大模型知识库技术全景图及如何基于DeepSeek构建知识库
随着人工智能和大模型技术的飞速发展, 大模型知识库 成为了企业智能化升级的核心基础设施。它能够有效解决大模型在特定领域的知识不足、信息滞后以及产生 "幻觉" 等问题。通过将大规模文本数据进行预训练,并结合知识图谱等技术,大模型知识库可以实现知识信息的准确检索与回答,为用户提供更智能、更高效的服务。据Gartner预测,到2026年,75%的企业将把构建和维护大模型知识库作为AI战略的核心组成部分。
但如何构建一个高效、可靠的大模型知识库? 其中涉及哪些关键技术和方法?本文将对此进行深度解析,并结合 DeepSeek 模型进行案例剖析。
一、大模型知识库:核心概念与价值
大模型知识库,本质上是一种将预训练语言模型与知识图谱精妙融合的复杂信息系统。通俗来讲,它就如同给大模型精心外挂了一个 “资料室”,不动声色地拓展模型的知识疆域,全方位提升其在特定领域的专业造诣。
其蕴含的核心价值熠熠生辉:
- 知识增强:宛如一场及时雨,精准弥补大模型在垂直领域知识储备上的短板,显著提高回答的准确性。当面对专业领域的刁钻问题时,能依托丰富知识给出令人信服的精准答案。 信息更新:恰似一台时光穿梭机,巧妙化解大模型知识的时效性难题,确保它能对最新热点问题对答如流。无论是瞬息万变的财经动态,还是日新月异的科技突破,都能实时掌握。 降低幻觉:如同给大模型戴上了 “紧箍咒”,通过严谨检索外部知识,大幅减少它 “一本正经胡说八道” 的尴尬情形 ,输出内容更具可信度。 智能检索:仿若拥有一双慧眼,摒弃简单粗暴的关键词匹配,实现基于语义的深度检索,精准定位所需知识。

二、大模型知识库的技术构成
一个典型的大模型知识库,宛如一台精密复杂的机器,由多个核心模块协同驱动:
1、知识图谱:以一种直观形象的图结构,将实体间千丝万缕的关系巧妙存储与呈现,完成知识的结构化梳理。在这里,每个实体都化身为一个节点,关系则是连接节点的纽带 —— 边。例如在影视知识图谱中,“电影”“导演”“演员” 等是实体,它们之间的参演、执导关系就是边,构成了完整的知识网络。
2、文本语料库:仿若一个浩瀚的知识宝库,静静存储海量文本数据,既为模型训练输送源源不断的养分,也是提取知识的富矿。从学术论文到新闻报道,从专业书籍到社交媒体言论,无所不包。
3、推理引擎:如同一位智慧超群的侦探,运用形形色色的推理算法与前沿技术,从已有知识中敏锐挖掘新的知识宝藏,持续提升知识库的完整性与准确性。它能依据已知的人物关系、事件因果,推导出全新的知识关联。
此外,还常常涵盖:
- 实体识别与链接:精准识别文本中的实体,并将其与知识图谱中的对应节点无缝链接,打通知识脉络。
- 关系抽取:从文本里巧妙抽取出实体间的微妙关系,进一步丰富知识图谱架构。
- 问题回答:作为直接面向用户的窗口,依据知识库储备,快速、精准回应用户的各类疑问。
这些模块紧密协作,如同交响乐团各声部默契配合,共同构建并精心维护企业知识库,为用户呈献准确、丰富的知识盛宴 。
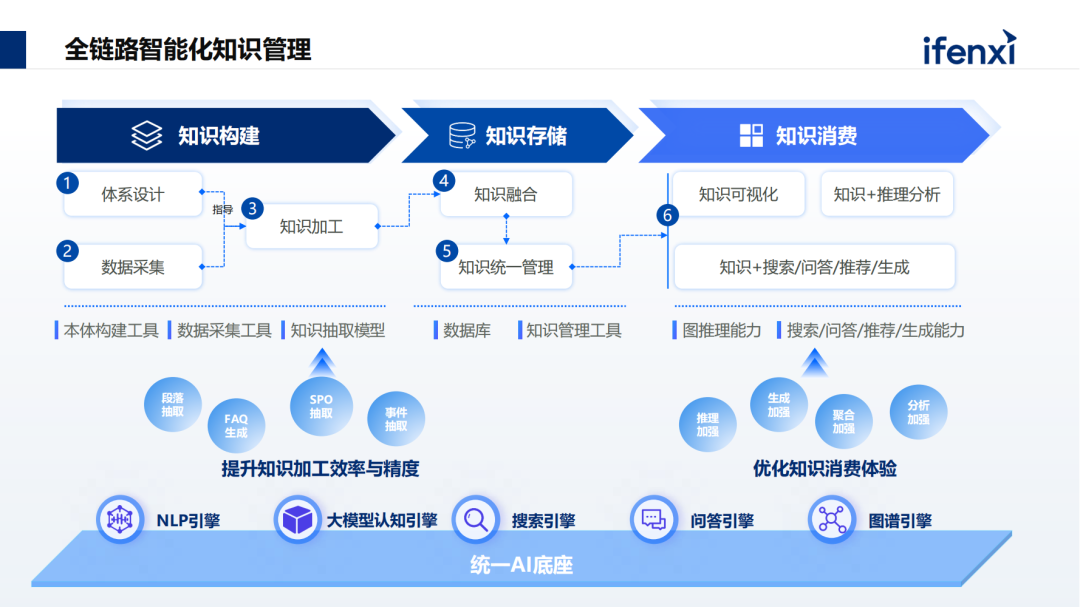
三、大模型知识库7大核心实现方法详解
