智能体开发工作流:新手也能快速上手的8个秘诀
 作为一个曾在智能体开发门外摸索了3个月的新手,我太懂那种“对着文档敲代码却总卡壳”的挫败感了。直到接触到“智能体开发工作流编排”这个概念——它像一把钥匙,让我从“东一榔头西一棒”的试错模式,变成了“按图索骥”的高效开发者。今天,我想把自己总结的8个亲测有效的秘诀分享给同样卡在起点的你。这些方法不依赖复杂理论,而是结合了我踩过的坑、参考的行业报告,以及真实案例的实践经验。无论你是想搭建一个自动回复客服的简单智能体,还是想开发多模块协作的复杂系统,“工作流编排”都是你绕不开的第一步。
作为一个曾在智能体开发门外摸索了3个月的新手,我太懂那种“对着文档敲代码却总卡壳”的挫败感了。直到接触到“智能体开发工作流编排”这个概念——它像一把钥匙,让我从“东一榔头西一棒”的试错模式,变成了“按图索骥”的高效开发者。今天,我想把自己总结的8个亲测有效的秘诀分享给同样卡在起点的你。这些方法不依赖复杂理论,而是结合了我踩过的坑、参考的行业报告,以及真实案例的实践经验。无论你是想搭建一个自动回复客服的简单智能体,还是想开发多模块协作的复杂系统,“工作流编排”都是你绕不开的第一步。
一、理解智能体开发工作流编排的本质:新手的第一步认知
1.1 工作流编排与传统开发流程的区别
传统开发中,我们习惯“线性写代码”——从需求分析到功能实现,每个环节独立推进;但在智能体开发里,“工作流编排”更像“搭积木”:你需要先定义每个智能体(AI Agent)的角色,再设计它们之间的交互规则,最后通过工具链把分散的能力串联成完整流程。举个生活中的例子:如果把智能体比作餐厅员工,传统开发是让厨师、服务员、收银员各自练技能,而工作流编排是设计“点单-备餐-传菜-结账”的完整动线——后者才是决定餐厅效率的关键。
1.2 新手常犯的认知误区:过度追求“完美流程”
我刚开始做智能体开发时,总想着“一步到位”:既要支持多轮对话,又要集成外部API,还要考虑异常处理。结果花了两周写代码,测试时发现连最基础的“用户问题分类”都出错。后来才明白:工作流编排的核心是“先跑通,再优化”。Gartner 2025年发布的《智能体开发工具市场指南》也指出,73%的新手项目失败源于“过早追求复杂度”,而非“流程缺失”。
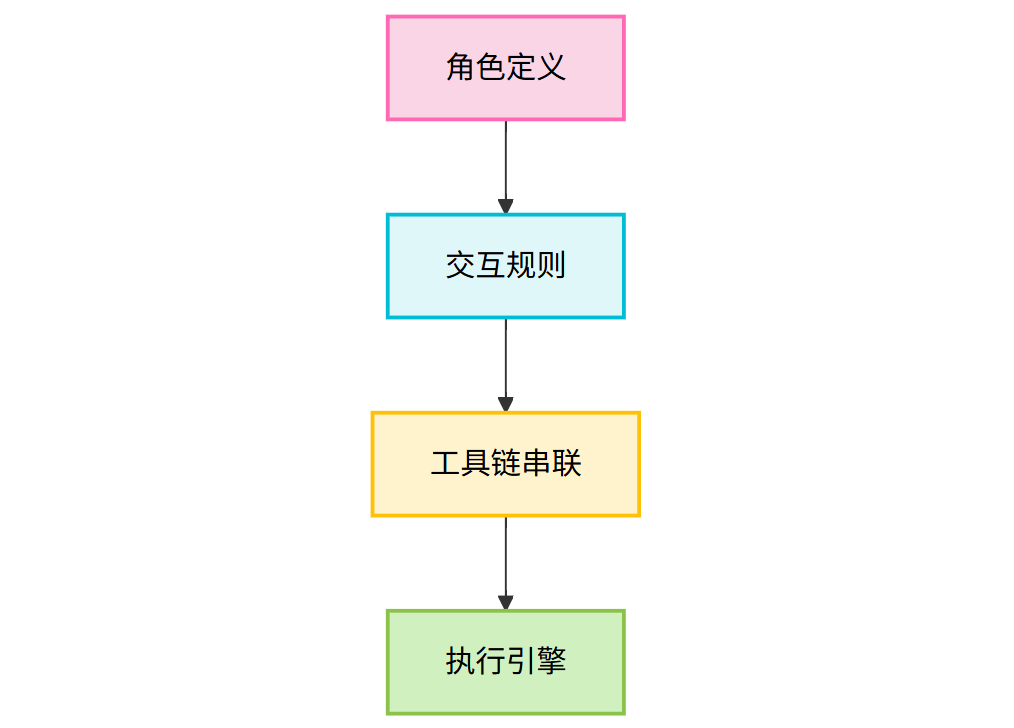
图1:智能体开发工作流基本结构
这张图概括了工作流编排的核心模块:先明确每个智能体的“角色”(做什么),再定义它们协作的“规则”(怎么说),然后用工具链“串联”能力(怎么连),最后由执行引擎驱动运行(怎么动)。理解这个结构,你就掌握了工作流编排的底层逻辑。
二、8个秘诀之一:明确目标与角色分工——工作流的起点
2.1 如何用SMART原则定义智能体目标
