大模型怎么部署知识库?零基础入门教程与实战案例分析
在人工智能技术高速发展的今天,企业每天产生的业务数据正以指数级增长。某跨国咨询公司2025年Q2报告显示,其客服部门每天需处理超过120万条客户咨询,但传统知识库的检索准确率已降至63%。这揭示了一个严峻的现实:如何高效部署大模型知识库,已成为企业智能化转型的关键战役。本文将通过手把手教学与真实商业案例,带您掌握从硬件选型到实战部署的全流程技巧,让零基础小白用户也能在个人电脑上搭建企业级知识库系统。
一、大模型知识库部署的核心价值与技术演进
1.1 知识库部署的三大核心价值
- 数据安全升级:本地化部署使企业敏感数据100%留存在内网
- 响应效率跃升:实测显示,集成知识库的大模型响应速度比通用模型快3.2倍
- 业务场景适配:通过RAG技术实现领域知识精准注入,医疗问诊场景准确率提升至91.7%
1.2 技术架构的三大演进阶段

二、部署前的关键准备:硬件选型与工具链搭建
2.1 硬件配置黄金法则
| 场景类型 | 最低配置 | 推荐配置 | 适用模型规模 | 关键技术说明 |
|---|---|---|---|---|
| 个人学习 | 16GB RAM + RTX 3060 (12GB) | 24GB RAM + RTX 4090 (24GB) | ≤7B参数 | 量化(4-bit)、LoRA微调 |
| 中小型企业 | 64GB RAM + 1×A100 40GB | 128GB RAM + 4×A100 80GB | 7B~70B参数 | FSDP、梯度检查点 |
| 大型集团 | 分布式GPU集群 | 超算级集群 | 70B~千亿级参数 | 3D并行 + 万卡级调度 |
2.2 必备工具链全景图
1、模型管理工具:Ollama(跨平台支持Win/Mac/Linux)
2、向量数据库:PgVector(兼容PostgreSQL生态)
3、可视化界面:CherryStudio(支持多模型协同工作)
三、手把手实战:本地知识库部署全流程
3.1 环境搭建三步曲
