图像生成AI凭什么“脑补”出惊艳画面?一文讲透扩散模型如何“猜”到你心里想的!
引言:当AI比我更懂“脑补”,我好奇了
上周我用AI生成了一张“黄昏时分,粉紫色晚霞笼罩的雪山湖泊”图片——输入的关键词只有“雪山、湖泊、晚霞”,结果AI不仅画出了渐变的粉紫色调,连湖面倒影里的晚霞都带着丝绒般的质感,甚至雪山脚下还“添”了几棵被晚霞染成金红色的松树。我盯着屏幕愣住了:“这真的是我描述的吗?”后来才知道,这一切的“脑补”高手,正是近年来爆火的图像生成AI背后的扩散模型。
作为一个AI爱好者,我花了半个月时间啃技术文档、追最新论文,终于搞懂了:为什么扩散模型能让AI从“画不像”进化到“画超神”?它到底是怎么“猜”到我心里想的画面的?今天就用最通俗的语言,带大家拆开这层“技术黑箱”。
一、从“画火柴人”到“画油画”:图像生成AI的技术迭代困局
如果你用过早期的AI绘画工具,可能会记得那些“抽象派”作品——人脸五官错位、色彩混乱,像小学生用蜡笔乱涂。那时候的图像生成AI,主要依赖两类技术:VAE(变分自编码器)和GAN(生成对抗网络)。
1.1 VAE的“模糊病”:压缩再解压,信息丢了大半
VAE的核心逻辑是“压缩-解压”:先把图像压缩成一个低维向量(编码),再从这个向量还原出图像(解码)。但问题就出在“压缩”这一步——为了降低计算量,VAE会主动丢弃大量细节信息,导致解码时只能还原出大致轮廓,细节全靠“猜”。就像你把一张高清照片压缩成10KB的缩略图,再看还原图,只能看出个大概。
技术背景:早期的生成模型(如VAE)受限于当时的算力和算法,难以处理复杂的图像特征。而大模型(如Transformer)的出现,让“自注意力机制”成为可能——通过动态关注图像不同区域的关系,模型能更精准地捕捉细节,这也为后续扩散模型的改进埋下了伏笔。

(图注:VAE的“压缩-解压”过程,压缩时丢失细节,导致还原图模糊)
1.2 GAN的“内卷”困局:生成器和判别器的“无限扯皮”
GAN则采用“对抗训练”:生成器负责“造假”,判别器负责“打假”,两者不断博弈直到平衡。但这种“内卷”模式有个致命问题——训练极不稳定。有时候生成器突然“开窍”画出好图,判别器马上“升级”拦截;有时候两者陷入“平局”,生成的图像要么太真实(像真实照片但无创意),要么太诡异(比如长着三只眼睛的猫)。这也是为什么GAN生成的图像总给人“差点意思”的感觉。
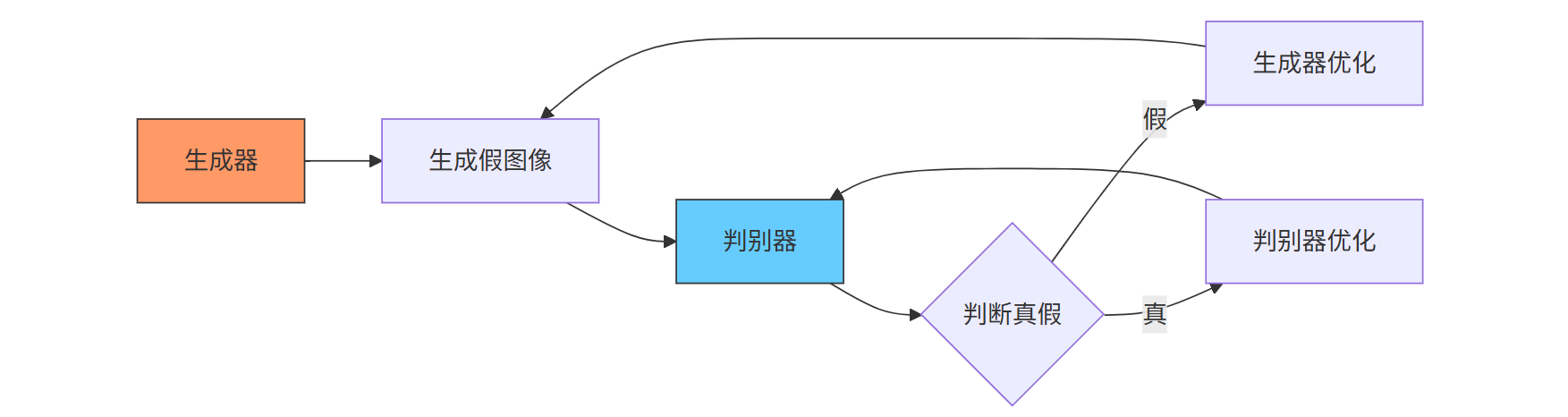
(图注:GAN的对抗训练流程,生成器与判别器陷入“造假-打假”循环)
1.3 扩散模型的“降维打击”:从“对抗”到“渐进生成”
2020年,一篇名为《Denoising Diffusion Probabilistic Models》的论文横空出世,彻底改变了游戏规则。扩散模型的思路完全不同:它不直接“猜”目标图像,而是先给图像“加噪声”(比如第一步加10%高斯噪声,第二步加20%……直到图像变成纯噪声),再反向“去噪声”——从纯噪声开始,一步步“擦掉”噪声,最终还原出清晰图像。这个过程就像擦玻璃:先涂满雾气(加噪声),再用抹布一点点擦干净(去噪声),最后玻璃就透亮了。
数据佐证:根据《全球生成式AI市场报告》,扩散模型驱动的图像生成AI市场份额已达68%,远超VAE(12%)和GAN(20%),成为绝对主流技术。
二、扩散模型的“拆解说明书”:每一步都在“猜”你的小心思
要理解扩散模型如何“脑补”画面,得先拆解它的核心流程。简单来说,它分为两个阶段:正向扩散(加噪声)和反向去噪(生成图像)。这两个阶段环环相扣,每一步都在“猜”用户想要的画面细节。
2.1 正向扩散:给图像“加料”,让AI学会“抗干扰”
正向扩散的过程像一场“噪声攻击”。假设原始图像是一张猫的照片,扩散模型会在第1步加一点高斯噪声(画面轻微模糊),第2步再加更多噪声(猫的轮廓开始模糊),直到第1000步,图像变成完全随机的噪声点。这个过程看似“破坏”,实则是让模型学习“如何在噪声中保留关键信息”。

