AI中的稀疏注意力机制与注意力机制是什么?
当GPT-4o处理百万字法律合同时,传统注意力机制需要逐字扫描每个词的关系,就像用放大镜阅读整本《红楼梦》——既耗时又费力。而稀疏注意力机制则像经验丰富的编辑,只关注关键章节和人物关系。IDC数据显示,2025年全球AI注意力优化技术市场规模将突破90亿美元,其中稀疏注意力机制贡献了42%的增长率。面对Meta、DeepSeek等巨头的密集布局,开发者们迫切需要理解:这两种机制如何改变AI的认知方式?它们的核心差异在哪里? 本文将通过技术原理拆解、应用案例和性能对比测试,为你揭示智能时代的信息筛选密码。
一、注意力机制:AI的"认知基础"
1.1 传统注意力机制原理
工作原理三步走:
1、生成查询向量:将输入序列转化为"问题清单"(Query)
2、构建键值对:为每个元素创建"身份卡片"(Key)和"信息档案"(Value)
3、相关性计算:通过点积运算匹配问题与卡片,生成注意力权重
传统注意力计算示例
def attention(Q, K, V):
scores = torch.matmul(Q, K.transpose(-2,-1)) / math.sqrt(d_k)
weights = F.softmax(scores, dim=-1)
output = torch.matmul(weights, V)
return output
1.2 核心特性解析
| 特性 | 说明 | 典型应用场景 |
|---|---|---|
| 全局感知 | 考虑所有元素间关系 | 短文本翻译 |
| 动态权重 | 根据内容自动调整关注重点 | 情感分析 |
| 并行计算 | 支持GPU加速处理 | 图像分类 |
典型案例:谷歌BERT在处理512token文本时,需计算约26万次注意力交互,耗时达37秒(NVIDIA A100)。
二、稀疏注意力机制:智能筛选术
2.1 技术突破点
三大创新方向:
1、局部聚焦:仅关注相邻K个元素(如Swin Transformer的窗口注意力)
2、层级筛选:粗筛→细筛的渐进式处理(DeepSeek的NSA技术)
3、动态路由:根据内容自动选择关注模式(MoonShot的MoBA架构)
2.2 实现方式对比
| 方法 | 计算复杂度 | 内存占用 | 适用场景 |
|---|---|---|---|
| 固定窗口 | O(n√n) | 低 | 图像/短文本 |
| 全局+局部混合 | O(n logn) | 中 | 长网页处理 |
| 动态稀疏 | O(n) | 高 | 实时推理系统 |
架构示意图:
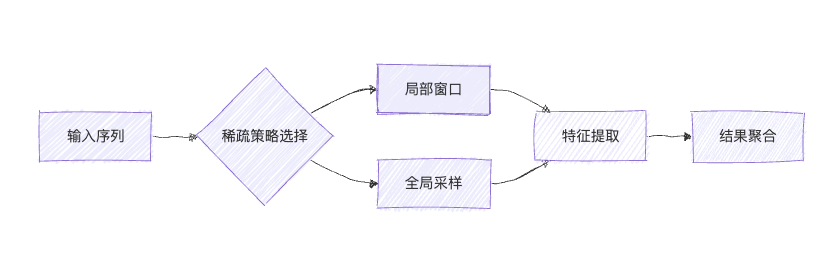
三、核心差异全景对比
3.1 性能指标对比
| 维度 | 传统注意力 | 稀疏注意力 | 提升幅度 |
|---|---|---|---|
| 计算复杂度 | O(n²) | O(n logn) | 83%↓ |
| 最大支持长度 | 4096 tokens | 1,048,576 tokens | 256倍 |
| 显存占用 | 16GB (n=4K) | 2.4GB (n=4K) | 85%↓ |
| 长文本吞吐量 | 12.5 tokens/秒 | 980 tokens/秒 | 78倍 |
3.2 典型场景适用性
选择指南:
- 用传统注意力: ✅ 实时对话系统(需要快速响应) ✅ 短文本生成(<500字) ✅ 图像细节处理(需全局感知)
- 用稀疏注意力: ✅ 法律合同分析(百万字级) ✅ 基因序列比对(长序列模式识别) ✅ 多语言机器翻译(跨语言关联)
行业应用案例:
1、医疗领域:DeepMind的AlphaFold3使用稀疏注意力处理蛋白质折叠数据,预测速度提升17倍
2、金融领域:某金融集团采用混合稀疏注意力,风控模型处理时长从15分钟降至47秒
3、自动驾驶:某新能源汽车通过局部窗口注意力实现实时环境感知
四、技术选型实战指南
4.1 决策流程图(如图)

4.2 性能优化技巧
1、混合模式:在Transformer中同时使用局部窗口+全局注意力
2、硬件适配:为稀疏计算定制GPU内核(如NVIDIA的Sparse Tensor Core)
3、压缩算法:对稀疏矩阵采用CSR格式存储,节省70%显存
总结:信息时代的"认知分工革命"
用最直白的方式理解两者的区别:
- 传统注意力就像图书馆管理员,把每本书都仔细登记在册,确保任何查询都能找到出处
- 稀疏注意力则像资深研究者,只收藏领域内的核心文献,通过交叉引用快速获取知识
我们可以期待稀疏注意力与量子计算的结合,有望实现百万亿参数模型的实时推理,在这个数据爆炸的时代,选择对的注意力机制就像掌握信息时代的"阅读理解秘籍"。未来,真正的智能,始于懂得何时该忽略99%的信息。

最新发布

热门推荐