1、文档加载 (Document Loading):知识宛如一位千面佳人,形态各异,涵盖文本 (txt, word, pdf) 、图片、结构化 / 非结构化数据等多种形式。文档加载技术恰似一位万能钥匙匠,必须支持五花八门的文档格式以及多样的加载路径,无论是本地硬盘的珍藏资料,还是网络云端的海量信息,都能轻松摄取。
2、文档分割 (Document Splitting):鉴于大模型存在上下文长度的 “紧箍咒”,冗长文本不得不分割成更小巧的模块。分割策略绝非一成不变,而是依据任务场景灵活应变,诸如分割长度的精准把控、形式的巧妙抉择(段落、标点符号等皆有可能)以及重叠长度的精细设置,确保知识传递的流畅性与完整性。
3、词嵌入 (Word Embedding):如同神奇的翻译官,将文本巧妙转换为大模型能够识别的向量格式,为语义搜索的实现铺就坦途。借此,基于语义的查询得以成真,彻底告别简单机械的关键词匹配,让检索更加智能精准。
4、向量数据库 (Vector Database):仿若一座高速运转的知识仓储中心,专门用于存储并高效索引向量化的文档,实现知识检索的风驰电掣。市面上常见的向量数据库包括 FAISS、 Milvus、 Weaviate 等,它们各显神通,为知识的快速调取立下汗马功劳。
5、检索增强生成 (RAG):此乃大模型知识库的核心 “魔法”。在向大模型抛出问题之前,先凭借敏捷身手从向量数据库中飞速检索出与问题紧密相关的内容,随后将这些检索成果作为珍贵的上下文,一并输送给大模型。这般操作之下,大模型便能站在知识巨人的肩膀上生成答案,极大减少 “幻觉”,输出更靠谱的内容。
6、知识图谱构建:仿若一位技艺精湛的雕刻师,从文本数据的原始素材中精心提取实体、关系等关键信息,匠心独运地构建知识图谱。知识抽取方法丰富多样,涵盖基于规则的严谨推导、基于统计的规律探寻以及基于深度学习的智能挖掘,各展所长,勾勒知识蓝图。
7、推理引擎:基于知识图谱这一坚实基石展开推理,仿若开启一场奇妙的知识探险,不断发现新的知识宝藏。推理方法包罗万象,既有逻辑严密的逻辑推理,依循因果链条步步推导;也有基于数据规律的统计推理,从海量信息中洞察趋势,持续拓展知识边界。

四、DeepSeek R1在大模型知识库中的创新应用
DeepSeek 是一家中国AI初创公司,其大模型在多个基准测试中表现出色。 在知识摄取与整合方面,DeepSeek R1 模型展现出非凡实力:
- 多源知识汇聚:它仿若拥有一张无形的知识大网,能够从海量且繁杂的数据源中高效摄取知识养分。无论是晦涩难懂的学术文献、详实专业的行业报告、厚重权威的专业书籍等结构化文本,还是灵动多变的社交媒体热评、百家争鸣的论坛讨论、实时更新的新闻资讯等非结构化文本,统统都能被精准纳入知识库的怀抱。例如,在面对前沿科技领域的疑难问题时,它能闪电般抓取顶尖科研论文中的最新研究突破、行业动态资讯中的前沿技术趋势剖析,将这些碎片化却弥足珍贵的知识碎片精心汇总,为后续决策筑牢根基。
