生成式AI ≠ 大模型 ≠ 判别模型,别再傻傻分不清!
最近和几个AI从业者聊天,发现一个有意思的现象:很多人把“生成式AI”“大模型”“判别模型”这三个概念混为一谈,甚至在实际业务中张冠李戴——比如用判别模型强行做文本生成,或者认为“大模型=生成式AI”。上周我帮一家传统企业做AI选型咨询时,对方CTO更直接:“我们花大价钱买了大模型,怎么生成的文案还不如小模型?”这让我意识到,厘清这三个概念的边界,已经是AI落地最基础的必修课了。
今天这篇文章,我们就从底层逻辑到应用场景,把这三个概念的区别、联系和典型误区一次性讲透。无论你是技术决策者、业务负责人,还是单纯想搞懂AI热词的爱好者,读完都能建立清晰的认知框架。
一、从基础定义出发:生成式AI、大模型、判别模型的本质区别
要理解三者的关系,首先要回到最朴素的定义。这三个概念并非同一维度的分类,而是分别对应“能力类型”“技术载体”“方法流派”——就像“汽车”“发动机”“燃油驱动”之间的关系,既有重叠又不等同。
1.1 生成式AI:从“模仿”到“创造”的能力跃迁
生成式AI(Generative AI)的核心是“创造新内容”。它通过学习数据中的模式,生成人类难以直接编写或设计的输出,比如写小说、画油画、设计药物分子,甚至模拟对话。与传统的“输入-指令-输出”模式不同,生成式AI的输出往往是开放式的、非结构化的,且具备一定的“创造性”。
举个生活中的例子:你用MidJourney输入“夕阳下的海边城堡,赛博朋克风格”,它生成的图片既符合描述,又带有独特的色彩和光影——这就是典型的生成式AI能力。相关资料表明,当前生成式AI已在内容创作、代码生成、生物制药等领域实现商业化落地,全球市场规模预计2026年突破500亿美元。
1.2 大模型:参数规模的量变能否引发质变?
大模型(Large Model)通常指参数规模达到亿级甚至千亿级的深度学习模型,比如GPT-3.5(1750亿参数)、PaLM 2(3400亿参数)。它的本质是“通过大规模数据和参数,提升模型的泛化能力”。大模型可以是生成式的(如GPT系列),也可以是判别式的(如BERT),但近年来因生成式任务的爆发式需求,大模型与生成式AI的绑定越来越深。
需要注意的是,“大”不等于“好”。IDC 2025年发布的《大模型技术成熟度报告》指出,当前70%的企业级大模型应用存在“参数冗余”问题——盲目堆砌参数不仅导致训练成本飙升(千亿参数模型单次训练成本超百万美元),实际效果反而可能因数据质量不足而下降。
1.3 判别模型:经典机器学习的“决策专家”定位
