DeepSeek R1 模型为何如此强大? | 性能、架构与影响全面剖析
近日,国产AI大模型DeepSeek-R1的横空出世引发了全球AI圈的广泛关注。这款由深度求索(DeepSeek)公司开发的模型不仅在性能上号称可以对标OpenAI的o1模型,更以其开源开放的特性掀起了新一轮AI平权浪潮。那么,DeepSeek-R1到底有何过人之处?为什么它能在短时间内引起如此巨大的反响?今天我们将从多角度深入解析这款爆款模型的核心优势。

一、DeepSeek R1模型的性能突破:与顶级AI一较高下
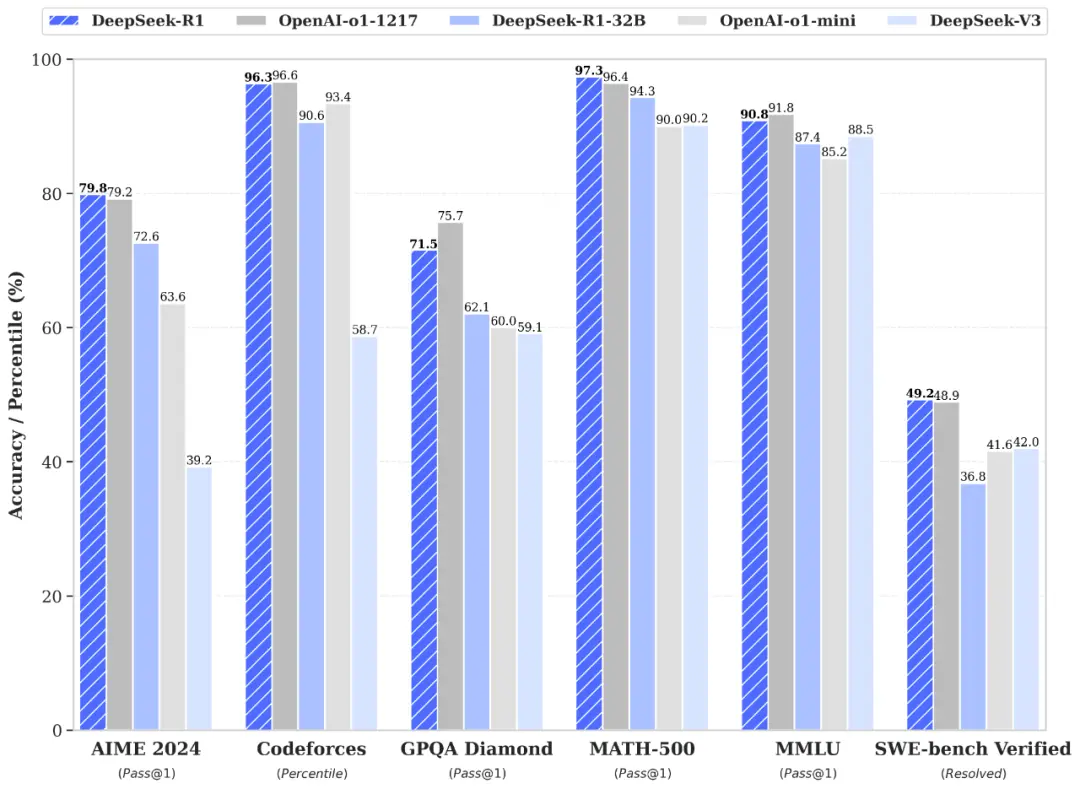
DeepSeek-R1最引人注目的特点就是其出色的性能表现。根据官方发布的信息,R1在数学、代码、自然语言推理等任务上的表现与OpenAI o1正式版相当。具体来看:
在教育导向的知识任务中,R1在MMLU基准测试上得分90.8分,接近o1的91.8分;在GPQA Diamond基准上得分71.5分,同样接近o1的75.7分。
在数学任务方面,R1表现尤为突出。在AIME 2024基准上,R1得分79.8分,与o1的79.2分几乎持平。
编码能力同样不俗,在Codeforces基准测试中,R1得分2029分,超过了96.3%的人类参赛者,与o1的2061分相差无几。
这种全面的性能表现,使得R1成为首个在多项关键指标上追平甚至超越闭源顶级模型的开源AI模型。
二、DeepSeek R1模型如何实现低成本高性能
除了性能优异,DeepSeek-R1的另一大亮点是其惊人的低成本。根据官方披露,R1的基础模型DeepSeek-V3的总训练成本仅为557.6万美元。相比之下,业内普遍估计GPT-4的训练成本在数亿美元级别。这种显著的成本优势主要得益于以下几个方面:
2.1 模型架构优化
- 稀疏化设计:采用混合专家系统(MoE),动态激活部分参数(如仅调用2-3个专家模块),在保持模型容量的同时显著降低计算量。
- 高效注意力机制:使用稀疏注意力*如局部窗口注意力)或线性注意力,将计算复杂度从\(O(n^2)\)降至\(O(n)\),减少长序列处理的资源消耗。
- 轻量化模块:替换传统模块(如深度可分离卷积、低秩分解),或通过参数共享(如ALBERT式跨层参数复用)压缩模型体积。
2.2 训练策略创新
- 知识蒸馏:用高性能大模型(教师模型)指导R1(学生模型)学习,保留关键知识的同时减少参数量。
- 渐进式训练:分阶段训练(如先训练小规模模型,逐步扩展),或采用课程学习(Curriculum Learning)按数据难度递增训练,提升收敛效率。
- 动态计算分配:对简单样本使用低计算路径,复杂样本分配更多资源(如动态网络宽度/深度),避免资源浪费。
2.3 数据与算法优化
- 数据高效利用:
- 高质量数据清洗:通过规则过滤、去重和语义聚类,提升数据信息密度。
- 合成数据增强:利用LLM生成高质量合成数据,降低数据标注成本。
- 算法改进:
- 优化器调参:使用自适应优化器(如Lion、Sophia)加速收敛,减少训练步数。
- 梯度压缩与通信优化:在分布式训练中减少节点间通信开销。
2.4 工程与硬件级优化
- 混合精度训练:结合FP16/FP32,利用NVIDIA Tensor Core加速计算,节省显存和训练时间。
- 模型压缩技术:
- 量化推理:部署时将权重从FP32转为INT8/INT4,减少内存占用和推理延迟。