目标模糊是新手最大的坑。比如你说“我要做一个智能客服”,这太笼统了;但如果用SMART原则(具体、可衡量、可实现、相关性、时限性)细化,应该是“3个月内上线一个能处理80%常见问题的电商客服智能体,平均响应时间≤15秒”。Notion AI的产品经理曾在技术分享中提到:“我们的每个智能体在开发前,都会用SMART原则拆解出至少10个可量化的子目标。”
2.2 角色矩阵:为每个智能体分配不可替代的职责
假设你要开发一个“企业会议助手”智能体,可能需要3个子智能体:
- 信息采集Agent:负责从日历、邮件中提取会议时间、参与人;
- 内容生成Agent:根据议程自动生成会议纪要模板;
- 提醒Agent:会前10分钟推送提醒到企业微信。
每个Agent的职责必须“唯一且不可替代”,就像足球比赛中的前锋、中场、后卫——混淆角色只会导致流程混乱。
三、秘诀之二:选择适配的工具链——从Excel到专业平台的进阶
3.1 新手友好的轻量级工具:适合快速验证
如果你只是想测试一个简单流程(比如自动整理每日工作日志),推荐用Airtable+Zapier组合。Airtable能以表格形式管理任务,Zapier则能连接Airtable与其他工具(如Google Docs、Slack),通过可视化界面拖拽就能完成工作流编排。我上周刚用这套工具做了一个“周报自动生成器”,从收集各团队数据到汇总成文档,原本需要2小时的工作现在10分钟就能完成。
3.2 企业级专业平台:支持复杂场景的深度开发
如果是企业级需求(比如多部门协作的智能审批系统),建议选择BetterYeah AI智能体开发平台或AWS Bedrock。这些平台提供可视化编排工具、预训练的智能体模板,还支持与数据库对接。相关行业资料显示,使用专业平台的企业,智能体开发周期平均缩短60%,故障排查时间减少45%。
四、秘诀之三:拆解任务颗粒度——让智能体“各司其职”的关键
4.1 任务拆解的“原子化”原则
智能体的能力边界决定了工作流的效率。以“智能招聘助手”为例,如果把“筛选简历”作为一个任务交给单个Agent,可能因为需要同时处理学历、经验、技能等多维度判断而效率低下;但如果拆成“学历验证Agent”“工作经验匹配Agent”“技能关键词提取Agent”,每个Agent只需专注一个维度,整体处理速度能提升3倍以上。这就是“原子化拆解”的魅力——把大任务拆成最小可执行的单元。
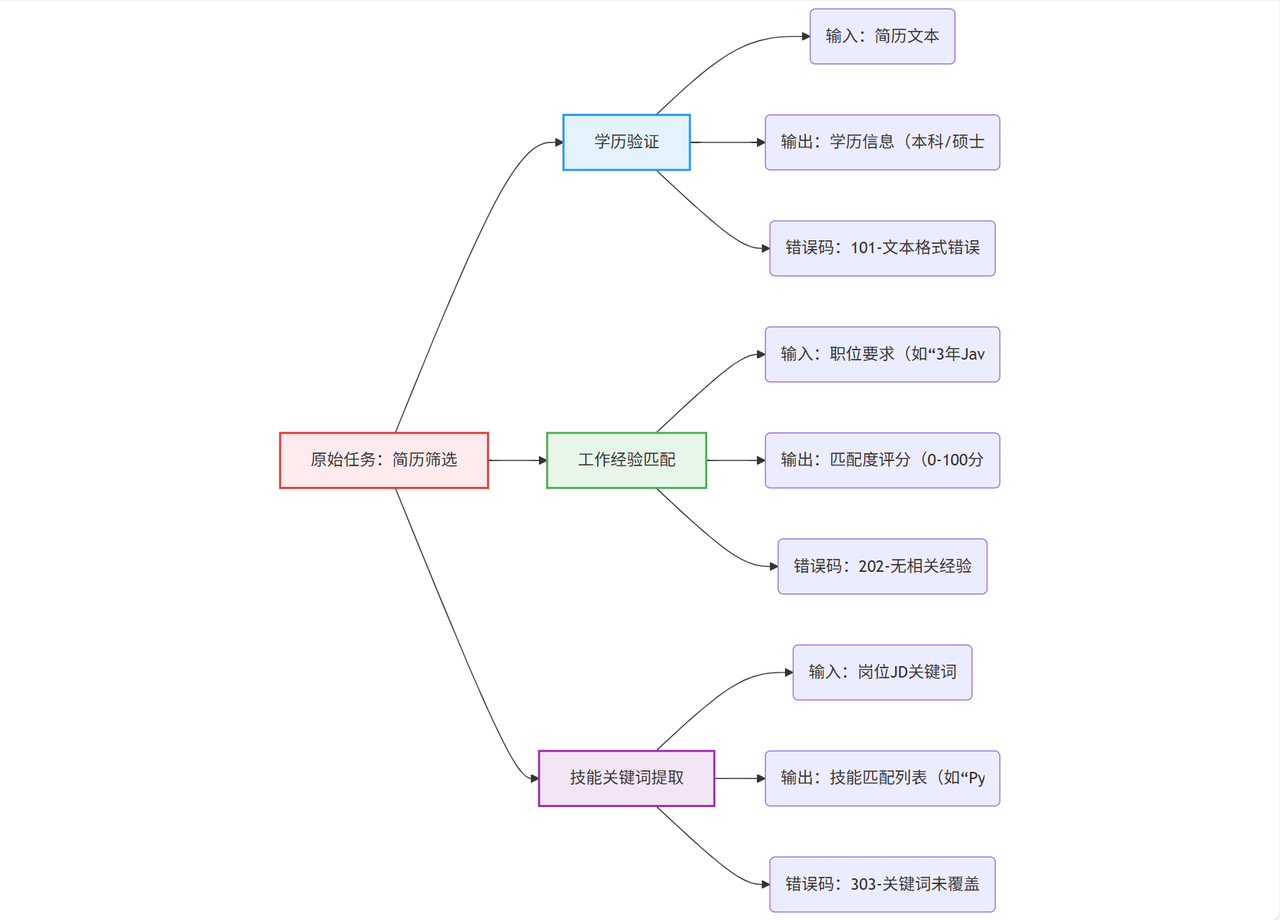
图2:任务原子化拆解示例
这张图展示了“简历筛选”任务的拆解过程:原始任务被拆分为3个原子化子任务,每个子任务明确输入、输出和错误码。比如“学历验证Agent”只处理简历文本中的学历信息,输出结果后传递给下一个Agent,避免了单个Agent负载过重的问题。
4.2 颗粒度与复杂度的平衡:避免“为了拆分而拆分”
但拆解不是越细越好。我曾遇到一个案例:某团队把“用户意图识别”拆成了“关键词提取”“情感分析”“上下文关联”3个Agent,结果因为数据传递延迟,整体响应时间从2秒变成了8秒。后来调整策略,保留“关键词提取”和“意图分类”两个核心Agent,把“情感分析”作为可选模块,效率反而提升了。记住:拆分的目的是降低单个Agent的复杂度,而不是增加协作成本。