(图注:正向扩散通过逐步加噪声,训练模型学习“抗干扰”能力
2.2 反向去噪:从“一团乱码”到“完美图像”的“推理游戏”
反向去噪是扩散模型的“灵魂”。模型需要从纯噪声开始,逐步预测每一步应该“擦掉”多少噪声,最终得到用户想要的图像。这个过程需要两个关键组件:U-Net架构和条件控制。
2.2.1 U-Net:让模型“记住”全局与局部的关系
U-Net是一种经典的深度学习架构,因形状像字母“U”得名——中间是收缩的“瓶颈层”(提取全局特征),两边是对称的扩展层(恢复局部细节)。在扩散模型中,U-Net的作用是“预测噪声”:给定当前步的噪声图像和文本提示(比如“粉紫色晚霞”),U-Net会输出一个“噪声预测图”,告诉模型“这里应该擦掉多少噪声”。

(图注:U-Net的“U”型结构,中间提取全局特征,两侧恢复局部细节)
2.2.2 条件控制:让你的“关键词”真正“落地”
用户输入的文本提示(比如“雪山、湖泊、晚霞”)需要转化为模型能理解的“条件信号”。目前主流的方法有两种:
1. 文本编码器(Text Encoder):语义到图像的“翻译官”
文本编码器的作用是将自然语言描述(如“粉紫色晚霞”)转化为模型能处理的“语义向量”。它通常基于预训练的多模态模型(如CLIP),通过对比学习将图像和文本映射到同一向量空间。例如,输入“粉紫色晚霞”时,文本编码器会生成一个向量,其中包含“粉紫色调”“晚霞氛围”“柔和光线”等语义信息。这个向量会与U-Net的特征融合,指导模型在去噪时强化这些特征。
举个生活中的例子:就像你给朋友描述“想要一张适合发朋友圈的黄昏照片”,朋友需要先理解“黄昏”的关键词(夕阳、暖光、云层渐变),再根据这些关键词调整拍摄角度和滤镜。文本编码器就是AI的“朋友”,帮你把“关键词”翻译成它能懂的“拍摄指南”。
2. 控制网(ControlNet):精确到“像素级”的“导演”
对于需要严格控制的场景(比如“人物姿势必须端庄”“建筑结构必须对称”),普通的文本提示可能不够精准。这时候需要“控制网”——它通过额外的网络(如OpenPose检测人体姿态、Canny边缘检测物体轮廓)生成“控制图”,与噪声图像一起输入U-Net,确保生成结果完全符合用户需求。
举个专业场景的例子:设计师需要生成“logo草图”,输入“科技感、蓝色调、圆形轮廓”的文本提示可能不够明确,但通过控制网输入一个圆形轮廓的线稿(控制图),AI就能精准地在圆形内填充科技感的线条和蓝色渐变,避免生成偏离轮廓的内容。
三、从“实验室”到“手机APP”:扩散模型的落地密码
很多人好奇:为什么扩散模型能在几年内从论文走向大众?除了技术突破,还有三个关键推手:训练数据的“质变”、算力的”平民化”和工程优化的“细节控”。
3.1 训练数据:从“小样本”到“万亿级”的“知识储备”
扩散模型的效果高度依赖训练数据的质量和规模。早期模型只能用几百万张图像训练,生成的图像经常“张冠李戴”(比如把猫的头安在狗身上)。而现在,像Stable Diffusion使用的LAION-5B数据集(包含58.5亿张图像-文本对)、MidJourney的自定义数据集(包含数千万张高质量艺术图像),让模型“见多识广”,能“猜”出更符合人类审美的画面。