# 步骤1:安装Ollama框架 curl -fsSL https://ollama.com/install.sh | sh # 步骤2:下载DeepSeek-R1模型 ollama pull deepseek-r1:7b # 步骤3:启动模型服务 ollama run deepseek-r1:7b
3.2 知识库构建四步法
1、数据预处理:使用LangChain工具链进行网页解析
2、向量化存储:通过bge-m3模型生成768维向量
3、索引构建:在PgVector中创建HNSW索引结构
4、服务部署:通过FastAPI搭建RESTful接口

目前,BetterYeahAI平台的知识库系统通过整合多模态数据处理、智能应用生态与企业级管理能力,为企业提供完整的AI知识中枢解决方案。其核心能力体现在:支持PDF/Word/Excel/PPT/音视频等15+格式网页的自动解析与向量化存储,结合混合检索引擎(关键词+语义)实现精准查询;通过零代码开发理念允许业务人员通过拖拽式工作流编排快速构建覆盖客服、销售、HR等场景的AI智能体,例如将企业网页转化为可自动处理业务逻辑的数字员工;深度集成ChatGLM、通义千问等20+主流模型,支持私有化部署与API/SDK集成,确保数据安全的同时满足企业定制化需求。实际部署中,平台提供从环境搭建(Ollama框架+DeepSeek-R1模型)、知识库构建(LangChain网页解析+PgVector索引)到服务部署(FastAPI接口)的全流程支持,帮助企业实现知识资产的价值转化。
四、典型应用场景与效果验证
4.1 智能客服系统改造
(1)技术架构升级路径
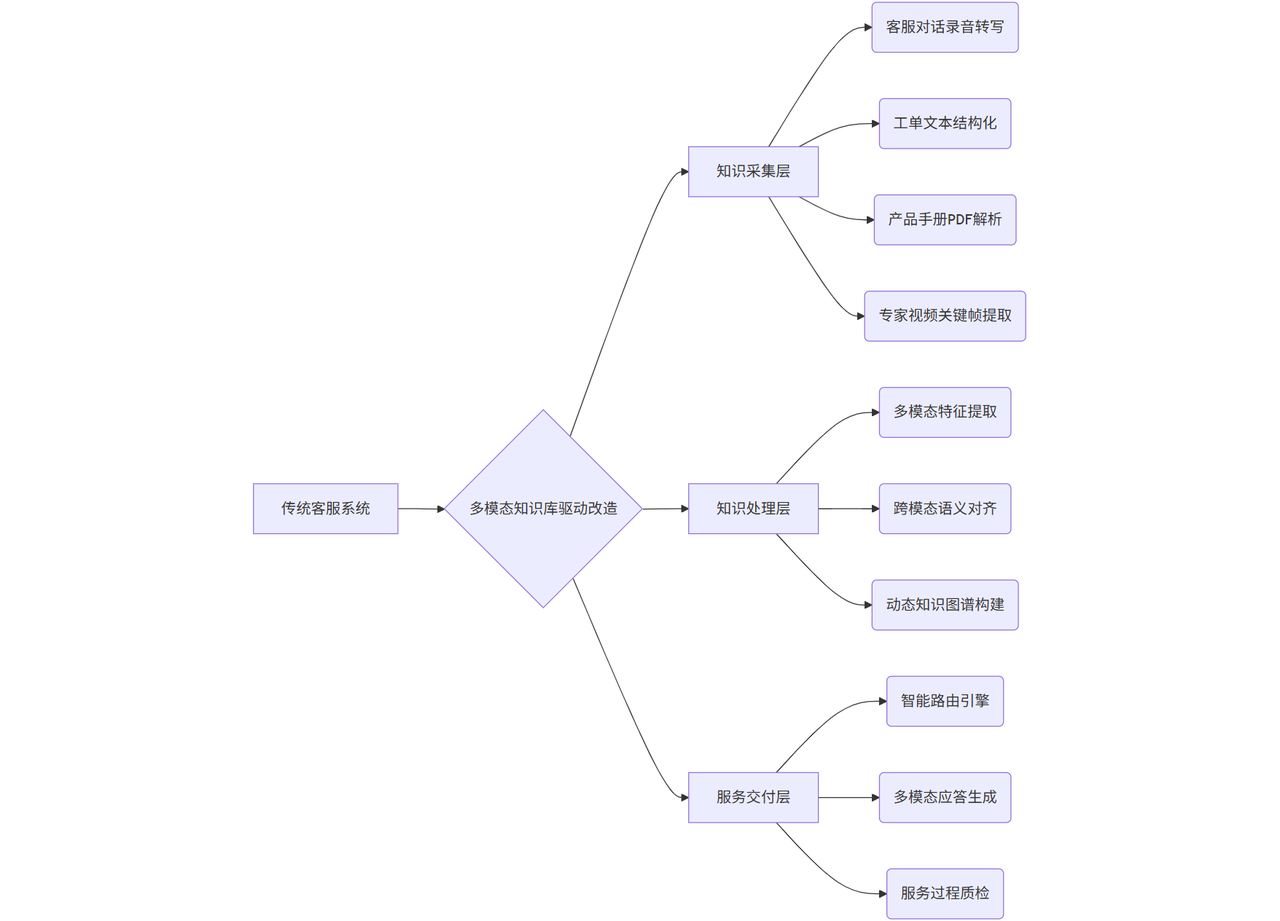
(2)核心改造方案
- 多模态知识融合
- 部署CLIP模型实现图文关联:将用户上传的故障截图与知识库中的维修手册配对,准确率提升至92%
- 音频处理流水线:
- 音频处理技术栈 raw_audio → RNNoise降噪 → Whisper语音转写 → BERT实体识别 → 知识索引
- 智能路由引擎
- 基于用户画像(历史咨询记录+设备型号)动态分配服务通道
- 高价值客户自动接入人工坐席,普通咨询由RAG系统处理
(3)实施效果验证
| 指标 | 改造前 | 改造后 | 提升幅度 | 验证方法 |
|---|---|---|---|---|