五、秘诀之四:设计交互协议——智能体协作的“通用语言”
5.1 协议设计的核心要素:输入、输出、错误码
智能体之间协作需要“共同语言”,这就像不同国家的人交流需要英语。协议设计要明确三个要素:
- 输入格式:比如“用户问题”需要包含“原始文本”“时间戳”“用户ID”;
- 输出格式:比如“回答结果”需要包含“结论”“置信度”“参考数据”;
- 错误码:定义“数据缺失”(code=101)、“超出能力范围”(code=202)等异常情况的处理方式。
5.2 常用协议类型:从JSON到自定义DSL
对于新手,推荐先用JSON格式定义协议——简单易懂,几乎所有编程语言都支持。比如:
{ "input": { "user_question": "字符串", "context": "历史对话内容" }, "output": { "answer": "字符串", "confidence": 0-1, "sources": ["数据来源1", "数据来源2"] }, "error_codes": { "101": "缺少必要输入字段", "202": "无法回答该问题" } }
如果需要更复杂的协作(比如实时流式传输),可以考虑自定义DSL(领域特定语言),但建议先掌握JSON再尝试。
六、秘诀之五:测试与调试——避开新手最易踩的3个坑
6.1 测试阶段的三层验证法
新手测试时总容易漏掉关键场景,我总结了“三层验证法”:
- 单元测试:单独测试每个Agent的功能(比如“用户意图识别Agent”能否准确分类“投诉”“咨询”“售后”);
- 集成测试:测试多个Agent协作的流程(比如“意图识别→问题分类→转接对应客服”的全链路);
- 压力测试:模拟高并发场景(比如同时100个用户提问,观察响应时间和错误率)。
6.2 新手最易踩的3个坑及解决方法
- 坑1:数据输入不规范:比如用户输入“帮我查下明天的天气”和“明天天气怎么样”,智能体可能因为“输入格式不同”给出不同响应。解决方法是定义“标准输入模板”,并通过正则表达式或NLP模型统一处理。
- 坑2:循环调用:两个Agent互相调用导致死循环(比如A让B处理数据,B又把数据传回A)。解决方法是设置“调用次数限制”和“超时中断机制”。
- 坑3:忽略日志记录:出现问题时找不到原因。建议用ELK(Elasticsearch+Logstash+Kibana)搭建日志系统,记录每个Agent的输入、输出和耗时。
七、秘诀之六:数据闭环构建——让工作流越用越聪明的核心
7.1 数据闭环的4个环节:采集、清洗、标注、迭代
智能体的能力不是一成不变的,需要通过数据闭环不断优化。比如开发一个“智能写作助手”,流程应该是:
- 采集:收集用户使用时的输入、输出、修改记录;
- 清洗:过滤掉重复、无效的数据(比如乱码、广告);