判别模型(Discriminative Model)是传统机器学习的主流方法之一,核心是“学习输入到输出的映射关系”。它直接关注“给定输入X,输出Y的概率是多少”,比如垃圾邮件分类(输入邮件内容,输出“垃圾/非垃圾”)、图像识别(输入像素矩阵,输出“猫/狗”)。与生成式模型相比,判别模型的输出通常是结构化的、确定性的,且更依赖标注数据的质量。
举个反例:如果你用判别模型做文本生成,它只能根据训练数据中的“输入-输出”对“复制粘贴”类似内容,无法生成全新的句子——这正是判别模型与生成式AI的根本差异。
三者技术定位关系图
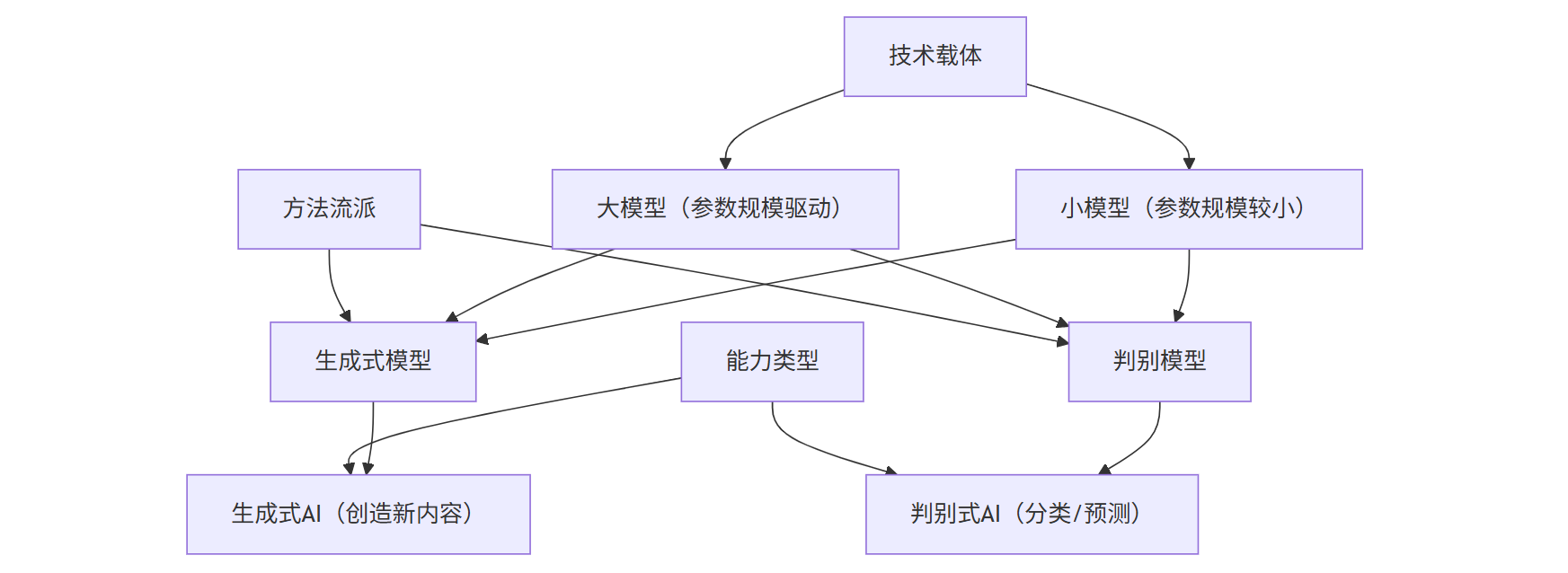
注:技术载体(大模型/小模型)可同时支持生成式/判别式模型;能力类型(生成式AI/判别式AI)是最终应用表现
二、技术路径拆解:生成式AI如何突破传统判别模型局限?
理解了定义,接下来要看技术路径的差异。生成式AI的“创造性”并非天生,而是源于对传统判别模型的突破。我们可以从“建模方式”“训练目标”“输出控制”三个层面展开分析。
2.1 建模方式:从“条件概率”到“联合概率”
判别模型的核心是学习P(Y|X)(给定X时Y的概率),比如判断邮件是否为垃圾邮件时,它只关心“这封邮件的内容(X)导致垃圾邮件(Y)的概率”。而生成式AI需要学习P(X,Y)(X和Y的联合概率),甚至P(X)(X的边缘概率)——这意味着它不仅要理解“垃圾邮件长什么样”,还要能“凭空造出一封像垃圾邮件的邮件”。
用数学公式对比更直观:
- 判别模型:P(Y=垃圾|X=邮件内容) = [P(X|Y=垃圾)P(Y=垃圾)] / P(X) (贝叶斯定理)
- 生成式AI:直接建模P(X,Y),或通过自回归(如GPT的“逐词预测”)逼近P(X)
2.2 训练目标:从“分类正确”到“生成逼真”
判别模型的训练目标是“最小化分类错误率”,比如让垃圾邮件分类器的准确率达到99%。而生成式AI的训练目标是“让生成的样本与真实数据难以区分”,常用指标是“困惑度(Perplexity)”或“FID分数(图像生成)”。以扩散模型为例,它通过“正向加噪-反向去噪”的过程,让模型学会从随机噪声中生成与训练数据分布一致的样本。
2.3 输出控制:从“被动响应”到“主动创造”
判别模型的输出完全由输入决定——输入相同,输出必然相同。而生成式AI具备“随机性”和“创造性”:即使输入相同的提示词(Prompt),每次生成的结果也可能不同。比如用Stable Diffusion输入“一只戴帽子的猫”,你可能得到戴礼帽的猫、戴棒球帽的猫,甚至戴墨镜的猫——这种“可控的随机性”正是生成式AI的核心价值。
三、应用场景对比:大模型是万能钥匙吗?
