余弦相似度改为内积)、增加反馈机制(用户点击数据反向训练模型)。
3.7 步骤七:安全与合规——别让“智能”变“风险”
多模态知识库涉及大量敏感数据(如客户隐私、商业机密),必须做好安全防护:
- 数据加密:存储时用AES-256加密,传输时用TLS 1.3;
- 权限控制:按角色分配权限(如客服只能访问客户对话数据,工程师可访问技术网页);
- 内容审核:对用户上传的内容(如UGC视频)进行实时审核,防止违规信息流入。
四、实战案例:某跨国制造企业的多模态知识库落地记
某德国汽车零部件企业(以下简称“X公司”)拥有全球12个工厂,每年产生超500TB的多模态数据(包括设计图纸、生产线视频、维修手册、客户投诉录音)。2024年初,他们启动多模态知识库项目,目标是“让全球工程师用同一套系统解决问题”。
4.1 挑战与破局
- 挑战1:多语言数据混杂(德语、英语、中文),传统翻译工具准确率低;
- 挑战2:生产线视频量大(每天新增2TB),存储和检索成本高;
- 挑战3:跨区域团队使用习惯不同(欧洲工程师爱用网页,亚洲工程师爱用视频)。
4.2 解决方案
- 多语言处理:用mT5模型进行多语言文本统一,结合图像特征弥补语言差异(如通过零件示意图识别“刹车盘”);
- 视频高效处理:采用“关键帧提取+音频转文本”双轨处理,视频存储量减少70%,检索时先查文本再关联视频;
- 个性化交互:前端设置“模式切换”按钮(网页模式/视频模式),后端通过用户行为数据(如点击偏好)自动推荐最优模态。
总结:多模态知识库的本质,是企业的“数字神经中枢”
如果把企业比作一个人,传统知识库是“记忆碎片”,多模态大模型知识库则是“大脑皮层”——它不仅能存储信息,更能通过跨模态理解、推理和创造,让企业的“经验”真正转化为“智能”。
搭建过程中,记住三个核心原则:需求驱动(不贪大求全)、数据质量(垃圾进不出)、安全合规(智能不越界)。未来,随着多模态大模型的进一步进化,能深度融合文本、图像、音视频的知识库,必将成为企业最核心的“数字资产”。
最后送大家一句话:最好的多模态知识库,不是技术堆砌的“花架子”,而是能解决实际问题的“工具箱”。从今天开始,整理你的“知识碎片”,让大模型帮你拼出智能新未来!


最新发布

热门推荐