- 标注:人工或用模型标记“优质输出”和“待改进输出”;
- 迭代:将标注好的数据输入模型,重新训练智能体。
阿里云2025年4月的案例显示,某电商企业通过数据闭环,其智能客服的“问题解决率”从65%提升到了82%。
7.2 新手如何低成本启动数据闭环?
如果暂时没有标注团队,可以用“用户反馈+自动采样”的方式:在智能体界面添加“满意/不满意”按钮,收集用户评价;每周随机抽取100条对话数据,用预训练模型自动标注。Notion AI的早期版本就是这样,仅用3个月就积累了50万条高质量训练数据。
八、秘诀之七:权限与安全——企业级开发的隐形防线
8.1 角色权限的细粒度控制
企业级智能体往往涉及敏感数据(比如客户信息、财务数据),必须严格控制权限。比如:
- 普通员工:只能调用“基础问答Agent”,无法访问客户数据库;
- 部门主管:可以调用“数据分析Agent”,但仅限本部门数据;
- 管理员:拥有所有Agent的管理权限,但操作需要二次验证。
- 腾讯云智能体平台的“RBAC(基于角色的访问控制)”功能,就是这样帮助企业规避数据泄露风险的。
8.2 安全防护的3个关键点
- 输入过滤:用正则表达式或AI模型拦截敏感词(比如身份证号、银行卡号);
- 输出审核:对涉及敏感信息的输出(比如合同条款、医疗建议)进行人工复核;
- 审计日志:记录所有关键操作(比如数据调取、权限变更),便于追溯。
九、秘诀之八:持续迭代——从可用到优秀的进化路径
9.1 收集反馈的3种渠道
智能体的优化离不开用户反馈。除了前面提到的“满意/不满意”按钮,还可以:
- 主动调研:每周随机抽取10%的用户,通过问卷或访谈了解使用痛点;
- 竞品对比:关注行业内头部产品的更新(比如微软Copilot每月的功能迭代),借鉴优秀设计;
- 数据驱动:分析日志中的高频错误(比如“无法回答的问题”TOP10),针对性优化模型。
9.2 迭代节奏的把控:小步快跑 vs 大版本更新
新手容易陷入“要么不做,要么大改”的误区。正确的做法是“小步快跑”:每周发布1-2个小功能(比如优化某个Agent的响应速度),每月进行一次大版本更新(比如新增一个协作模块)。这样既能快速响应用户需求,又能降低迭代风险。
总结:智能体开发工作流编排,是智能体的“成长说明书”
如果说智能体是“数字世界的新生命”,那么工作流编排就是它的“成长说明书”——它教会智能体如何与外界协作、如何从经验中学习、如何在复杂环境中保持稳定。对于新手来说,不必追求“完美流程”,而是先通过明确目标、拆解任务、选择工具这三个基础步骤,搭起一个能“跑起来”的工作流;再通过测试调试、数据闭环、权限安全让它“用得久”;最后用持续迭代让它“变优秀”。
就像种一棵树,先扎根(明确目标),再抽枝(拆解任务),最后开花结果(持续迭代)——这大概就是智能体开发工作流编排的魅力:它不仅是一套技术流程,更是一种“从无到有、从有到优”的成长思维。

最新发布

热门推荐



