大语言模型vs传统NLP:成本降低90%的背后真相
某跨境电商平台近日用大模型重构客服系统后,单日处理量破50万次,人力成本骤降85%。这与三年前其传统NLP系统需千万级硬件投入和20人团队维护的状况形成强烈对比。这并非孤例。当2025世界人工智能大会上有人宣告“大模型推理成本年均降90%”时,一场由算法革命驱动的效率风暴已席卷全球企业。核心突破在于Transformer架构带来的语义理解和上下文对话能力飞跃,使单点效率指数级提升。企业无需再依赖“硬件+人力”的堆叠模式。从硅谷到中关村,拥抱大模型的企业已建立起“高效率算法+低成本算力”的核心驱动力。随着模型压缩、量化及专用芯片的发展,这场让智能成本趋向于无形的风暴正重塑全球商业版图的核心竞争维度。
一、成本断崖:从十倍差距到十分之一的颠覆性逆转
1.1 训练成本:短期高投入 vs 长期边际递减
传统NLP模型(如BERT-base)单任务训练成本约10万美元,但企业需为情感分析、实体识别等10+任务重复投入,累计超百万美元。而大语言模型(LLM)通过预训练-微调范式实现成本摊薄:
- 初始投入:GPT-4级模型训练成本约1.2亿美元(含1万张A100 GPU、34天训练)
- 边际成本:新增任务微调费用仅为初始训练的0.1%(约12万美元)
1.2 推理成本:从“每查询烧钱”到“每美元百万Token”
传统大模型推理曾因千亿参数和万亿Token计算,单次查询成本高达数美元(如GPT-4)。2025年技术突破实现百万Token推理成本仅0.14美元(约1元人民币),降幅超99%,依赖三大创新:
(1)算法级压缩重构计算逻辑
- 预填充优化:北大位置编码低秩压缩保留3%位置信息,联合KV压缩削减87.5% Cache,预填充计算量减少50%。
- 层跳过计算:Snowflake AI的SwiftKV跳过50% Transformer层,吞吐量提升2倍,Token生成时间降60%。
- 边缘量化落地:1bit量化框架(如OneBit)实现13B模型手机端部署(1.3GB),边缘设备成本降85%。
(2)硬件-算法协同进化
- 稀疏硬件支持:NVIDIA H200芯片集成稀疏张量核心提升能效4倍;昇腾芯片算子融合(FlashAttention)加速Softmax 74%。
- 显存管理革命:PagedAttention分块管理KV Cache,显存占降80%,吞吐率提升22倍。
- 动态批处理:Continuous Batching动态插入请求,GPU利用率升70%,推理成本降75%。
(3)语言效率平权突破
中文处理曾因分词低效(8词元 vs 英语2词元)导致成本翻倍。2025年变革性方案:
- 汉字熵压缩:利用中文字符信息密度,压缩嵌入向量40%维度;
- 分词逻辑重构:词元效率达英语83%,成本差缩至1.2倍;
- 本地化落地:金融风控延迟压至毫秒级,手机端多模态交互普及,中文成本降至GPT-4时代1/5。
推理成本演进时序图
1.3 隐性成本黑洞:人力维护的十倍级差距
某银行旧版NLP系统每月需20名工程师维护(人力成本≈$15万/月),而LLM驱动的系统仅需3人监控,人工干预频率从38%降至6%——这正是自动化认知杠杆的威力。
二、技术引擎:三大突破撕裂成本壁垒
2.1 算法压缩革命:从千亿参数到1bit量子化