- 动态更新机制:依托其独具匠心的自演进知识库,DeepSeek R1 模型精心搭建了一套智能的动态更新体系。随着新知识如潮水般不断涌现,模型宛如一位警觉的守望者,实时监测并凭借敏锐眼光筛选出与已有知识库紧密关联且极具价值提升潜力的信息。以风云变幻的金融领域为例,每当新的货币政策重磅出台、金融监管规则悄然变化或重大财经事件突发时,模型能够迅速捕捉到这些动态信号,将相关的深度解读、专业分析及影响预测巧妙整合进知识库,确保知识储备始终与时代脉搏同步跳动,为后续决策提供精准如矢的依据。
在知识关联与推理层面,DeepSeek R1 模型更是技高一筹:
- 跨领域知识关联:它仿若一位知识跨界大师,擅长冲破知识领域之间的无形壁垒,精心编织起广泛而紧密的知识网络。在处理错综复杂的问题时,它能够举重若轻地调用不同领域的知识模块,实现协同推理的精彩演绎。比如,在攻克智能城市规划中的交通拥堵与能源消耗协同优化难题时,模型不仅娴熟运用交通工程学知识规划最优路线、科学设置信号灯时长,还会融会贯通地结合能源领域前沿知识,细致考虑车辆行驶路线对能源消耗的微妙影响,最终综合给出既显著缓解拥堵又大幅降低能耗的完美方案,将跨领域知识融合的强大威力展现得淋漓尽致。
- 基于知识的深度推理:面对需要深度剖析的棘手问题,DeepSeek R1 模型充分利用知识库中的知识链,开启层层递进的推导之旅。在医学诊断这一关乎生死的场景中,当遭遇疑难病症的挑战时,它能够依据海量临床病例、前沿医学研究成果等深厚知识储备,从细微的症状表现出发,通过多轮缜密推理排查可能的病因,再结合类似病例的成功治疗经验给出个性化、精准化的诊断建议和治疗方案,绝非简单的症状匹配可比,极大提高了诊断的准确性与科学性,为患者点亮希望之光。
五、如何基于 DeepSeek 大模型构建自有知识库
随着 DeepSeek 大模型展现出的卓越性能,众多企业纷纷心动,渴望基于该模型搭建自有知识库,实现智能化转型,提升核心竞争力。
(一)数据准备阶段
- 确定核心业务知识领域:企业需如一位精准的狙击手,深入剖析自身业务,明确与核心竞争力紧密缠绕的知识领域。例如,一家专注制造业的企业,应聚焦产品研发的创新突破、生产工艺的精益优化、供应链管理的高效协同等关键板块;而金融机构则要把目光牢牢锁定在风险评估的精准把控、投资策略的明智抉择、客户信用分析的细致入微等要害之处。精准定位知识领域,恰似为后续的数据收集与模型训练校准了瞄准镜,避免资源在茫茫信息海洋中盲目浪费。
- 收集与整理数据:围绕已确定的核心业务领域,展开一场知识的 “大搜捕”,广泛收集各类数据。既包括企业内部沉淀多年的结构化数据,如生产数据库中蕴含的工艺参数、客户交易记录里潜藏的消费偏好、财务报表中反映的经营状况等,也涵盖来自外部世界的行业资讯、市场调研数据、竞争对手动态等非结构化数据。同时,运用数据清洗、去噪、标准化等精细工艺,为模型精心烹制高质量的 “原料”,确保输入数据的纯净与可靠。
(二)模型适配与训练
- 定制化模型微调:企业要依据自身业务独特的纹理与需求,利用 DeepSeek 大模型的高度灵活性,对其进行量身定制的微调。在微调过程中,巧妙融入企业专属的标注数据,如产品缺陷案例及对应的解决方案、客户细分标签及配套的营销策略等,让模型如同一位深入企业内部的资深员工,深度理解企业独特的业务逻辑和知识模式,从而在内部决策、客户服务等关键场景中发挥更大效能。