- 结构化剪枝:移除冗余神经元或注意力头,保持性能的同时缩小模型体积。
- 分布式训练优化:
- 3D并行(数据并行+流水并行+张量并行),结合ZeRO显存优化技术,降低单卡负载。
- 弹性计算资源调度:按需分配云资源,避免训练集群空闲浪费。
2.5 自研技术创新
- 硬件适配算法:针对特定加速器(如GPU/TPU)定制算子(如FlashAttention-2),提升计算效率。
- 内存管理技术:
- 激活重计算(Activation Checkpointing):用时间换空间,减少显存占用。
- 动态显存分配:按计算阶段动态调整内存分配策略。
2.6 成本-性能平衡设计
- Pareto最优权衡:通过大量实验找到模型规模、训练数据和计算资源的平衡点,避免过度参数化。
- 端到端优化:从数据预处理到推理部署全链路优化,例如通过模型编译技术(如TVM、TensorRT)生成硬件适配的高效推理代码。
2.7 实际效果
- 训练成本:相比稠密模型,MoE架构可降低50%+训练成本(相同参数量下计算量更少)。
- 推理速度:量化+剪枝后,推理延迟降低3-5倍,适合边缘设备部署。
- 性能保持:通过知识蒸馏和稀疏化设计,性能损失控制在1-2%以内。
通过上述多维度协同优化,DeepSeek R1在控制硬件投入、数据成本和能耗的同时,实现了接近更大规模模型的性能表现。
三、开源开放:DeepSeek R1模型引领AI民主化浪潮
DeepSeek-R1最引人瞩目的特点,莫过于其坚持开源开放的理念。团队不仅完全开源了模型权重,还采用了极为宽松的MIT License。这意味着开发者可以自由使用、修改甚至商用R1模型,无需额外授权。
更值得一提的是,DeepSeek还明确允许用户通过模型蒸馏等方式训练其他模型。这一举措极大地促进了AI技术的传播与创新。自R1发布以来,全球多个顶级研究团队已经开始尝试复现其训练过程,包括UC伯克利、港科大等。
这种开放态度不仅赢得了开发者的青睐,也引发了业界对AI平权的热烈讨论。有观点认为,R1的出现标志着开源模型在性能上首次真正追平甚至超越了闭源顶级模型,为AI技术的民主化带来了新的可能。
四、DeepSeek R1模型背后的技术创新:解密其强大实力
DeepSeek-R1的成功并非偶然,而是建立在一系列技术创新之上:
1、纯强化学习训练:R1-Zero模型采用纯强化学习方法训练,无需任何监督微调数据即可获得强大的推理能力。这种方法使模型自然地学会了通过更多思考时间来解决复杂问题。
2、多阶段训练策略:R1模型在R1-Zero的基础上,通过冷启动、大规模强化学习、SFT数据融合等多个阶段的训练,既保证了推理能力,又提高了输出的可读性。
3、组相对策略优化算法(GRPO):这一创新算法使模型能够自发学习"反思"能力,有效缓解了大模型的幻觉问题。
这些技术创新不仅提升了模型性能,更为未来AI技术的发展指明了新的方向。

五、产业变革:DeepSeek R1模型对AI行业的深远影响
DeepSeek-R1的横空出世,对整个AI产业都产生了深远影响:
-
促进技术创新:R1的成功激发了更多团队投入到AI基础研究中,有望加速整个行业的技术进步。
-
降低应用门槛:低成本高性能的特性,使得更多中小开发者有机会参与到AI应用开发中来。
-
推动商业模式变革:开源模式的成功,可能促使一些闭源模型厂商重新考虑其策略。如OpenAI已表示正在讨论开源部分模型。