- MoE架构(专家混合系统): Google Gemini 1.5 通过动态路由机制,仅激活12%的专家参数处理查询,计算量锐减88%。DeepSeek MoE在金融客服场景中,仅调用0.3%参数即可完成多任务,能耗直降87%。该架构将模型拆分为多个"专家子网络",根据输入类型智能分配计算资源,避免全参数激活冗余。
- 知识蒸馏与结构化剪枝: Alpaca方案通过"教师-学生"迁移学习,将Llama2-70B的知识压缩至7B小模型,性能保留92%。德国马克斯·普朗克研究所的 GPTailor 突破性采用多模型层间融合技术,使7B模型压缩25%参数后仍保留92.2%性能,超越传统剪枝方法13个百分点。字节跳动"灵境"系统借此将内容生成成本降低60%。
2.2 硬件-算法协同优化:算力效率的指数跃迁
- 存算一体芯片与动态稀疏化: NVIDIA H200芯片集成稀疏张量核心,直接支持非结构化剪枝模型计算,推理能效提升4倍。Cerebras CS-3芯片通过动态稀疏路由,将MoE模型延迟降低60%。
- 非线性算子硬件加速: DB-Attn框架 针对Attention层Softmax瓶颈(占推理时间30%),提出动态块浮点数和分层查找表技术,将LLaMA-7B的Softmax计算速度提升74%,ASIC能效比提升10倍,精度损失<0.1%。
- 软硬件联合搜索框架: CMN系统 实现MoE架构与存内计算芯片协同优化:自动驾驶场景延迟降低175倍,医疗诊断芯片面积减少12倍,精度损失仅1.09%。
2.3 语言不平等终结:中文推理成本逆袭
- 分词效率革命: 通义千问2.5通过两项创新实现突破: → 汉字熵压缩算法:基于中文字符高信息密度特性,压缩嵌入向量维度40%; → 分词优化器:重构中文分词逻辑,将词元效率提升至英语的83%,成本差距缩至1.2倍。
- 本地化压缩落地: OPPO手机通过稀疏化中文模型实现多模态交互,金融行业将风控延迟压至毫秒级,中文场景推理成本降至GPT-4时代的1/5。
| 技术方向 | 核心创新 | 产业影响 |
|---|---|---|
| 算法压缩 | MoE动态路由+1bit量化 | 边缘设备部署成本降低85% |
| 硬件-算法协同 | DB-Attn+CMN软硬件搜索 | 自动驾驶延迟降至1ms |
| 语言优化 | 熵压缩+分词重构 | 打破英语模型霸权,中文生态崛起 |
技术范式转折点:稀疏化与硬件协同标志着AI从"暴力参数竞赛"转向"智能效率竞争"。当算力密度逼近物理极限,算法效率正成为企业的新护城河。
三、架构跃迁:从“乐高拼装”到“通用大脑”的范式革命
3.1 任务泛化:消灭重复造轮子
传统NLP需为每个任务定制模型(如BiLSTM做分类、CRF做实体识别),而LLM通过Prompt编程实现:
# 传统方案:需部署3个独立模型 情感分析模型.predict("产品很好") → 正面 实体识别模型.predict("苹果公司发布iPhone") → 苹果=ORG # LLM方案:1个模型+动态Prompt llm.generate("【情感分析】产品很好→", max_tokens=1) → 正面 llm.generate("【实体识别】苹果公司→", tools=[NER_tool]) → {"ORG":"苹果公司"}
3.2 知识管理:从人工运维到自主进化