- 持续训练与优化:知识的更新换代如闪电般迅速,企业必须构建持续训练的 “高速引擎”,让模型紧紧跟随业务发展的滚滚车轮。定期将新产生的数据精准反馈给模型进行再训练,同时结合业务指标,如客户满意度的显著提升、成本的有效降低、生产效率的大幅提高等实际效果,精准判断模型的优化方向,确保模型始终与企业业务发展的步伐高度契合。
(三)知识库应用与维护
- 多场景应用部署:将基于 DeepSeek 大模型精心构建知识库广泛撒播到企业各个业务场景。在市场营销的战场上,利用模型深度剖析客户需求、精准预测市场趋势,制定出奇制胜的营销策略;在客户服务的前沿阵地,快速解答客户咨询、妥善处理投诉,全方位提升服务质量;在内部运营管理的大后方,辅助决策制定、优化流程设计,提高运营效率。通过全方位、多层次的应用,让知识库的价值得到充分释放。
- 知识维护与更新:设立一支专业的知识管理 “特战队”,负责知识库的日常维护与更新。一方面,及时将企业内部新诞生的研发成果、优化后的流程、成功的营销案例等宝贵知识录入知识库,使其成为企业智慧的沉淀;另一方面,持续关注外部行业的风云变幻,将有价值的新知识无缝融入,保持知识库的鲜活与竞争力,让企业在知识的滋养下茁壮成长。
六、大模型知识库构建的挑战与解决方案
构建大模型知识库的征程绝非一马平川,而是荆棘丛生,面临诸多棘手挑战:
- 计算资源需求:大模型的训练与推理仿若一头超级巨兽,对计算资源有着海量需求。每一次参数更新、每一轮模型迭代,都需要耗费惊人的算力,普通硬件设施往往不堪重负。
- 数据隐私安全:知识库仿若一个装满珍贵珠宝的宝库,其中可能隐匿着大量敏感数据,一旦泄露,后果不堪设想。如何筑牢安全防线,防范数据被窃取、篡改,成为重中之重。
- 模型可解释性:大模型宛如一个神秘黑箱,其决策过程晦涩难懂,在医疗、金融等对决策透明度要求极高的领域,这种 “黑箱” 特性严重阻碍了其深入应用。
针对这些拦路虎,我们并非束手无策,而是有一系列对症下药的良方:
- 采用分布式训练和推理:通过将庞大的计算任务巧妙拆解,分散到多个节点协同完成,如同蚂蚁搬家,大幅降低对单个节点的计算资源压榨,让算力需求不再成为瓶颈。
- 实施严格的数据加密和访问控制策略:运用先进的加密算法,为数据披上坚不可摧的 “铠甲”,同时精细设置访问权限,只有经过授权的人员才能触碰敏感数据,确保数据安全万无一失。
- 研究可解释性AI技术:致力于揭开大模型的神秘面纱,通过可视化技术、特征归因等方法,让模型的决策过程清晰可见,提高模型的透明度,增强用户信任。
麦肯锡最新研究指出,全面采用大模型知识库技术的企业,运营效率可提升40%,决策质量提高55%。在这个知识驱动的新时代,掌握核心实现方法的企业将获得决定性竞争优势。技术的终极目标,是让人类站在AI的肩膀上,触及认知的新边疆。
DeepSeek R1模型的爆火为企业应用大模型知识库技术带来了新的可能性,通过本文对R1模型在7大核心实现方法中的应用分析,我们可以看到开源大模型在企业知识管理和创新中的巨大潜力。未来,随着R1模型及其生态系统的不断发展,我们有理由相信更加智能、高效、开放的知识库系统将为企业数字化转型提供强大动力,开创智能决策和知识创新的新纪元。

最新发布

热门推荐