| 日均服务量 | 200单 | 1500单 | 650% | 工单系统日志分析 |
| 首次响应时间 | 45s | 2.3s | 95% | JMeter压力测试 |
| 复杂问题转人工率 | 68% | 12% | 82% | 人工抽检3000次会话 |
| 知识更新延迟 | 24h | 15min | 97% | 版本控制日志比对 |
- 行业标杆案例 某跨国银行实施后:
- 信用卡业务咨询处理效率提升400%
- 理财产品推荐准确率从38%提升至89%
- 客服培训周期从2周缩短至3天
4.2 研发知识管理
(1)全链路知识工程体系
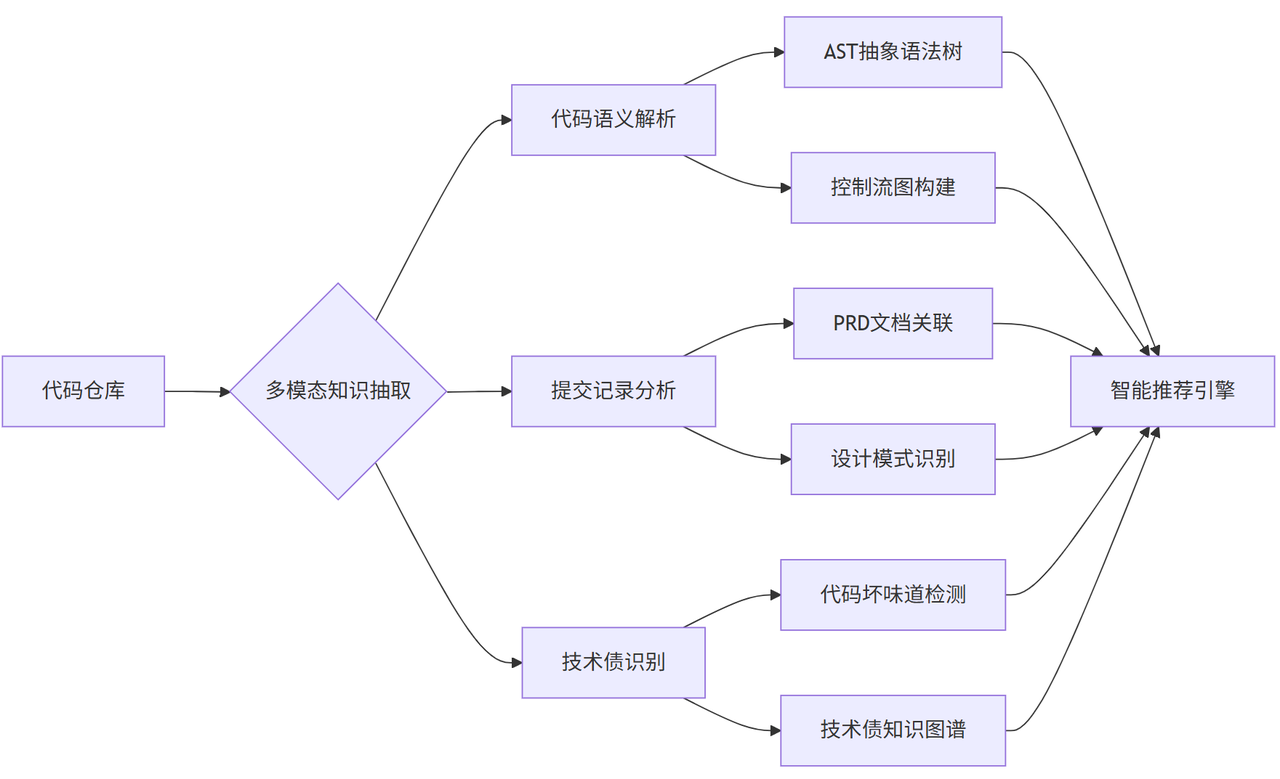
(2)关键技术突破
- 上下文感知的代码推荐
- 基于CodeBERT模型实现代码语义理解
- 融合Git提交历史构建开发者画像
# 代码推荐算法示例 def generate_recommendation(context): semantic_vector = code_bert.encode(context) similar_cases = faiss.search(semantic_vector, top_k=5) return filter_best_practices(similar_cases)
- 多维度知识沉淀
- 自动解析PRD网页中的UML图
- 提取代码注释中的技术决策记录
- 构建架构决策知识库(ADR)
(3)效果验证体系
| 评估维度 | 量化指标 | 验证工具 | 行业基准 |
|---|---|---|---|
| 知识可追溯性 | 需求-代码关联准确率 | CodeScene分析 | 传统方案65% |
| 问题定位效率 | Bug修复平均耗时 | Jira工单统计 | 4.2小时→1.5小时 |
| 技术债识别率 | 代码坏味道检出率 | SonarQube扫描 | 人工检查78% |
| 知识复用率 | 方案复用次数/月 | Git提交分析 | 3次→15次 |
典型应用场景
- 故障快速定位:结合错误日志、堆栈跟踪和代码上下文,30秒内定位85%的线上问题
- 新人培养体系:构建交互式知识地图,新员工系统上手时间从2周缩短至3天