明确了技术差异,再看实际应用场景。很多企业误以为“买了大模型就能解决所有问题”,但现实是:大模型≠生成式AI的“万能解药”,而判别模型在某些场景下仍不可替代。
3.1 生成式AI的“舒适区”:需要创造力的场景
生成式AI擅长处理“无明确规则、需要创新”的任务,典型场景包括:
- 内容创作:AIGC文案(如电商商品描述)、AI绘画(如MidJourney)、代码生成(如GitHub Copilot)
- 模拟与预测:药物分子设计(如Insilico Medicine用生成模型加速新药研发)、气候模拟
- 对话交互:智能客服(需生成符合语境的回答)、虚拟人对话(需保持角色一致性)
举个具体案例:某游戏公司用生成式AI设计NPC对话,传统方法需要编剧团队编写数千条对话模板,而生成式AI能根据角色设定和剧情进度,实时生成符合性格的对话,效率提升10倍以上
3.2 判别模型的“不可替代性”:需要精准决策的场景
判别模型在“有明确规则、需要高准确性”的任务中仍占优势,比如:
- 风险评估:金融风控(判断用户是否违约)、医疗诊断(判断患者是否患病)
- 信息过滤:垃圾邮件分类、敏感内容审核
- 结构化数据预测:房价预测(输入面积、地段等,输出价格)、销量预测
Forrester 2025年Q2的研究显示,在需要“低错误率+可解释性”的场景中(如医疗诊断),判别模型(如XGBoost)的表现仍优于生成式AI——因为生成式AI的“创造性”可能导致不可预测的输出,而判别模型的决策过程更透明。
3.3 大模型的“双刃剑”:何时需要,何时不需要?
大模型并非所有生成式任务的必选项。根据阿里云2025年3月发布的《企业AI大模型选型指南》,企业选择大模型需满足三个条件:
- 任务复杂度高:需要处理长文本、多模态或跨领域知识(如法律文书生成)
- 数据量充足:训练数据超过10万条(否则小模型可能更高效)
- 算力资源允许:单次推理成本可接受(千亿参数模型每秒推理成本约0.1美元)
反之,如果任务简单(如短文本分类)、数据量小(如垂直领域的1000条标注数据),使用轻量级判别模型或小生成模型(如参数量小于10亿的LLaMA-7B微调版)反而更经济。
模型选择决策树
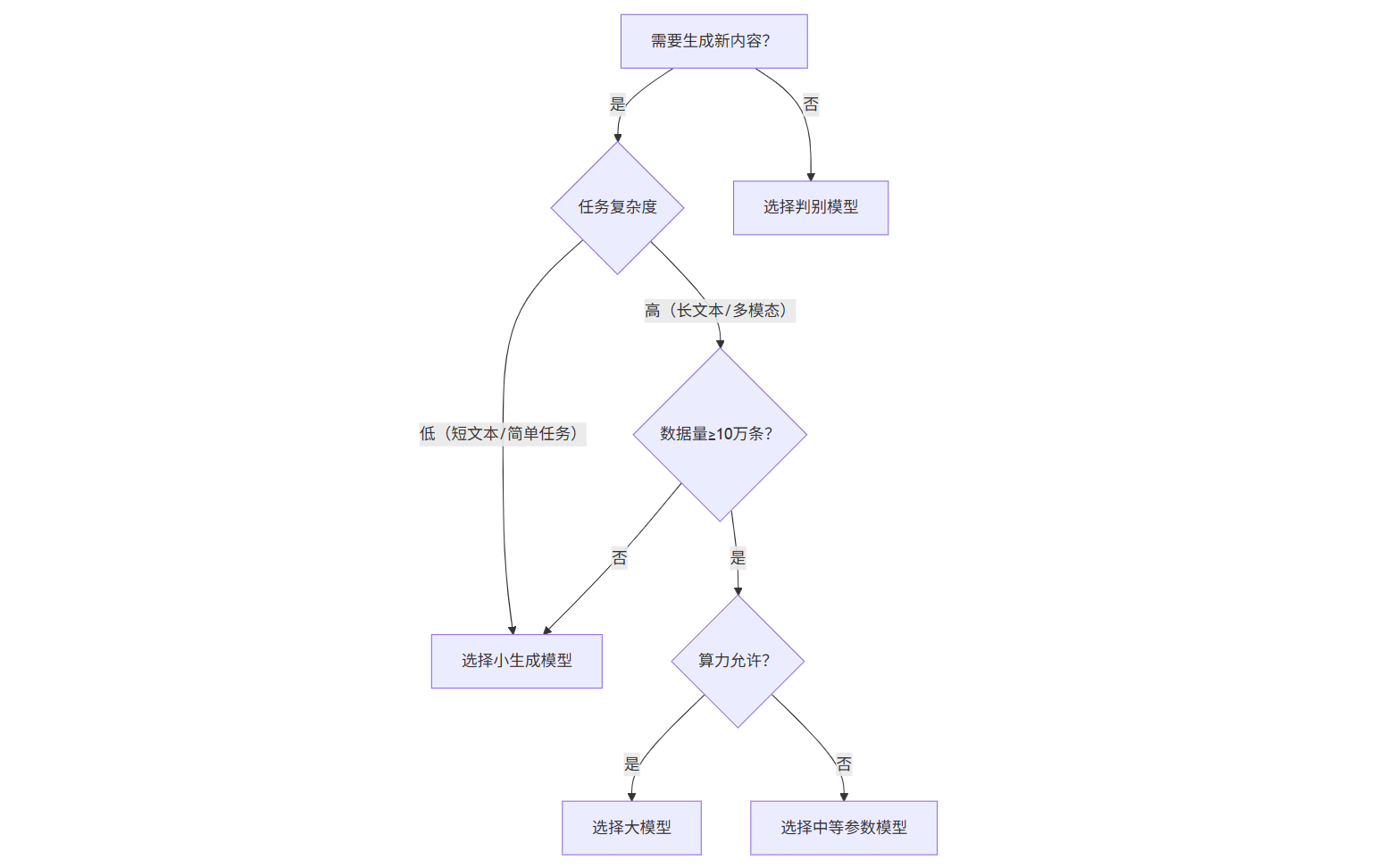
注:决策树帮助企业快速判断模型类型,避免盲目选择**大模型
四、训练逻辑大起底:数据、算力与目标的三角博弈
技术路径的差异,最终体现在训练逻辑上。三者的训练逻辑可以概括为“数据需求-算力消耗-目标导向”的不同组合,这也是理解它们本质区别的关键。
4.1 数据:“海量无标注” vs “精准标注”
生成式AI(尤其是基于自监督学习的大模型)依赖海量无标注数据。比如GPT-3.5的训练数据包含45TB的文本(书籍、网页、文章等),这些数据无需人工标注,模型通过“预测下一个词”的方式自我学习。而判别模型(如BERT的微调版)则需要大量标注数据——比如训练一个情感分类模型,需要至少1万条标注了“积极/消极”的文本数据。