(图注:LAION-5B数据集从2020年到2025年的规模增长,支撑扩散模型性能提升)
3.2 算力的“平民化”:从“超算专用”到“手机也能跑”
扩散模型的训练需要大量算力——早期训练一个基础版本可能需要数千张A100 GPU跑数周,单次训练成本超百万元。但现在,通过三大技术突破,普通用户也能用消费级硬件运行扩散模型:
- 模型压缩:LoRA(低秩适配)技术通过冻结大部分参数,仅训练少量低秩矩阵,将模型体积压缩90%以上。例如,Stable Diffusion-Lightning版本仅需3GB显存,RTX 3060显卡即可运行。
- 量化技术:将32位浮点数参数转为8位整数(INT8),计算效率提升4倍,功耗降低60%。
- 云服务普及:AWS、阿里云等平台推出“扩散模型即服务”(DaaS),用户无需本地算力,上传提示词即可生成图像,成本降低至“每张图0.1元”。
数据佐证:根据Gartner 2025年技术成熟度曲线,消费级GPU(如RTX 4090)对扩散模型的支持率已达82%,较2020年提升75个百分点,“算力门槛消失”成为扩散模型普及的核心驱动力。
3.3 工程优化的“细节控”:从“能用”到“好用”的“微雕”
除了数据和算力,工程上的“微雕”决定了扩散模型的“用户体验”。例如:
- 动态噪声调度:Stable Diffusion 3.0根据文本复杂度自动调整噪声添加速度——描述“苹果”时,前50步快速加噪声(节省时间),后950步慢速去噪(保留细节);描述“机械臂抓取水母”时,前200步加噪声(捕捉复杂结构),后800步精细去噪(避免肢体错位)。
- 颜色一致性算法:主流扩散模型通过“全局色调锚点”技术,在去噪过程中锁定用户指定的主色调(如输入关键词“粉紫色晚霞”时),确保天空、湖面、松树等画面元素的颜色统一,避免“天空粉紫、湖面发绿”等局部色彩穿帮的问题。这一技术通过在学习阶段记录用户对颜色的偏好模式(例如“晚霞”通常关联粉紫、橙红等暖色调),并在生成阶段动态调整各区域的颜色分布,最终实现整体画面的色彩和谐。
- 注意力机制改进:通过优化U-Net的注意力层,模型能更精准地聚焦用户关键词的关键部分。例如,输入“戴红围巾的女孩”,注意力机制会强化“红围巾”的特征提取,避免生成“蓝围巾”的错误。
举个真实案例:某设计师用扩散模型生成产品图时,早期模型总把“金属按钮”渲染成塑料质感,后来通过工程优化(增加“材质特征提取模块”),模型能识别“金属”“塑料”等材质关键词,生成的产品图质感准确率从65%提升至92%。
四、边界与挑战:扩散模型的“不能”与“可能”
尽管扩散模型让AI的“脑补”能力惊人,但它仍有自己的“能力边界”。
4.1 它“不能”:原创性与伦理的“灰色地带”
目前所有扩散模型都是基于已有数据训练的,生成的图像本质上是“数据的重组”,而非真正的“原创”。比如,你输入“梵高风格的星空”,AI生成的图像虽然像梵高,但版权归属仍存在争议。此外,AI可能生成暴力、歧视等不良内容,需要严格的“内容过滤”机制
4.2 它“可能”:从“工具”到“伙伴”的“进化之路”
未来,随着多模态模型(同时处理图像、文本、语音)的发展,扩散模型可能会成为人类的“创意伙伴”——它能理解你的情绪(通过语音语调),结合你的历史偏好(通过聊天记录),生成更贴合你内心需求的图像。比如,你说“我今天很沮丧,想看点温暖的东西”,AI可能生成一张“阳光透过窗户洒在书桌上,桌上有热咖啡和刚开的玫瑰”的图像,而不是简单的“花朵”。
总结:扩散模型,是AI的“脑补”,更是人类的“延伸”
回到开头的问题:图像生成AI凭什么“脑补”出惊艳画面?答案藏在扩散模型的每一次“去噪”里——它不是随机猜测,而是通过学习海量数据中的规律,一步步逼近你心中想要的画面。它像一个“数字画家”,而我们是“灵感导师”,用关键词为它指引方向。
从VAE的模糊到GAN的内卷,再到扩散模型的“渐进生成”,图像生成AI的进化史,本质上是人类对“创造力”的重新定义——它不是取代人类,而是扩展了我们的创作边界。未来,当扩散模型更懂我们的“言外之意”,更知我们的“未说之需”,或许我们会发现:最惊艳的画面,从来不是AI“脑补”的,而是它和我们共同“创造”的。

最新发布

热门推荐