-
加速AI民主化:R1为小模型带来强大推理能力的方法,有望大幅降低AI应用的硬件门槛,推动AI技术向更广泛的场景普及。

六、深入剖析DeepSeek R1模型的架构创新
DeepSeek R1模型的成功,很大程度上归功于其独特的架构设计。让我们深入了解一下这些创新:
6.1 DeepSeekMoE:DeepSeek R1模型的核心架构
DeepSeek R1采用了一种名为DeepSeekMoE的混合专家架构(Mixture of Experts,MoE)。这种架构的核心思想是将大型神经网络分解为多个较小的"专家"网络,每个专家负责处理特定类型的输入。
具体来说,DeepSeekMoE的创新点包括:
- 更细粒度的专家划分:相比传统MoE,DeepSeekMoE增加了专家数量,但减小了每个专家的规模,提高了模型的灵活性和效率。
- 部分共享专家:一些专家被设计为多个任务共享,这不仅提高了资源利用率,还促进了知识的跨任务迁移。
- 动态路由机制:根据输入的不同,模型能够动态选择最合适的专家组合,大大提升了模型的适应性和性能。
6.2 MLA算法:提升DeepSeek R1模型计算效率的秘密武器
为了进一步提高计算效率,DeepSeek团队开发了多头潜在注意力(Multi-head Latent Attention,MLA)算法。这一算法的核心思想是通过低秩联合压缩注意力键值,显著减少推理时的计算量。
MLA算法的主要优势包括:
- 降低内存占用:通过压缩注意力机制的中间表示,大幅减少了模型的内存需求。
- 加速推理:简化的注意力计算过程使得模型在推理阶段能够更快速地处理输入。
- 保持性能:尽管进行了压缩,MLA算法仍能保持模型的高性能表现,几乎不影响输出质量。
七、DeepSeek R1模型的训练策略创新
除了架构上的创新,DeepSeek R1在训练策略上也采用了多项创新方法,这些方法对模型的最终性能起到了关键作用。
7.1 纯强化学习**:DeepSeek R1模型的训练突破**
R1-Zero模型采用了一种纯强化学习的训练方法,这在大语言模型领域是一个相当大胆的尝试。传统的语言模型通常依赖于大量的监督数据进行训练和微调,而纯强化学习方法则完全依靠模型与环境的交互来学习。
这种方法的优势在于:
自主学习:模型能够通过不断尝试和反馈来自主学习解决问题的策略,而不是简单地模仿训练数据。
更强的推理能力:通过反复试错,模型自然地学会了在面对复杂问题时进行更深入的思考和推理。
减少人为偏见:由于不依赖人工标注的数据,这种方法可以在一定程度上减少训练数据中可能存在的人为偏见。
7.2 多阶段训练:打造DeepSeek R1模型的全面实力
在R1-Zero的基础上,DeepSeek团队采用了一种精心设计的多阶段训练策略来开发最终的R1模型:
冷启动阶段:使用传统的监督学习方法,让模型快速掌握基础的语言能力。
大规模强化学习阶段:采用强化学习方法,提升模型的推理和问题解决能力。
SFT数据融合阶段:引入监督微调(Supervised Fine-Tuning,SFT)数据,平衡模型的推理能力和输出可读性。
这种多阶段策略既保证了模型的强大推理能力,又确保了输出的流畅性和可读性,是R1模型卓越性能的关键所在。
7.3 GRPO算法:解决DeepSeek R1模型的"幻觉"难题
为了解决大语言模型常见的"幻觉"问题(即生成看似合理但实际上不正确的内容),DeepSeek团队开发了组相对策略优化(Group Relative Policy Optimization,GRPO)算法。