4.2 算力:“暴力堆算力” vs “精准调参”
大模型的训练需要惊人的算力。以PaLM 2为例,训练时动用了6144张A100 GPU,耗时约2个月,总算力成本超过2000万美元。而判别模型的训练算力需求低得多——即使是BERT-base的微调,使用8张V100 GPU也只需几天时间。
4.3 目标:“泛化能力” vs “任务特定性能”
大模型的核心目标是提升“泛化能力”——让模型在未见过的任务上也能表现良好(比如用对话训练的大模型直接做文本摘要)。而判别模型的目标是“任务特定性能最大化”——针对某个具体任务(如垃圾邮件分类),通过调参让准确率达到99%以上。
五、行业误区的典型表现及避坑指南
最后,我们来看看实际业务中最常见的三大误区,以及如何避免。
5.1 误区一:“大模型=生成式AI,买大模型就能做生成”
典型表现:某企业采购了千亿参数大模型,试图用它做商品图生成,结果生成的图片模糊、不符合要求,投入的500万预算打了水漂。 避坑指南:生成式AI需要“大模型+生成算法+任务适配”的组合。比如商品图生成,除了大模型(如Stable Diffusion XL),还需要微调数据集(包含商品类别、风格标签)和提示词工程(指导模型生成方向)。
5.2 误区二:“判别模型过时了,全部替换成生成式AI”
典型表现:某银行用生成式AI替代原有的风控判别模型,结果因生成式AI偶尔输出“高风险用户低风险”的错误判断,导致坏账率上升30%。 避坑指南:判别模型在“需要高确定性”的场景中仍不可替代。正确的做法是“混合架构”——用生成式AI生成候选方案,用判别模型做最终决策(比如风控场景中,生成式AI列出10个高风险用户,判别模型再逐一验证)。
5.3 误区三:“参数越大越好,盲目追求千亿级大模型”
典型表现:某创业公司为了融资,采购了千亿参数大模型,但因训练数据不足(仅1万条),模型输出重复、逻辑混乱,用户体验极差。 避坑指南:根据任务复杂度选择模型规模。参考腾讯云的《大模型选型 Checklist》:
- 简单任务(如短文本分类):小模型
- 中等任务(如长文本摘要):中模型
- 复杂任务(如跨模态生成):大模型
总结:三者关系好比“食材、厨具与菜系”
如果把AI技术比作烹饪,判别模型是“精准的菜谱执行者”——你给它食材(数据)和步骤(算法),它能做出一道符合标准的菜(输出标签);大模型是“能自创菜式的米其林主厨”——它不仅能按菜谱做,还能根据食材特点发明新菜(生成新内容);而生成式AI则是“融合创意与执行的现代烹饪体系”——它既需要主厨的创造力(大模型的生成能力),也需要遵循基本的烹饪原理(判别模型的决策逻辑)。
下次再听到有人说“生成式AI就是大模型”,你可以笑着纠正:“大模型是生成式AI的工具,而判别模型是它的‘隐形助手’——少了谁,这场AI盛宴都做不精彩。”


最新发布

热门推荐