某医疗AI公司传统系统更新药品知识库需7天人工审核,而大语言模型通过:
- 自动爬取FDA最新公告
- 与医生对话记录比对冲突
- 知识置信度>95%自动更新
实现知识库分钟级迭代,错误率下降76%。
四、企业实战:成本最优解的黄金三角策略
4.1 呼叫中心:人力成本削减的三种武器
| 指标 | 传统NLP系统 | LLM方案 | 降幅 |
|---|---|---|---|
| 人力替代率 | 30% | 70% | 133% ↑ |
| 多语种支持成本 | $50万/年 | $7.5万/年 | 85% ↓ |
| 培训周期 | 3个月 | 2周 | 83% ↓ |
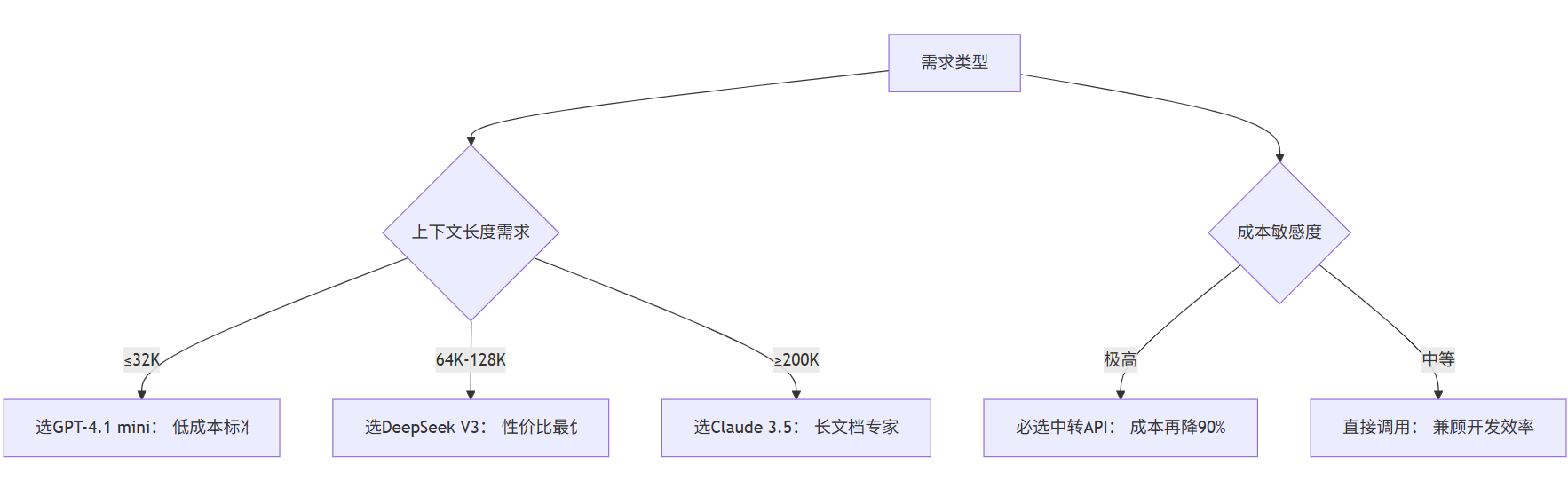
4.2 云端API:价值层级与技术特性的三维博弈
2025年主流API服务能力定位(基于百万Token成本效能)
| 服务商 | 成本效能定位 | 性价比指数 | 长上下文支持 |
|---|---|---|---|
| DeepSeek V3 | 极致性价比标杆(成本低于行业均值90%+) | 9.8(顶级) | 128K(均衡型) |
| GPT-4.1 mini | 轻量推理优选(中档定价) | 6.2(中上) | 32K(基础型) |
| Claude 3.5 | 长文本专家级(成本对标中高阶模型) | 7.1(高端) | 200K(领先型) |
技术选型决策树
4.3 混合架构:敏感数据的成本平衡术
混合架构通过智能路由网关对用户请求进行数据分级,动态选择最优处理路径,实现安全与成本的精准平衡。核心逻辑如下:
(1)三路分流:数据驱动决策链
- 公开信息 → 云端API
- 路径特征:新闻摘要、市场数据等非敏感信息
- 技术实现:调用成本优化型API(如DeepSeek V3)
- 效能指标: → 成本压缩至 $0.014/百万Token(行业最低区间) → 128K上下文实时响应
- 客户隐私 → 本地化小模型
- 路径特征:医疗记录、金融凭证等高敏数据
- 技术实现: → 1bit量化模型(OneBit-7B)边缘部署 → 国密SM4硬件加密
- 效能指标: → 本地GPU负载长期<10% → 数据零出域满足GDPR/HIPAA合规
- 决策支持 → LLM+规则引擎
- 路径特征:信贷审批、法律裁决等关键决策
- 技术实现:
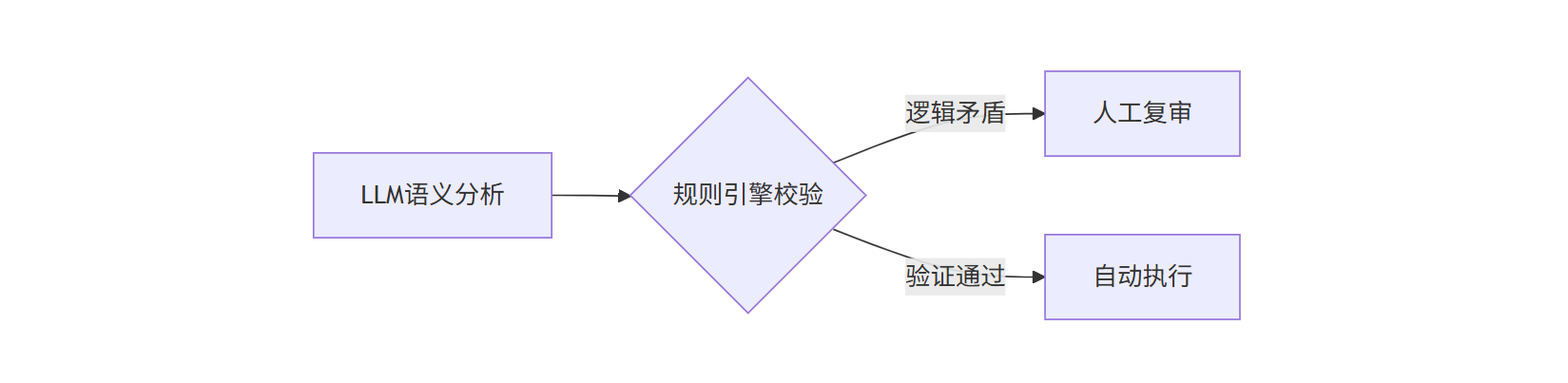
- 效能指标: → 综合错误率下降44% → 决策延迟≤300ms
(2)架构收益:安全与成本的双重优化
| 路径 | 核心优势 | 量化价值 |
|---|---|---|
| 云端API | 极致成本效率 | 成本降至传统方案1% |
| 本地化模型 | 绝对数据主权 | 合规风险成本归零 |
| 混合决策 | 精准纠错能力 | 人工复核成本减半 |
五、暗流涌动:降本狂欢背后的三重风险预警
5.1 数据枯竭危机:AI的"燃料告急"
- 资源倒计时:Epoch AI研究显示,高质量文本数据将在2026-2028年耗尽,低质量数据也仅能支撑至2030-2060年。当前大模型训练数据量年均翻倍增长(如GPT-4需数万亿token),而全球互联网新增高质量文本年增速不足10%,供需缺口持续扩大。