GRPO的核心思想是:
1、对比学习:通过比较不同策略生成的答案,模型学会了区分更优质的回答。
2、自我反思:算法鼓励模型在给出答案后进行"反思",评估自己答案的质量。
3、动态调整:根据反思结果,模型能够动态调整其策略,不断提高输出质量。
这一创新算法使得R1模型能够生成更加准确、可靠的内容,大大减少了"幻觉"的发生。
八、DeepSeek R1模型引发的AI生态变革
DeepSeek R1的出现不仅仅是技术上的进步,更对整个AI生态产生了深远的影响:
8.1 开源社区的新活力:DeepSeek R1模型的贡献
R1的开源发布极大地激发了开源AI社区的活力。越来越多的开发者和研究者开始参与到大语言模型的开发和优化中来,这无疑将加速AI技术的整体进步。
8.2 商业模式重塑:DeepSeek R1模型带来的行业变革
R1的成功正在迫使一些主要依赖闭源模型的公司重新思考其商业策略。我们可能会看到更多的公司转向开源或部分开源模型,以保持竞争力。
8.3 AI民主化加速:DeepSeek R1模型降低应用门槛
R1为小型设备带来强大推理能力的方法,有望大幅降低AI应用构建的硬件门槛。这意味着更多的个人和小型组织将有机会开发和部署AI应用,推动AI技术向更广泛的场景普及。
8.4 伦理与安全新挑战:DeepSeek R1模型开源的影响
随着强大的AI模型变得更加accessible,如何确保这些技术被负责任地使用成为一个迫切需要解决的问题。R1的开源特性也引发了业界对AI安全和伦理问题的更多讨论。
九、持续迭代:不断进化的 “智能引擎”
从 DeepSeek LLM 到 DeepSeek-V2 的升级过程中,模型在多个方面实现了显著提升。在参数规模上,从最初的版本逐步发展到拥有 236 亿参数(其中 21 亿个参数被激活)的 DeepSeek-V2,模型的性能得到了极大增强。
在多语言支持方面,DeepSeek-Coder 能够支持 Python、C++、Java 等多种编程语言。不同版本的模型在多种编程语言上都展示出了良好的支持能力,尽管在不同语言上的表现存在差异,但整体上为开发者提供了更广泛的应用选择。
在生成质量上,DeepSeek-V2 在推理得分和 MMLU 分数上表现出色,不仅推理能力增强,语言流畅性和生成质量也得到了显著提升。DeepSeek-67B 通过使用多头注意力和分组查询注意力等技术,在翻译、问题回答和填空任务等多种任务上都表现优异。
DeepSeek 系列模型在持续迭代过程中,还采用了多种优化技术,如 Cosine LR scheduler、AdamW 优化器等,这些技术进一步提高了训练效率和模型性能。
其实我们不难总结出,DeepSeek R1 模型的强大并非偶然,而是源于其创新的架构设计、高效的训练方法、在多领域的卓越表现、出色的工程优化以及持续的迭代升级。它在性能与效率之间找到了完美的平衡,适用于需要高精度推理的复杂场景,如数学推理、代码生成等领域。尽管在实时性要求极高的场景中,需要权衡生成速度与准确性,但随着技术的不断发展和优化,相信 DeepSeek R1 模型将在更多领域发挥重要作用,为人工智能的发展带来更多的惊喜和突破。在未来,我们期待看到 DeepSeek R1 模型不断进化,为推动人工智能技术的进步做出更大的贡献。

最新发布

热门推荐