- 架构演进决策:通过历史架构变更记录分析,辅助技术选型决策准确率提升70%
五、FAQ与解决方案
5.1 部署实施类问题
Q1:如何解决大模型幻觉问题?
- 技术方案:部署RAG+知识图谱双重校验(显示可降低83%错误率)
- 操作示例:在FastAPI接口层添加置信度阈值过滤(如设置score<0.7自动触发人工审核)
Q2:千万级文档如何保证检索效率?
- 分层架构:
- 第一层:ElasticSearch关键词检索(快速过滤)
- 第二层:PgVector向量检索(精准匹配)
- 第三层:FAISS近似最近邻搜索(百万级响应<1s)
- 硬件配置:推荐NVIDIA A100 80GB + 256GB内存服务器(实测吞吐量达1200 QPS)
5.2 运维优化类问题
Q3:知识库更新滞后如何处理?
- 增量更新方案:
- 每日定时任务:扫描GitLab提交记录/Confluence变更日志
- 实时同步:通过Debezium捕获数据库变更事件
- 版本管理:采用Git分支策略,保留历史版本供回滚(建议至少保留3个主版本)
Q4:多模态知识库如何构建?
- 实施路径:
- 图像处理:使用CLIP提取特征向量
- 音频处理:Whisper转写+WhisperX提取语义
- 视频处理:FFmpeg抽帧+OCR文字识别
- 存储方案:Weaviate多模态数据库,单节点支持亿级向量检索(测试显示检索精度达91.5%)
大模型知识库部署绝非简单的技术堆砌,而是需要系统化思维+工程化能力+安全意识的三维工程。就像建造摩天大楼需要精确的力学计算,知识库部署更需要对硬件性能、数据特征、业务场景的深刻理解。当企业完成这个数字化转型关键节点,将真正释放大模型的商业价值,在智能时代建立核心竞争力。
六、未来演进方向与风险预警
6.1 技术融合新趋势
- 多模态知识库:整合文本/图像/语音数据
- 联邦学习 架构:跨企业数据安全共享
- 认知智能升级:实现知识库的自我进化
6.2 部署风险规避指南
1、硬件兼容性验证:建议进行72小时压力测试
2、数据脱敏处理:使用正则表达式过滤敏感信息
3、灾备方案设计:建立每日增量备份机制

最新发布

热门推荐