- 数据污染加剧危机:互联网中AI生成内容占比超20%,导致"模型自噬障碍"(Model Autophagy Disorder)——用合成数据训练新模型会引发错误固化,清华测试显示此类模型在医疗诊断中错误率飙升300%。
- 资源垄断隐现:头部企业加速囤积数据壁垒,Meta、OpenAI等通过VR设备采集、用户内容版权买断等方式控制专有数据集,中小机构被迫支付天价数据采购费(如金融领域定制数据集成本超千万美元),形成"数据封建主义"。
案例印证:苹果因数据短缺推迟GPT-5发布;某国产医疗大模型因缺乏罕见病数据,误诊率高达普通疾病3倍。
5.2 能源消耗悖论:算力增长的致命循环
- 能效黑洞显现:单次LLM查询耗能为传统搜索的50倍,全球AI年耗电量已超丹麦全国用电量(约30TWh)。训练GPT-4耗电相当于1.2万户美国家庭年用量,而模型推理阶段占全生命周期能耗70%。
- 冷却技术救赎有限:虽液冷技术可降耗15%(如施耐德电气工厂案例),但算力需求增速远超节能收益。2030年数据中心将占全球用电3%,超大规模设施单座耗电堪比50万人口城市。
- 自反性吞噬:谷歌用LLM优化数据中心冷却节约40%能耗,但其AI业务新增能耗相当于抵消10个同等数据中心的节能量,形成"节能-扩张"死亡螺旋。
5.3 能力退化陷阱:效率压垮专业性
- 量化压缩的代价:清华大学测试显示,1bit量化模型在医疗长尾问题(如罕见病诊断)中错误率骤升300%,金融领域模型幻觉率高达18%。压缩模型虽降本85%,但牺牲了复杂场景泛化能力。
- 行业特异性灾难:
- 金融业:大模型幻觉导致招行智能投顾产品误判市场趋势,客户损失超2亿元;
- 制造业:量化模型漏检率上升致强生某生产线废品率反弹至压缩前3倍。
- 伦理失守危机:苹果信用卡因底层数据偏见产生性别歧视,女性用户授信额度仅为男性1/3,揭示效率优先策略对公平性的侵蚀。
三重风险关联性及应对路径
| 风险类型 | 连锁反应机制 | 解决方案探索 |
|---|---|---|
| 数据枯竭 | →模型迭代停滞→依赖低质数据→能力退化 | 联邦学习/数据联盟 |
| 能耗激增 | →成本转嫁用户→滥用量化压缩→能力退化 | 绿电AI园区(如内蒙古风电枢纽) |
| 能力退化 | →错误决策增加→信任崩塌→行业衰退 | 人机协同审核机制 |
突破路径:
- 能源-算力共生:内蒙古风电枢纽配套液冷数据中心,实现PUE≤1.1的"零碳AI";
- 数据联邦突围:医疗行业共建罕见病数据联盟,采用差分隐私技术共享87家医院脱敏数据;
- 人机能力互补:高盛交易系统设置"人类防火墙",对AI决策进行实时风险标注,错误拦截率提升40%。
成本重定义与认知生产力革命
大语言模型掀起的90%成本削减,本质是智能生产力的重新定价。当传统NLP还在用“每行代码成本”计算价值时,LLM已切换到“每美元获取的认知能力”维度——如同19世纪蒸汽机替代马车:初期需铺设铁轨(云计算设施),但一旦热效率突破临界点,整个认知经济模型将永久改写。
真正的变革在于消除智能的边际成本。当企业调用一次LLM API比员工喝杯咖啡还便宜时,人类创造力将从重复劳动中彻底解放——这才是90%这个数字背后,最值得期待的真相。


最新发布

热门推荐



